Statistics
Covariance, Correlation✔
Covariance✔
직선관계
-
양의 관계 : 두 변수에 대하여 한 변수가 증가할 때 다른 변수가 증가하고 한 변수가 감소할 때 다른 변수도 감소하는 관계이다.
-
음의 관계 : 두 변수에 대하여 한 변수가 증가할 때 다른 변수가 감소하고 한 변수가 감소할 때 다른 변수가 증가하는 관계이다.
공분산(covariance)
\(n\)개의 값을 갖는 확률변수 \(X, Y\) 와 \(X\) 의 평균 \(\mu _{x}\), \(Y\) 의 평균이 \(\mu _{y}\) 에 대하여 다음을 공분산이라 한다.
-
공분산은 두 데이터의 직선관계를 보여주는 값이다. 공분산으로 두 데이터의 상관관계를 조사 할 수 있다. 이때 단위가 전혀 다른 두 데이터에도 공분산을 구할 수 있다. 가령 신장과 체중의 상관관계를 조사할 때에도 공분산을 구할 수 있다.
공분산이 양수일 때 두 데이터가 양의 관계에 있고, 공분산이 음수일 때 두 데이터가 음의 관계에 있다. 하지만 공분산의 절댓값이 양의 관계나 음의 관계의 강도를 나타내지는 않는다. 관계의 강도는 상관계수로 비교할 수 있다.
독립적인 두 데이터의 공분산은 \(0\) 이다. \(0\) 이 아닌 공분산을 갖는 두 데이터는 종속적이다. 그러나 독립성과 공분산 \(0\) 이 동치는 아니다. 독립성은 공분산 \(0\) 보다 더 강한 개념이다. 공분산이 \(0\) 이지만 종속적인 데이터도 있기 때문이다. 가령 비선형 관계의 두 데이터는 종속적이지만 공분산 \(0\) 을 가질 수 있다.
-
다음과 같이 각각 양의 관계와 음의 관계를 보여주는 산점도를 생각하자.
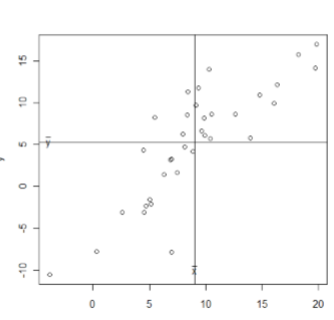
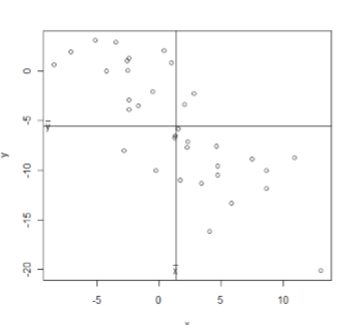
변수의 직선관계가 위치에 따라서 변함이 없어야 하므로 직선관계를 변수 \(x, y\) 의 평균 \(\mu _{x}, \mu _{y}\) 를 기준으로 판단해야 한다. 양의 직선관계를 나타내는 왼쪽 그래프에서 평균을 기준으로 데이터가 \(1\) 사분면과 \(3\) 사분면에 많고, 음의 직선관계를 나타내는 오른쪽 그래프에서 평균을 기준으로 데이터가 \(2\) 사분면과 \(4\) 사분면에 많다. 또한 평균 \(\mu _{x}, \mu _{y}\) 에서 멀어질수록 직선관계가 더욱 뚜렷해진다. 이런 것들을 고려해보면 변수 \(x, y\) 와 평균 \(\mu _{x}, \mu _{y}\) 의 차이를 곱한 다음과 같은 값이 직선관계를 가장 잘 나타내준다고 할 수 있다.
\[ (x_i - \mu _{x}) (y_i - \mu _{y}) \]따라서 \(i = 1, 2, 3, \dots, n\) 에 대한 데이터 \((x_i - \mu _{x}) (y_i - \mu _{y})\) 로 를 구하고 그 평균을 구하면 전체 데이터가 얼마나 직선관계를 갖는지 가늠할 수 있다. 이 방식으로 데이터의 직선관계를 수식으로 나타낼 수 있도록 고안된 방법이 다음과 같은 공분산이다.
\[ \text{Cov}(X, Y) = \dfrac{1}{n} \sum_{i=1}^{n}(x_i - \mu _{x})(y_i - \mu _{y}) \]한편 공분산은 다음 공식으로 간편화되어 사용된다.
\[ \begin{align}\begin{split} \text{Cov}(X, Y) &=\dfrac{1}{n} \sum_{i=1}^{n}(x_i - \mu _{x})(y_i - \mu _{y}) \\ &= \dfrac{1}{n} \bigg \{\sum_{i=1}^{n}(x_iy_i - \mu _{x}y_i+x_i \mu _{y} - \mu _{x} \mu _{y}) \bigg \} \\ &= \dfrac{1}{n} \bigg \{\sum_{i=1}^{n}x_iy_i - \mu _{x}\sum_{i=1}^{n} y_i + \mu _{y} \sum_{i=1}^{n}x_i - \sum_{i=1}^{n} \mu _{x} \mu _{y} \bigg \} \\ &= \dfrac{1}{n} \bigg \{\sum_{i=1}^{n}x_iy_i - \mu _{x} \mu _{y}n + \mu _{y} \mu _{x}n - n \mu _{x} \mu _{y} \bigg \} \\ &= \dfrac{1}{n} \bigg \{\sum_{i=1}^{n}x_iy_i - n \mu _{x} \mu _{y} \bigg \} \\ &= \dfrac{1}{n} \bigg \{\sum_{i=1}^{n}x_iy_i - n \bigg ( \dfrac{1}{n}\sum_{i=1}^{n}x_i \bigg ) \bigg ( \dfrac{1}{n}\sum_{i=1}^{n}y_i \bigg ) \bigg \} \\ &= \dfrac{1}{n} \bigg \{\sum_{i=1}^{n}x_iy_i - \dfrac{1}{n}\sum_{i=1}^{n}x_i \sum_{i=1}^{n}y_i \bigg \} \\ \end{split}\end{align} \tag*{} \] -
예시
어떤 회사에서 고객들에 대한 매출량을 \(6\) 개월동안 월별로 조사하여 다음 표를 만들었다.
\(1\) 월 \(2\) 월 \(3\) 월 \(4\) 월 \(5\) 월 \(6\) 월 합계 고객 \(A\) \(5000\) 원 \(5000\) 원 \(5000\) 원 \(5000\) 원 \(5000\) 원 \(5000\) 원 \(30000\) 원 고객 \(B\) \(10000\) 원 \(3000\) 원 \(1000\) 원 \(1000\) 원 \(15000\) 원 \(0\) 원 \(30000\) 원 고객 \(C\) \(3000\) 원 \(7000\) 원 \(2000\) 원 \(8000\) 원 \(4000\) 원 \(6000\) 원 \(30000\) 원 \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) 월매출 \(2500\) 만원 \(4000\) 만원 \(2000\) 만원 \(5500\) 만원 \(3500\) 만원 \(4500\) 만원 \(2\) 억 \(2\) 천만원 고객 \(A, B, C\) 의 \(6\) 개월간의 매출액은 \(30000\) 원으로써 평균 월 매출이 각각 \(5000\) 원이다. 고객 \(B\) 의 매출과 월매출을 각각 확률변수 \(X, Y\) 로 두고 공분산을 구해보자.
\(X\) 의 평균은 \(\mu _{x} = 5000\) 이다. 편의를 위해 월 매출 \(Y\) 를 백만원 단위로 계산하면 \(Y\) 의 평균은 \(\mu _{y} = 22000 \div 6 = 3666.6 \dots\) 이다.
그러면 다음이 성립한다.
\[ \begin{align}\begin{split} &\operatorname{Cov} (X, Y) \\&= \dfrac{1}{n} \sum_{i=1}^{n}(x_i - \mu _{x})(y_i - \mu _{y}) \\ &= \dfrac{1}{6}\{(10000 - 5000)(25 - 36.66 \dots) +\\ & \quad \qquad (3000 - 5000)(40 - 36.66 \dots) + \\ & \quad \qquad (1000 - 5000)(20 - 36.66 \dots) + \\ & \quad \qquad (1000 - 5000)(55 - 36.66 \dots) + \\ & \quad \qquad (15000 - 5000)(35 - 36.66 \dots) + \\ & \quad \qquad (0 - 5000)(45 - 36.66 \dots) \} \\ &= -21667\\ \end{split}\end{align} \tag*{}\]같은 방식으로 고객 \(A, B, C\) 에 대한 원 매출, 분산, 표준편차, 공분산을 구해보면 다음과 같다.
평균 매출 분산 \(\sigma ^{2}\) 표준편차 \(\sigma\) 공분산 고객 \(A\) \(5000\) 원 \(0\) 원 \(^{2}\) \(0\) 원 \(0\) 고객 \(B\) \(5000\) 원 \(31,000,000\) 원 \(^{2}\) \(5568\) 원 \(-21667\) 고객 \(C\) \(5000\) 원 \(4,666,667\) 원 \(^{2}\) \(2160\) 원 \(24167\) 평균 월 매출 \(3666. 66\dots\) 백만원 \(138.89\) 백만원 \(^{2}\) 약 \(1200\) 백만원
공분산 행렬(covariance matrix)
확률벡터 \(x \in \R^n\) 에 대한 공분산 행렬은 다음과 같은 \(n \times n\) 행렬이다.
-
공분산 행렬의 대각성분은 분산이다.
\[ \operatorname{Cov} (x_i, x_i) = V (x_i) \]
편차제곱의 합
데이터 \(x, y\) 와 각각의 평균 \(\mu _{x}, \mu _{y}\) 에 대하여 다음이 성립한다.
-
증명
다음과 같이 \(S _{xx}\) 에 대한 식을 도출할 수 있고 \(S _{yy}, S _{xy}\) 에 대한 식도 비슷한 방법으로 쉽게 이끌어낼 수 있다.
\[ \begin{align}\begin{split} S _{xx} &= \sum_{i=1}^{n}(x_i - \mu _{x} ) ^{2} = \sum_{i=1}^{n} (x_i ^{2} -2x_i \mu _{x} + \mu _{x} ^{2}) \\ &= \sum_{i=1}^{n}x_i ^{2} - \sum_{i=1}^{n}2x_i \mu _{x} + \sum_{i=1}^{n} \mu _{x} ^{2} \\ &= \sum_{i=1}^{n}x_i ^{2} - 2\mu _{x} \sum_{i=1}^{n}x_i + n \mu _{x} ^{2} \\ &= \sum_{i=1}^{n}x_i ^{2} - 2\mu _{x} \cdot \mu _{x}n + n \mu _{x} ^{2} = \sum_{i=1}^{n}x_i ^{2} - 2 n \mu _{x} ^{2} + n \mu _{x} ^{2} \\ &= \sum_{i=1}^{n}x_i ^{2} - 2\mu _{x} \cdot \mu _{x}n + n \mu _{x} ^{2} = \sum_{i=1}^{n}x_i ^{2} - n \mu _{x} ^{2} \\ \end{split}\end{align} \tag*{}\]■
Correlation Coefficient✔
상관계수(correlation coefficient)
확률변수 \(X\) 와 \(Y\) 의 분산이 양수일 때 각각의 표준편차 \(\sigma _{y}, \sigma _{y}\) 와 공분산 \(\sigma _{xy}\) 에 대한 다음과 같은 무차원수이다.
-
정규분포를 표준정규분포로 표준화할 때 확률변수 \(X\) 에 평균 \(\mu\) 를 빼고 표준편차 \(\sigma\) 로 나누어 새로운 확률변수 \(Z = \dfrac{X - \mu}{\sigma }\) 를 얻었다. 이와 같은 방식으로 측정단위에 영향을 받는 공분산
\[ \operatorname{Cov} (X, Y) = \sigma _{xy} = \dfrac{1}{n} \sum_{i=1}^{n}(x_i - \mu _{x})(y_i - \mu _{y}) \]을 표준화하려면 확률변수 \(X\) 를 \(\dfrac{X - \mu _{x}}{\sigma _{x}}\) 로 표준화하고 확률변수 \(Y\) 를 \(\dfrac{Y - \mu _{y}}{\sigma _{y}}\) 로 표준화해야 한다. 이를 위하여 공분산에서 데이터와 평균을 뺀 값 \(x_i - \mu _{x}\) 를 표준편차 \(\sigma _{x}\) 로 나누고 \(y_i - \mu _{y}\) 도 표준편차 \(\sigma _{y}\) 로 나누어주면 다음과 같은 상관계수를 얻는다. 상관계수는 단위의 영향을 없애버린 무차원 수로써 표준화가 된 값이다. 상관계수는 측정단위에 영향을 받아 선형관계의 강도를 명확히 알 수 없는 공분산의 단점이 해결되어 직선관계의 정도까지 나타내줄 수 있는 값이다.
\[ \rho = \dfrac{1}{n} \sum_{i=1}^{n} \bigg ( \dfrac{x_i - \mu _{x}}{\sigma _{x}} \bigg ) \bigg (\dfrac{y_i - \mu _{y}}{\sigma _{y}} \bigg ) \]이때 공분산 \(\displaystyle \sigma _{xy} = \dfrac{1}{n} \sum_{i=1}^{n}(x_i - \mu _{x})(y_i - \mu _{y})\) 을 이용하여 수식을 더욱 간단히 표현하면 다음을 얻는다.
\[ \rho = \dfrac{\sigma _{xy}}{\sigma _{x} \sigma _{y}} \]그리고 표준편차 \(\displaystyle \sigma _{x} = \sqrt[]{\dfrac{1}{n}\sum_{i=1}^{n}(x_i-\mu _{x}) ^{2}}, \sigma _{y}= \sqrt[]{\dfrac{1}{n}\sum_{i=1}^{n}(y_i-\mu _{y}) ^{2}}\) 를 이용하여 식을 풀고 편차 제곱의 합 표기
\[ S _{xx} = \sum_{i=1}^{n}(x_i - \mu _{x} ) ^{2} , S _{yy} = \sum_{i=1}^{n}(y_i - \mu _{y} ) ^{2} , S _{xy} = \sum_{i=1}^{n}(x_i - \mu _{x} )(y_i - \mu _{y} ) \]를 사용하면 다음을 얻는다.
\[ \rho = \dfrac{\displaystyle \sum_{i=1}^{n}(x_i-\mu _{x})(y_i - \mu _{y})}{\sqrt[]{\displaystyle \sum_{i=1}^{n}(x_i - \mu _{x})^{2}} \sqrt[]{\displaystyle \sum_{i=1}^{n}(y_i - \mu _{y})^{2}}} = \dfrac{S _{xy}}{\sqrt[]{S _{xx}} \sqrt[]{ S _{yy}} } \] -
예시
어떤 회사에서 \(6\) 개월간의 수입과 지출을 정리한 표가 다음과 같다.
\(1\) 월 \(2\) 월 \(3\) 월 \(4\) 월 \(5\) 월 \(6\) 월 평균 (수입) 월매출 \(2500\) 만원 \(4000\) 만원 \(2000\) 만원 \(5500\) 만원 \(3500\) 만원 \(4500\) 만원 \(3670\) 만원 (지출) 광고비 \(200\) 만원 \(100\) 만원 \(400\) 만원 \(300\) 만원 \(200\) 만원 \(200\) 만원 \(233\) 만원 \(PV\)(광고조회수) \(180\) 만회 \(270\) 만회 \(160\) 만회 \(620\) 만회 \(320\) 만회 \(390\) 만회 \(323\) 만회 이때 월매출이 광고비나 \(PV\)(광고조회수) 와 관련이 있는지 예상이 되서 좀 더 엄밀하게 공분산을 구해보려 한다. 월매출을 \(R\), 광고비를 \(A\), \(PV\) 를 \(P\) 로 두고 공분산 \(\text{Cov}(R,A), \text{Cov}(R,P)\) 를 계산해보자. 먼저 각 데이터에 대한 편차를 구해놓아야 한다.
\(1\) 월 편차 \(2\) 월 편차 \(3\) 월 편차 \(4\) 월 편차 \(5\) 월 편차 \(6\) 월 편차 표준편차 \(R\) \(-11.7\) \(3.3\) \(-16.7\) \(18.3\) \(-1.7\) \(8.3\) \(11.8\) \(A\) \(-0.33\) \(-1.33\) \(1.67\) \(0.67\) \(-0.33\) \(-0.33\) \(0.943\) \(P\) \(-143\) \(-53\) \(-163\) \(297\) \(-3\) \(67\) \(154\) 이를 바탕으로 공분산을 구해보면 다음과 같다.
\[ \begin{align}\begin{split} \text{Cov}(R,A) &= \dfrac{1}{6}\{(-11.7) \times (-0.33) + 3.3 \times (-1.33) + \dots + 8.3 \times (-0.33)\} \\ &= -3.056\\ \end{split}\end{align} \tag*{} \]\[ \text{Cov}(R,P) = \dfrac{1}{6}\{(-11.7) \times (-143) + 3.3 \times (-53) + \dots + 8.3 \times 67\} = 1703 \]이로써 월매출과 광고비는 음의 관계이고 월매출과 광고조회수는 양의 관계임을 알 수 있다.
그런데 이 상관관계가 얼마나 강한지는 알 수 없다. 왜냐하면 광고조회수의 데이터의 값이 단지 크기 때문에 \(1703\) 이라는 큰 수가 계산된 것이기 때문이다. 따라서 이것으로 월매출과 광고비의 공분산 \(-3.056\) 보다 상관관계의 강도가 크다고 말할 수 없다.
월매출과 광고비의 상관계수 \(\rho _{RA}\) 와 월매출과 광고조회수의 상관계수 \(\rho _{RP}\) 를 구해보면 다음과 같다.
\[ \rho _{RA} = \dfrac{\text{Cov}(R,A)}{\sigma _{R} \sigma _{A}} = \dfrac{-3.056}{11.8 \times 0.943} = -0.2746 \]\[ \rho _{RP} = \dfrac{\text{Cov}(R,P)}{\sigma _{R} \sigma _{P}} = \dfrac{1703}{11.8 \times 154} = 0.9372 \]이로써 월매출과 광고조회수 \(PV\) 가 강한 양의 상관관계에 있다고 생각할 수 있다. 또 월매출과 광고비는 약한 음의 상관관계를 갖는다고 볼 수 있다.
상관계수 \(\rho\) 는 \(-1 \leq \rho \leq 1\) 의 범위 내에서 존재한다.
-
일반적으로 상관계수의 절댓값이 \(0.7\) 보다 크면 "상관관계가 강하다" 고 말한다. 상관계수가 \(0\) 에 가까우면 상관관계가 약하거나 거의 없다고 볼 수 있다.
-
증명
코시-슈바르츠 부등식은 \(\displaystyle \bigg ( \sum_{i=1}^{n}a_ib_i \bigg ) ^{2} \leq \sum_{i=1}^{n}a_i ^{2} \sum_{i=1}^{n}b_i ^{2}\) 의 관계를 보증한다.
이때 상관계수의 정의
\[ \rho = \dfrac{\displaystyle \sum_{i=1}^{n}(x_i-\mu _{x})(y_i - \mu _{y})}{\sqrt[]{\displaystyle \sum_{i=1}^{n}(x_i - \mu _{x})^{2}} \sqrt[]{\displaystyle \sum_{i=1}^{n}(y_i - \mu _{y})^{2}}} \]에서 \(a_i = x_i - \mu _{x}, b_i = y_i - \mu _{y}\) 로 두면
\[ = \dfrac{\displaystyle \sum_{i=1}^{n}a_ib_i}{\sqrt[]{\displaystyle \sum_{i=1}^{n}a_i^{2}} \sqrt[]{\displaystyle \sum_{i=1}^{n}b_i^{2}}} \]을 얻는다. 양변에 제곱을 취하면
\[ \rho ^{2} = \dfrac{\bigg (\displaystyle \sum_{i=1}^{n}a_ib_i \bigg ) ^{2}}{\displaystyle \sum_{i=1}^{n}a_i^{2} \displaystyle \sum_{i=1}^{n}b_i^{2}} \]을 얻는데 코시-슈바르츠 부등식 \(\displaystyle \bigg ( \sum_{i=1}^{n}a_ib_i \bigg ) ^{2} \leq \sum_{i=1}^{n}a_i ^{2} \sum_{i=1}^{n}b_i ^{2}\) 에서
\[ \rho ^{2} = \dfrac{\bigg (\displaystyle \sum_{i=1}^{n}a_ib_i \bigg ) ^{2}}{\displaystyle \sum_{i=1}^{n}a_i^{2} \displaystyle \sum_{i=1}^{n}b_i^{2}} \leq 1 \]임을 알 수 있다. 즉, \(\rho ^{2} \leq 1\) 이므로 다음이 성립한다.
\[ -1 \leq \rho \leq 1 \tag*{■} \] -
예시
상관계수가 \(-0.9\) 라면 음의 상관관계가 강하다고 할 수 있다.
상관계수가 \(0.8\) 라면 양의 상관관계가 강하다고 할 수 있다.
Sample Covariance✔
표본공분산(sample covariance)
\(n\)개의 값을 갖는 확률변수 \(X, Y\) 와 \(X\) 의 평균 \(\mu _{x}\), \(Y\) 의 평균이 \(\mu _{y}\) 에 대하여 다음을 표본공분산이라 한다.
-
추출된 표본의 두 데이터의 직선관계를 나타내는 값이다. 공분산이 \(n\) 으로 나눈 반면 표본공분산은 \(n-1\) 로 나누었다는 것에 주의하자.
-
증명
표본공분산은 다음과 같이 간소화된다.
\[ \begin{align}\begin{split} \text{Cov}(X, Y) &= \dfrac{1}{n-1} \sum_{i=1}^{n}(x_i - \mu _{x})(y_i - \mu _{y}) \\ &= \dfrac{1}{n-1} \bigg \{\sum_{i=1}^{n}(x_iy_i - \mu _{x}y_i+x_i \mu _{y} - \mu _{x} \mu _{y}) \bigg \} \\ &= \dfrac{1}{n-1} \bigg \{\sum_{i=1}^{n}x_iy_i - \mu _{x}\sum_{i=1}^{n} y_i + \mu _{y} \sum_{i=1}^{n}x_i - \sum_{i=1}^{n} \mu _{x} \mu _{y} \bigg \} \\ &= \dfrac{1}{n-1} \bigg \{\sum_{i=1}^{n}x_iy_i - \mu _{x} \mu _{y}n + \mu _{y} \mu _{x}n - n \mu _{x} \mu _{y} \bigg \} \\ &= \dfrac{1}{n-1} \bigg \{\sum_{i=1}^{n}x_iy_i - n \mu _{x} \mu _{y} \bigg \} \\ &= \dfrac{1}{n-1} \bigg \{\sum_{i=1}^{n}x_iy_i - n \bigg ( \dfrac{1}{n}\sum_{i=1}^{n}x_i \bigg ) \bigg ( \dfrac{1}{n}\sum_{i=1}^{n}y_i \bigg ) \bigg \} \\ &= \dfrac{1}{n-1} \bigg \{\sum_{i=1}^{n}x_iy_i - \dfrac{1}{n}\sum_{i=1}^{n}x_i \sum_{i=1}^{n}y_i \bigg \} \\ \end{split}\end{align} \tag*{}\]■
-
예시
올림픽 육상 \(100\) 미터 남자 우승기록에서 \(1900\) 년부터 \(2016\) 년까지의 표본은 다음과 같다.
번호 \(X\)(연도) \(Y\)(기록) \(XY\) \(1\) \(1900\) \(11\) \(20900\) \(2\) \(1904\) \(11\) \(20944\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(27\) \(2016\) \(9.81\) \(19776.96\) 합계 \(52940\) \(276.76\) \(542291.2\) 연도와 기록에 대한 표본공분산은 다음과 같다.
\[ \text{Cov}(X,Y) = \dfrac{1}{27 - 1}\bigg \{ 542291.2 - \dfrac{1}{27}(52940)(276.76) \bigg \} = -13.98 \]즉 연도와 기록은 음의 관계를 갖고 연도가 높아질수록 기록이 줄어든다고 볼 수 있다.
또 한편 공분산은 측정 데이터의 단위에 영향을 받으므로 \(-13.98\) 이 선형관계의 강도를 보여줄 수 있는 것은 아니다. 실제로 기록을 나타내는 확률변수 \(Y\) 의 단위를 초에서 분으로 바꾸면 데이터들에 \(\times \dfrac{1}{60}\) 연산을 해주어야 하는데 이때 \(-13.98 \to -0.233\) 으로 공분산이 변한다. 따라서 공분산의 절댓값 크기에서 의미를 찾으려 들면 안된다.
Sample Correlation Coefficient✔
표본상관계수(sample correlation coefficient)
확률변수 \(X\) 와 \(Y\) 의 분산이 양수일 때 각각의 표본표준편차 \(\sigma _{x}, \sigma _{y}\) 와 표본공분산 \(\sigma _{xy}\) 에 대한 다음과 같은 무차원수이다.
-
측정단위에 영향을 받아 선형관계의 강도를 명확히 알 수 없는 표본공분산의 단점을 해결하여 직선관계의 정도까지 나타내줄 수 있는 추출된 표본의 통계값이다.
표본상관계수도 마찬가지로 \(-1\) 에서 \(1\) 의 값을 갖는다. \(0\) 에 가까우면 직선상관관계가 없다고 볼 수 있다.
-
그러나 두 변수가 직선관계가 있다고 해서 잠복변수의 존재에 의하여 인과관계를 갖는다고 할 수는 없다. 가령 휴대전화 보급률과 기대수명에 대한 선형상관관계는 매우 높다. 그렇다면 수명을 늘리기 위해 휴대전화 보급을 늘려야 하는가? 이 두 변수는 인과관계가 없기 때문에 올바르지 않는 결론이다.
Linearity of Expectation✔
기댓값의 선형성(linearity of expectation)
확률변수 \(X_1, X_2, \dots, X_n\) 와 상수 \(c_1, c_2, \dots, c_n\) 에 대하여 다음이 성립한다.
-
머신러닝에서는 다음과 같이 표기한다.
\[ \Bbb{E}_{X}[\alpha f(x) + \beta g(x)] = \alpha \Bbb{E}_{X}[f(x)] + \beta \Bbb{E}_{X}[g(x)] \] -
증명
이산확률변수 \(X, Y\) 의 합 \(X + Y\) 으로 형성된 결합분포의 평균 \(E[X+Y]\) 다음과 같다.
\[ \begin{align}\begin{split} E[X + Y] &= \sum_{x}^{}\sum_{y}^{}[(x + y) \cdot P(X = x, Y = y) \\ &=\sum_x \sum_y [x \cdot P(X = x, Y = y)] + \sum_x \sum_y[y \cdot P(X = x, Y = y)] \\ &=\sum_xx \sum_y P(X = x, Y = y) + \sum_yy \sum_x P(X = x, Y = y) \\ &=\sum_xx P(X = x) + \sum_yy P(Y = y) \\ &=E[X] + E[Y] \end{split}\end{align} \tag*{} \]연속확률변수에 대해서는 \(\sum\) 을 \(\int_{}^{}\) 로 바꾸기만 하면 똑같은 논리로 덧셈에 대한 선형성을 증명 할 수 있다.
스칼라곱에 대한 선형성은 이산확률변수의 기댓값의 성질과 연속확률변수의 기댓값의 성질을 사용하여 쉽게 증명 가능하다.
두 확률변수의 기댓값의 선형성이 증명되면 두 개 이상의 확률변수의 기댓값의 선형성은 수학적 귀납법으로 쉽게 증명 할 수 있다. ■
-
예시
두 주사위를 던져서 나온 두 눈의 합을 확률변수 \(A\), 곱을 확률변수 \(B\) 라고 하자. \(E[A + B]\) 를 구해보자.
선형성에 의하여 \(E[A]\) 와 \(E[B]\) 만 구하면 된다. \(E[A]\) 는 두 주사위의 눈의 합의 평균이므로 한 주사위의 눈을 확률변수 \(C\) 으로 두면 \(E[C + C] = E[A]\) 이다. \(E[C] = 3.5\) 인데 선형성에 의하여 \(2E[C]\) 이므로 \(E[A] = 7\) 이다.
\(E[B]\) 는 두 주사위 눈의 곱의 평균이므로 \(E[B] = 3.5 \cdot 3.5 = 12.25\) 이다. 따라서 다음이 성립한다.
\[ E[A + B] = E[A] + E[B] = 7 + 12.25 = 19.25 \]
Variance of Linear Combination of Random Variables✔
확률변수의 일차결합의 분산(Variance of Linear Combination of Random Variables)
확률변수 \(X, Y\) 와 실수 \(a, b\) 에 대하여 확률변수 \(X, Y\) 의 분산이 유한하면 다음이 성립한다.
\(X, Y\) 가 서로 독립이면 다음이 성립한다.
Population and Sample✔
모집단(population)
조사하고자 하는 전체 대상이다.
-
모집단을 조사하는 것을 전수조사(total inspection)라 한다.
-
예시
한 학교의 학생들의 여론조사를 위하여 전교생들에 대한 설문조사를 진행한다고 하자. 이때 그 학교의 모든 학생 집단은 모집단이다. 이때 이 설문조사는 전수조사가 된다.
표본(sample)
조사를 하기 위하여 모집단의 일부분을 추출한 것이다.
-
여론조사를 하기 위하여 한 국가의 전 국민에 대한 설문조사를 시행하려면 시간과 비용이 너무 많이 들어가서 어느 시점부터 여론조사를 하는 효용을 상쇄시키고, 어느 시점부터는 손실이 더 커진다. 따라서 이를테면 모집단에서 국민 \(1000\) 명을 추출하여 표본을 만들어 조사한다. 정확도를 약간 잃더라도 시간과 비용이 소모되는 것을 적당한 선에서 제한하는 것이다.
-
모집단의 일부인 표본만 조사하는 것을 표본조사(sample survey)라 한다.
표본조사의 목적은 모집단에서 얻은 표본으로부터 얻는 정보를 분석하여 최종적으로 모집단의 성질을 추측하는 것이다. 아무리 표본을 조사한다고 하지만 결국에 관심있는 것은 모집단에 대한 정보이다.
추출(sampling)
모집단으로부터 표본에 포함시킬 대상들을 뽑는 것이다.
-
표본을 생성하기 위하여 모집단에서 대상을 추출하는데 표본조사의 목적은 결국에 모집단을 이해하기 위함이다. 따라서 모집단으로부터 일부 대상을 추출할 때 모집단의 특성이 잘 반영되도록 대상들을 뽑아야 한다.
-
추출한 것을 다시 넣고 다음을 추출하는 방법을 복원추출(sampling with replacement), 추출한 것을 다시 넣지 않고 다음을 추출하는 방법을 비복원추출(sampling without replacement) 이라 한다. 모집단의 크기가 충분히 크면 비복원추출도 복원추출로 볼 수 있다.
임의추출(random sampling)
추출의 방법 중 하나로써 모집단에 속한 각 대상들을 같은 확률로 뽑는 방법이다.
-
예시
제비뽑기나 난수 생성기로 표본을 추출하는 것이 임의추출이다.
-
임의추출한 표본을 임의표본(random sample)이라 한다.
Probability Distribution of Population✔
모집단의 확률분포
모집단에서 조사의 대상이 되는 특성을 나타내는 확률변수의 확률분포이다.
-
예시
모집단 \(\{1,2,3\}\) 에서 하나의 숫자를 취할 확률변수를 \(X\) 라 할 때 다음 표를 모집단의 확률분포라고 할 수 있다.
\(X\) \(1\) \(2\) \(3\) \(P(X=x)\) \(\dfrac{1}{3}\) \(\dfrac{1}{3}\) \(\dfrac{1}{3}\)
모평균(population mean)
모집단의 확률분포의 확률변수 \(X\) 의 평균을 모평균이라 한다.
-
예시
모집단의 확률분포 의 예시의 모집단의 확률분포에서 모평균을 구해보면 다음과 같다.
\[ \mu = 1 \times \dfrac{1}{3} + 2 \times \dfrac{1}{3} + 3 \times \dfrac{1}{3} = \dfrac{1+2+3}{3} = 2 \]이 값으로 "다음 시행에서 \(2\) 라는 값이 나올 것을 기대할 수 있다" 또는 "평균적으로 값이 \(2\) 가 된다" 라고 해석할 수 있다.
모분산(population variance)
모집단의 확률분포의 확률변수의 분산을 모분산이라 한다.
-
예시
모집단의 확률분포 의 예시의 모집단의 확률분포에서 모분산을 구해보면 다음과 같다.
\[ \sigma ^{2} = E(X ^{2}) - \mu ^{2} = \bigg (1 ^{2} \dfrac{1}{3}+2 ^{2}\dfrac{1}{3}+3 ^{2}\dfrac{1}{3}\bigg ) - 2^{2} = \dfrac{1+4+9}{3}- \dfrac{12}{3} = \dfrac{2}{3} \]
모표준편차(population standard deviation)
모집단의 확률분포의 확률변수의 표준편차를 모표준편차라 한다.
-
예시
모집단의 확률분포 의 예시의 모집단의 확률분포에서 모표준편차를 구해보면 다음과 같다.
\[ \sigma = \sqrt[]{\dfrac{2}{3}} = \dfrac{\sqrt[]{6}}{3} \]
Sample Mean✔
표본평균(sample mean)
모집단에서 크기가 \(n\) 인 표본 \(X_1, X_2, \dots, X_n\) 을 임의추출했을 때 이들의 평균 \(\displaystyle \bar{X} = \dfrac{1}{n} \sum_{i=1}^{n}X_i\) 이다.
-
모평균 \(\mu\) 이 고정된 상수임에 비해 표본평균 \(\bar{X}\) 은 추출된 표본에 따라 여러 값을 가질 수 있는 확률변수이다.
-
모집단의 확률분포가 정규분포이면 표본평균 \(\bar{X}\) 는 \(n\) 의 크기에 관계없이 정규분포 \(N \bigg (\mu , \dfrac{\sigma ^{2}}{n} \bigg )\) 를 따른다.
-
(중심극한정리) 모집단의 확률분포가 정규분포가 아니어도 \(n\) 이 충분히 크면 표본평균 \(\bar{X}\) 는 근사적으로 정규분포 \(N \bigg (\mu , \dfrac{\sigma ^{2}}{n} \bigg )\) 를 따른다. 보통 \(n\) 이 \(30\) 이상이면 충분히 큰 표본으로 간주한다.
-
예시
모집단의 확률분포 의 예시의 모집단에서 크기가 \(2\) 인 표본을 임의추출한 표본을 \(X_1, X_2\) 라 하면 이 표본은 다음 중 하나로 될 수 있다.
확률변수 \(X_1\) \(1\) \(1\) \(1\) \(2\) \(2\) \(2\) \(3\) \(3\) \(3\) \(X_2\) \(1\) \(2\) \(3\) \(1\) \(2\) \(3\) \(1\) \(2\) \(3\) 이때 표본들의 표본평균 \(\bar{X} = \dfrac{X_1+X_2}{2}\) 는
확률변수 \(\bar{X}\) \(1\) \(1.5\) \(2\) \(1.5\) \(2\) \(2.5\) \(2\) \(2.5\) \(3\) 위와 같은 값을 가질 수 있는 확률변수이다. 이 새로운 확률변수 \(\bar{X}\)(표본평균) 에 대한 평균, 분산, 표준편차를 구할 수 있다.
표본분산(sample variance)
모집단에서 크기가 \(n\) 인 표본 \(X_1, X_2, \dots, X_n\) 을 임의추출했을 때 다음과 같은 이 표본의 분산을 표본분산이라 한다.
- 모분산과 달리 표본분산에서는 분산을 표본의 크기 \(n\) 이 아닌 \(n-1\) 로 나누어서 구하는데 이는 표본분산과 모분산의 차이를 줄이기 위해서이다. (cf. 편향된 표본 분산의 조정법)
표본표준편차(sample standard deviation)
모집단에서 임의추출한 표본의 분산 \(S ^{2}\) 에 대하여 \(S\) 를 표본표준편차라 한다.
표본평균의 평균
모평균이 \(\mu\), 모표준편차가 \(\sigma\) 인 모집단에서 크기가 \(n\) 인 표본을 임의추출 할 때 표본평균 \(\bar{X}\) 들의 평균은 다음과 같다.
-
표본평균의 평균이 모평균과 같다 는 것이지, 표본평균이 모평균과 같다는 것이 아니다. 표본평균은 당연히 모평균과 다를 것이다.
-
증명
기댓값은 선형이므로 표본평균 \(\displaystyle \bar{X} = \dfrac{1}{n} \sum_{i=1}^{n}X_i\) 다음이 성립한다.
\[ \begin{align}\begin{split} E(\bar{X})&= E \left( \dfrac{1}{n} \sum_{i=1}^{n}X_i \right) \\ &= \frac{1}{n}\sum_{i=1}^{n}E(X_i) = \frac{1}{n} \cdot n \mu \\ &= \mu \\ \end{split}\end{align} \tag*{} \]■
-
예시
모집단의 확률분포 의 예시의 모집단에서 크기가 \(2\) 인 표본을 임의추출한 표본을 \(X_1, X_2\) 이었을 때 이 표본의 평균 \(\bar{X} = \dfrac{X_1+X_2}{2}\) 를 구하여 확률변수 \(\bar{X}\) 의 평균을 구해보자.
"표본평균(sample mean)" 의 예시에서 확률변수 \(\bar{X}\) 는 다음과 같은 값을 가질 수 있음을 조사했다.
확률변수 \(\bar{X}\) \(1\) \(1.5\) \(2\) \(1.5\) \(2\) \(2.5\) \(2\) \(2.5\) \(3\) 따라서 표본평균 \(\bar{X}\) 의 확률분포표는 다음과 같다.
\(\bar{X}\) \(1\) \(1.5\) \(2\) \(2.5\) \(3\) \(P(\bar{X}=x)\) \(\dfrac{1}{9}\) \(\dfrac{2}{9}\) \(\dfrac{3}{9}\) \(\dfrac{2}{9}\) \(\dfrac{1}{9}\) 이제 표본평균 \(\bar{X}\) 의 평균을 구해보면
\[ \begin{align}\begin{split} E(\bar{X}) &=1 \times \dfrac{1}{9} + 1.5 \times \dfrac{2}{9} + 2 \times \dfrac{3}{9} + 2.5 \times \dfrac{2}{9} + 3 \times \dfrac{1}{9} \\ &= \dfrac{1 + 3 + 6 + 5 + 3}{9} = \dfrac{18}{9} = 2 \\ \end{split}\end{align} \tag*{} \]임을 알 수 있다.
한편 표본평균의 평균 \(E(\bar{X})\) 는 모평균 \(\mu\) 와 \(E(\bar{X}) = \mu\) 의 관계를 갖는다는 점을 이용하여 "모평균(population mean)" 의 예시에서 \(\mu = 2\) 였으므로
\[ E(\bar{X}) = \mu = 2 \]임을 알 수 있다.
표본평균의 분산
모평균이 \(\mu\), 모표준편차가 \(\sigma\) 인 모집단에서 크기가 \(n\) 인 표본을 임의추출 할 때 표본평균 \(\bar{X}\) 들의 분산은 다음과 같다.
-
증명
확률변수의 일차결합의 분산 정리 에 의하여 표본평균 \(\bar{X}\) 의 분산은 다음과 같다.
\[ \begin{align}\begin{split} V(\bar{X}) &= V \left( \frac{1}{n}\sum_{i=1}^{n}X_i \right) \\ &= \frac{1}{n^2} \sum_{i=1}^{n}V (X_i) \\ &= \frac{1}{n^2} \sum_{i=1}^{n} \sigma ^{2} = \dfrac{\sigma ^{2}n}{n ^{2}} = \frac{\sigma ^{2}}{n} \\ \end{split}\end{align} \tag*{} \]■
-
예시
모집단의 확률분포 의 예시의 모집단에서 크기가 \(2\) 인 표본을 임의추출한 표본을 \(X_1, X_2\) 이었을 때 이 표본의 평균 \(\bar{X} = \dfrac{X_1+X_2}{2}\) 를 구하여 확률변수 \(\bar{X}\) 의 분산을 구해보자.
표본평균의 평균 의 예시에서 표본평균 \(\bar{X}\) 의 확률분포표는 다음과 같고, 표본평균 \(\bar{X}\) 의 평균은 \(E(\bar{X}) = 2\) 이다.
\(\bar{X}\) \(1\) \(1.5\) \(2\) \(2.5\) \(3\) \(P(\bar{X}=x)\) \(\dfrac{1}{9}\) \(\dfrac{2}{9}\) \(\dfrac{3}{9}\) \(\dfrac{2}{9}\) \(\dfrac{1}{9}\) 따라서 표본평균의 분산 \(V(\bar{X})\) 은 다음과 같다.
\[ \begin{align}\begin{split} V(\bar{X}) &=E(\bar{X} ^{2}) - \{E(\bar{X})\} ^{2} \\ &= \bigg (1 ^{2} \times \dfrac{1}{9} + 1.5 ^{2} \times \dfrac{2}{9} + 2 ^{2} \times \dfrac{3}{9} + 2.5 ^{2} \times \dfrac{2}{9} + 3 ^{2} \times \dfrac{1}{9} \bigg ) - 2 ^{2}\\ &= \dfrac{13}{3}-4 = \dfrac{1}{3} \\ \end{split}\end{align} \tag*{} \]한편 표본평균의 분산 \(V(\bar{X})\) 는 모분산 \(\sigma ^{2}\) 와 표본의 크기 \(n\) 에 대하여 \(V(\bar{X}) = \dfrac{\sigma ^{2}}{n}\) 의 관계를 갖는다. 모분산(population variance) 의 예시에서 \(\sigma ^{2} = \dfrac{2}{3}\) 이고 표본의 크기는 \(2\) 였으므로 표본평균의 분산을 다음과 같이 구할 수도 있다.
\[ V(\bar{X}) = \dfrac{\sigma ^{2}}{n} = \dfrac{\frac{2}{3}}{2} = \dfrac{1}{3} \]
표준오차(표본평균의 표준편차, standard error)
모평균이 \(\mu\), 모표준편차가 \(\sigma\) 인 모집단에서 크기가 \(n\) 인 표본을 임의추출 할 때 표본평균 \(\bar{X}\) 들의 표준편차는 다음과 같다.
-
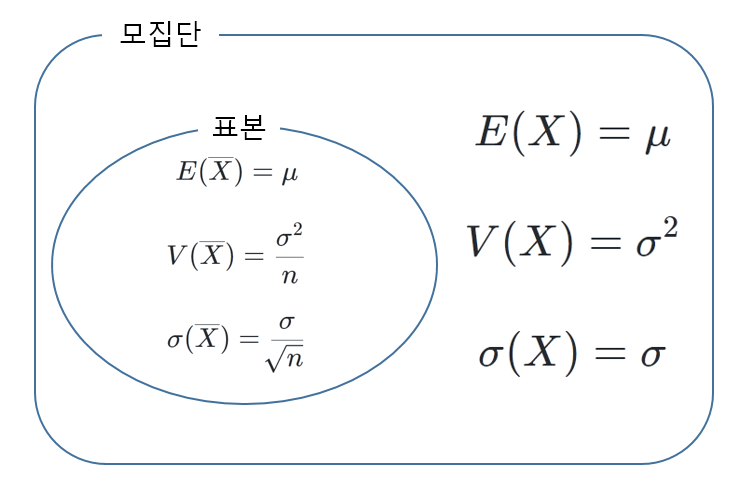
그러므로 모집단의 평균, 분산, 표준편차와 표본의 평균, 분산, 표준편차는 다음과 같은 관계를 가진다.
-
예시
모집단의 확률분포 의 예시의 모집단에서 크기가 \(2\) 인 표본을 임의추출한 표본을 \(X_1, X_2\) 이었을 때 이 표본의 평균 \(\bar{X} = \dfrac{X_1+X_2}{2}\) 를 구하여 확률변수 \(\bar{X}\) 의 표준편차 구해보자.
표본평균의 분산 의 예시에서 표본평균 \(\bar{X}\) 의 분산은 \(V(\bar{X}) = \dfrac{1}{3}\) 이다. 따라서 표본평균의 표준편차 \(\sigma (\bar{X})\) 은 다음과 같다.
\[ \sigma (\bar{X}) = \sqrt[]{\dfrac{1}{3}} = \dfrac{\sqrt[]{3}}{3} \]한편 표본평균의 표준편차 \(\sigma(\bar{X})\) 는 모표준편차 \(\sigma\) 와 표본의 크기 \(n\) 에 대하여 \(\sigma (\bar{X}) = \dfrac{\sigma }{\sqrt[]{n}}\) 의 관계를 갖는다는 점을 이용하여 모표준편차(population variance) 의 예시에서 \(\sigma = \dfrac{\sqrt[]{6}}{3}\) 이고 표본의 크기는 \(2\) 였으므로 다음과 같이 구할 수도 있다.
\[ \sigma (\bar{X}) = \dfrac{\sigma }{\sqrt[]{n}} = \dfrac{\frac{\sqrt[]{6}}{3}}{\sqrt[]{2}} = \dfrac{\sqrt[]{6}}{3 \sqrt[]{2}} = \dfrac{\sqrt[]{12}}{6} = \dfrac{\sqrt[]{3}}{3} \] -
예시
어떤 공장에서 생산한 건전지의 수명은 평균이 \(200\) 시간이고 표준편차가 \(10\) 시간인 정규분포 \(N(200, 10 ^{2})\) 을 따른다고 하자. 이때 생산된 건전지 중에서 임의추출한 크기가 \(25\) 인 표본의 표본평균을 \(\bar{X}\) 라 할 때 \(P(199 \leq \bar{X} \leq 201)\) 의 값을 구해보자.
모집단이 정규분포 \(N(200, 10 ^{2})\) 를 따르므로 크기가 \(25\) 인 표본평균 \(\bar{X}\) 는 정규분포 \(N \bigg (200, \dfrac{10 ^{2}}{25}\bigg ) = N(200, 2 ^{2})\) 를 따른다. 이제 확률변수 \(\bar{X}\) 를 표준화하여 표준정규분포의 확률변수 \(Z = \dfrac{\bar{X} - \mu }{\sigma } = \dfrac{\bar{X} - 200}{2}\) 를 만들자. 그러면 다음이 성립한다.
\[ \begin{align}\begin{split} P(199 \leq \bar{X} \leq 201) &= P \bigg (\dfrac{199 - 200}{2} \leq Z \leq \dfrac{201 - 200}{2} \bigg ) \\ &= P(-0.5 \leq Z \leq 0.5) = 2 P(0 \leq Z \leq 0.5) \\ &= 2 \times (0.1915) = 0.383 \\ \end{split}\end{align} \tag*{}\]이 값은 "수명이 \(199\) 이상이고 \(201\) 인 건전지의 비율이 \(38.3\%\) 이다" 또는 "어떤 건전지를 골랐는데 그 수명이 \(199\) 이상이고 \(201\) 이하일 확률이 \(38.3\%\) 이다" 로 해석될 수 있다.
Sample Ratio✔
모비율(population ratio)
모집단에서 어떤 특성을 가지는 대상의 비율을 그 특성에 대한 모비율 \(p\) 라 한다.
-
예시
어느 도시의 청소년 \(3482\) 명 중 흡연자가 \(218\) 명이라고 하면 모집단에서 청소년 흡연자의 비율, 즉 모비율은 다음과 같다.
\[ p = \dfrac{218}{3482} \approx 0.062 = 6.2\% \]
표본비율(sample ratio)
모집단에서 임의추출한 크기가 \(n\) 인 표본에서 이 특성을 가지는 대상의 수를 확률변수 \(X\) 라 할 때 그 특성에 대한 대상의 비율을 그 특성에 대한 표본비율 \(\hat{p} = \dfrac{X}{n}\) 이라 한다.
-
예시
"모비율" 의 예시의 어느 도시의 청소년 \(3482\) 명 중 흡연자가 \(218\) 명이라고 하였다. 이때 모집단에서 \(300\) 명을 임의추출했더니 그중에서 청소년 흡연자가 \(31\) 명이었다. 그러면 표본에서 청소년 흡연자의 비율, 즉 표본비율은 다음과 같다.
\[ \hat{p} = \dfrac{31}{300} \approx 0.103 = 10.3\% \]
표본의 크기 \(n\) 이 충분히 크면 표본비율 \(\hat{p}\) 는 근사적으로 \(q=1-p\) 에 대한 정규분포 \(N \bigg ( p, \dfrac{pq}{n} \bigg )\) 를 따른다.
-
증명
표본비율 \(\hat{p} = \dfrac{X}{n}\) 에서 확률변수 \(X\) 는 모집단에서 임의추출한 크기 \(n\) 의 표본에서 어떤 특성을 가진 대상의 갯수이다. 이때 모비율 \(p\) 에 의하여 모집단에서 각각의 대상들이 그 특성을 가질 확률은 \(p\) 이다. 또한 확률변수 \(X\) 란 모집단에서 대상을 뽑는 독립시행을 \(n\) 번 했을 때 특성을 갖는 대상들의 수이다. 따라서 확률변수 \(X\) 는 특성을 갖는 대상의 갯수 \(x = 0, 1, 2, \dots, n\) 와 \(q = 1-p\) 에 대하여 확률질량함수
\[ P(X = x) = {}_{n}C_{x} p ^{x} q ^{n-x} \]를 가지며 이항분포의 정의에 의하여 이항분포 \(B(n, p)\) 를 따른다. 그러므로 확률변수 \(X\) 의 평균과 분산은 다음과 같다.
\[ E(X) = np, V(X) = npq \]이때 이항분포에서 \(n\) 이 충분히 크면 확률분포가 정규분포를 따르므로 확률변수 \(X\) 는 근사적으로 정규분포를 따른다. 그런데 표본비율 \(\hat{p} = \dfrac{X}{n}\) 도 단지 확률변수 \(X\) 를 \(n\) 으로 나눈 것이므로 표본의 크기 \(n\) 이 충분히 크면 평균 \(E(\hat{p})\) 과 분산 \(V(\hat{p})\) 에 대하여 근사적으로 다음과 같은 정규분포를 따른다.
\[ N \bigg(E(\hat{p}) , V(\hat{p}) \bigg ) = N \bigg(p , \dfrac{pq}{n} \bigg ) \tag*{■} \]
표본비율 \(\hat{p}\) 의 평균
모비율이 \(p\) 인 모집단에서 크기가 \(n\) 인 표본을 임의추출 할 때 표본비율 \(\hat{p}\) 에 대하여 평균은 다음과 같다.
-
증명
"표본비율(sample ratio)" 의 \(n\) 이 클 때 표본비율 \(\hat{p}\) 이 정규분포를 따르는 것의 증명에 의하여 확률변수 \(X\) 는 이항분포 \(B(n, p)\) 를 따르며 평균과 분산은 다음과 같다.
\[ E(X) = np, V(X) = npq \]이에 따라 확률변수 \(X\) 의 스칼라배 \(\dfrac{1}{n}\) 인 표본비율 \(\hat{p} = \dfrac{X}{n}\) 의 평균은 다음과 같다.
\[ E(\hat{p}) = E \bigg (\dfrac{X}{n} \bigg ) = \dfrac{1}{n}E(X)=\dfrac{1}{n} np = p \tag*{■} \]
표본비율 \(\hat{p}\) 의 분산
모비율이 \(p\) 인 모집단에서 크기가 \(n\) 인 표본을 임의추출 할 때 표본비율 \(\hat{p}\) 에 대하여 분산은 \(q = 1 - p\) 에 대하여 다음과 같다.
-
증명
"표본비율 \(\hat{p}\) 의 평균" 의 증명에 의하여 확률변수 \(X\) 는 이항분포 \(B(n, p)\) 를 따르며 확률변수 \(X\) 의 평균과 분산은 \(q = 1-p\) 에 대하여 다음과 같다.
\[ E(X) = np, V(X) = npq \]따라서 확률변수 \(X\) 의 스칼라배 \(\dfrac{1}{n}\) 인 표본비율 \(\hat{p} = \dfrac{X}{n}\) 의 분산은 다음과 같다.
\[ V(\hat{p}) = V \bigg (\dfrac{X}{n} \bigg ) = \dfrac{1}{n ^{2}}V(X)=\dfrac{1}{n ^{2}} npq = \dfrac{pq}{n} \tag*{■} \]
표본비율 \(\hat{p}\) 의 표준편차
모비율이 \(p\) 인 모집단에서 크기가 \(n\) 인 표본을 임의추출 할 때 표본비율 \(\hat{p}\) 에 대하여 표준편차는 \(q = 1 - p\) 에 대하여 다음과 같다.
-
증명
"표본비율 \(\hat{p}\) 의 분산" 의 증명에 의하여 확률변수 \(X\) 의 스칼라배 \(\dfrac{1}{n}\) 인 표본비율 \(\hat{p} = \dfrac{X}{n}\) 의 분산은 다음과 같다.
\[ V(\hat{p}) = \dfrac{pq}{n} \]그러므로 표본비율 \(\hat{p}\) 의 표준편차는 다음과 같다.
\[ \sigma (\hat{p}) = \sqrt[]{\dfrac{pq}{n}} \tag*{■} \] -
예시
어떤 고등학교 학생 중 \(40\%\) 가 졸업 후 대학에 진학하지 않고 바로 취직할 것으로 조사되었다. 이 고등학교 학생 중에서 \(96\) 명을 임의추출했을 때 바로 취직할 학생이 \(46\%\) 이상 \(50\%\) 이하일 확률을 구해보자. 대상의 특성을 "졸업 후 바로 취직하는 학생" 으로 두면 모집단에서 특성에 대한 모비율은 \(p = 0.4\) 이다. 임의추출한 \(96\) 명의 표본에서 \(96\) 을 \(n\) 으로 두고 특성을 가지는 수를 \(X\) 로 두면 표본비율을 \(\hat{p} = \dfrac{X}{n}\) 로 볼 수 있고 이때 표본비율이 \(P(0.46 \leq \hat{p} \leq 0.5)\) 일 확률을 구해야 한다.
표본비율의 평균, 분산, 표준편차는 \(p = 0.4, q = 0.6, n = 94\) 이므로 다음이 성립한다.
\[ E(\hat{p}) = p = 0.4 \]\[ V(\hat{p}) = \dfrac{pq}{n} = \dfrac{0.4 \times 0.6}{94} = \dfrac{1}{400} \]\[ \sigma (\hat{p}) = \sqrt[]{V(\hat{p})} = \sqrt[]{\dfrac{1}{400}} = \dfrac{1}{20} = 0.05\]\(n\) 이 \(94\) 로 충분히 크므로 확률변수 \(X\) 는 정규분포를 따르고 그것의 실수배인 확류변수 \(\hat{p} = \dfrac{X}{n}\) 도 정규분포를 따른다. 그러므로 표준화하여 새로운 확률변수 \(Z = \dfrac{\hat{p} - 0.4 }{0.05 }\) 를 만들면 다음이 성립한다.
\[ \begin{align}\begin{split} P(0.46 \leq \hat{p} \leq 0.5) &= P \bigg ( \dfrac{0.46 - 0.4}{0.05} \leq Z \leq \dfrac{0.5-0.4}{0.05} \bigg ) \\ &= P(1.2 \leq Z \leq 2) = P(0 \leq Z \leq 2) - P(0 \leq Z \leq 1.2) \\ &= 0.4772 - 0.3849 = 0.0923 \\ \end{split}\end{align} \tag*{} \]따라서 이 고등학교 학생 중에서 \(96\) 명을 임의추출했을 때 바로 취직할 학생이 \(46\%\) 이상 \(50\%\) 이하일 확률은 약 \(9.2\%\) 이다.
Estimation✔
추정(estimation)
표본에서 얻은 결과를 이용하여 모집단의 평균, 표준편차 등을 추측하는 것이다.
- 표본평균과 표본비율의 평균, 분산, 표준편차 에서는 모집단의 평균, 분산, 표준편차로부터 표본평균의 평균, 분산, 표준편차를 구해보았다. 하지만 이제 표본으로부터 모집단의 성질을 추측해본다. 이것이 추정이다. 모집단을 전수조사하기에는 비용이 너무 많이 들기에 표본을 추출하여 조사하고 모집단의 속성을 추정하는 것이다.
점추정(point estimation)
추정의 방법 중 하나로써 그 값을 직접 추정하는 것이다.
- 통계학에서는 모집단으로부터 표본을 추출하고 추출된 표본의 통계량(표본평균, 표본표준편차)을 통하여 모수(모평균, 모표준편차)를 추정한다. 그 이유는 모집단을 전수조사하기에는 시간과 비용이 너무 많이 들기 때문이다. 이때 모수를 직접적인 값으로 추정하는 것을 점추정이라고 한다.
구간추정(interval estimation)
추정의 방법 중 하나로써 그 값이 포함되어 있을 구간을 추정하는 것이다.
-
점추정으로 모수(모평균, 모표준편차)를 추정해도 그 값이 얼마나 정밀한지 알 수 없으므로 구간추정을 통하여 모수가 어떤 구간에 속할지 조사하기도 한다.
가장 대표적인 구간추정은 \(95\%\) 신뢰도의 신뢰구간으로써 이 신뢰구간은 실제 모평균이 그 구간 내에 있을 가능성이 \(95\%\) 임을 알려준다.
신뢰도(confidence coefficient)
표본평균의 분포로부터 모평균이 포함될 구간을 얻을 때 그 구간에 모평균이 포함될 확률이다.
Estimation of Population Mean✔
모평균의 신뢰구간(confidence interval)
정규분포 \(N(\mu , \sigma ^{2})\) 을 따르는 모집단에서 임의추출한 크기가 \(n\) 인 표본의 표본평균을 \(\bar{X}\) 이라 할 때 정규화된 확률변수 \(Z = \dfrac{\bar{X} - \mu }{\dfrac{\sigma }{\sqrt[]{n}}}\) 에 대하여 모평균의 신뢰구간은 다음과 같다.
-
신뢰도 \(95\%\) 의 신뢰구간 : \(\bigg [ \bar{X} - 1.96 \dfrac{\sigma }{\sqrt[]{n}}, \bar{X} + 1.96 \dfrac{\sigma }{\sqrt[]{n}} \bigg ]\)
-
신뢰도 \(99\%\) 의 신뢰구간 : \(\bigg [ \bar{X} - 2.58 \dfrac{\sigma }{\sqrt[]{n}}, \bar{X} + 2.58 \dfrac{\sigma }{\sqrt[]{n}} \bigg ]\)
-
신뢰도 \(\alpha \%\) 의 신뢰구간 : \(\bigg [ \bar{X} - k \dfrac{\sigma }{\sqrt[]{n}}, \bar{X} + k \dfrac{\sigma }{\sqrt[]{n}} \bigg ]\)
-
모평균의 신뢰구간은 모평균 \(\mu\) 이 존재할 것으로 추정되는 구간이다.
-
정규분포 \(N(\mu , \sigma ^{2})\) 을 따르는 모집단에서 크기가 \(n\) 인 표본을 임의추출할 때 표본평균 \(\bar{X}\) 는 정규분포 \(N \bigg (\mu , \dfrac{\sigma ^{2}}{n} \bigg )\) 을 따른다. 따라서 \(\bar{X}\) 를 표준화한 확률변수 \(Z = \dfrac{\bar{X}- \mu }{\dfrac{\sigma }{\sqrt[]{n}}}\) 은 표준정규분포 \(N(0, 1)\) 을 따른다.
이때 모평균 \(\mu\) 을 신뢰도 \(95\%\) 로 추정하고 싶다고 하면 \(\mu\) 가 \(\bar{X}\) 을 표준화한 표준정규분포곡선에서 \(0.95\) 의 면적 내에 포함되어야만 한다. 표준정규분포표에 의하여 다음을 얻을 수 있다.
\[ \begin{align}\begin{split} 0.95 &= P(-1.96 \leq Z \leq 1.96) \\ &=P \Bigg ( -1.96 \leq \dfrac{\bar{X}- \mu }{\dfrac{\sigma }{\sqrt[]{n}}} \leq 1.96 \Bigg ) \\ &=P(\bar{X} - 1.96 \dfrac{\sigma }{\sqrt[]{n}} \leq \mu \leq \bar{X} + 1.96 \dfrac{\sigma }{\sqrt[]{n}}) \end{split}\end{align} \tag*{}\]즉, 모평균 \(\mu\) 가 다음과 같은 구간에 포함될 확률이 \(95\%\) 이다.
\[\bigg [ \bar{X} - 1.96 \dfrac{\sigma }{\sqrt[]{n}}, \bar{X} + 1.96 \dfrac{\sigma }{\sqrt[]{n}} \bigg ]\]그러므로 구간을 모평균 \(\mu\) 에 대한 신뢰도 \(95\%\) 의 신뢰구간이라 하는 것이다.
모평균 \(\mu\) 을 신뢰도 \(99\%\) 로 추정하고 싶다고 하면 \(\mu\) 가 \(\bar{X}\) 을 표준화한 표준정규분포곡선에서 \(0.99\) 의 면적 내에 포함되어야만 한다. 같은 방법으로 모평균 \(\mu\) 가 다음과 같은 구간에 포함될 확률이 \(99\%\) 라는 것을 알 수 있다.
\[\bigg [ \bar{X} - 2.58 \dfrac{\sigma }{\sqrt[]{n}}, \bar{X} + 2.58 \dfrac{\sigma }{\sqrt[]{n}} \bigg ]\]같은 방법으로 임의의 신뢰도 \(\alpha\%\) 의 신뢰구간도 다음과 같이 쉽게 구할 수 있다.
\[ P(-k \leq Z \leq k) = \dfrac{\alpha }{100} \implies \\ \bar{X} - k \dfrac{\sigma }{\sqrt[]{n}} \leq \mu \leq \bar{X} + k \dfrac{\sigma }{\sqrt[]{n}} \iff \bigg [ \bar{X} - k \dfrac{\sigma }{\sqrt[]{n}}, \bar{X} + k \dfrac{\sigma }{\sqrt[]{n}} \bigg ] \] -
모표준편차 \(\sigma\) 가 주어지지 않은 경우 표본의 크기 \(n\) 이 충분히 클 때, 즉 \(n \geq 30\) 일 때 표본표준편차 \(S\) 를 사용할 수 있다.
-
그런데 표본평균 \(\bar{X}\) 는 확률변수로써 다양한 값을 가질 수 있다. 왜냐하면 추출되는 표본은 매번 달라질 수 있고 이에따라 그 표본에 대한 평균인 표본평균 \(\bar{X}\) 도 달라질 수 있기 때문이다. 이것은 모평균 \(\mu\) 가 \(\alpha \%\) 의 확률로 포함될 수 있는 신뢰구간
\[ \bigg [ \bar{X} - k \dfrac{\sigma }{\sqrt[]{n}}, \bar{X} + k \dfrac{\sigma }{\sqrt[]{n}} \bigg ] \]이 표본에 따라 매번 달라질 수 있다는 것이다. 이것은 크기가 \(n\) 인 표본을 여러 번 추출하여 신뢰구간을 만들었을 때 그 신뢰구간들 중 \(\alpha \%\) 가 모평균 \(\mu\) 을 포함한다는 뜻이다.
-
예시
어떤 학교 학생의 키는 표준편차가 \(3\text{ cm }\) 인 정규분포를 따른다. 학생 \(36\) 명을 임의추출하여 키를 측정했더니 평큔 키가 \(175 \text{ cm }\) 였다. 전교생 키의 평균 \(\mu\) 의 신뢰도 \(95\%\) 신뢰구간과 신뢰도 \(99\%\) 신뢰구간을 구해보자.
모평균 \(\mu\) 의 신뢰도 \(95\%\) 신뢰구간은
\[ \bar{X} - 1.96 \dfrac{\sigma }{\sqrt[]{n}} \leq \mu \leq \bar{X} + 1.96 \dfrac{\sigma }{\sqrt[]{n}} \]이고 \(\bar{X} = 175, \sigma = 3, n = 36\) 이므로 다음을 얻는다.
\[ \iff 175 - 1.96 \dfrac{3 }{\sqrt[]{36}} \leq \mu \leq 175 + 1.96 \dfrac{3 }{\sqrt[]{36}} \]\[ \iff 174.02 \leq \mu \leq 175.98 \]따라서 모평균이 \(95\%\) 확률로 속할 구간은 \([174.02, 175.98]\) 이다.
모평균 \(\mu\) 의 신뢰도 \(99\%\) 신뢰구간은
\[ \bar{X} - 2.58 \dfrac{\sigma }{\sqrt[]{n}} \leq \mu \leq \bar{X} + 2.58 \dfrac{\sigma }{\sqrt[]{n}} \]이고 \(\bar{X} = 175, \sigma = 3, n = 36\) 이므로 다음을 얻는다.
\[ \iff 175 - 2.58 \dfrac{3 }{\sqrt[]{36}} \leq \mu \leq 175 + 2.58 \dfrac{3 }{\sqrt[]{36}} \]\[ \iff 173.71 \leq \mu \leq 176.29 \]따라서 모평균이 \(99\%\) 확률로 속할 구간은 \([173.71, 176.29]\) 이다.
모평균의 신뢰구간 길이
모평균의 신뢰구간으로부터 모평균 \(\mu\) 의 신뢰구간 길이는 다음과 같다.
-
신뢰도 \(95\%\) 의 신뢰구간 길이 : \(\displaystyle 2 \times 1.96 \dfrac{\sigma }{\sqrt[]{n}}\)
-
신뢰도 \(99\%\) 의 신뢰구간 길이 : \(\displaystyle 2 \times 2.58 \dfrac{\sigma }{\sqrt[]{n}}\)
-
신뢰도 \(\alpha \%\) 의 신뢰구간 길이 : \(\displaystyle 2 \times k \dfrac{\sigma }{\sqrt[]{n}}\)
-
증명
신뢰도 \(95\%\) 의 신뢰구간은 폐구간 \(\bigg [ \bar{X} - 1.96 \dfrac{\sigma }{\sqrt[]{n}}, \bar{X} + 1.96 \dfrac{\sigma }{\sqrt[]{n}} \bigg ]\) 이다. 그러므로 길이는 다음과 같다.
\[\bigg | \bigg ( \bar{X} - 1.96 \dfrac{\sigma }{\sqrt[]{n}} \bigg ) - \bigg ( \bar{X} + 1.96 \dfrac{\sigma }{\sqrt[]{n}} \bigg ) \bigg | = 2 \times 1.96 \dfrac{\sigma }{\sqrt[]{n}} \]마찬가지로 신뢰도 \(99\%\) 의 신뢰구간은 폐구간 \(\bigg [ \bar{X} - 2.58 \dfrac{\sigma }{\sqrt[]{n}}, \bar{X} + 2.58 \dfrac{\sigma }{\sqrt[]{n}} \bigg ]\) 이다. 그러므로 길이는 다음과 같다.
\[\bigg | \bigg ( \bar{X} - 2.58 \dfrac{\sigma }{\sqrt[]{n}} \bigg ) - \bigg ( \bar{X} + 2.58 \dfrac{\sigma }{\sqrt[]{n}} \bigg ) \bigg | = 2 \times 2.58 \dfrac{\sigma }{\sqrt[]{n}} \tag*{■} \] -
표본들의 평균과 표준편차가 비슷하다면 신뢰구간의 폭은 표본의 크기 \(n\) 에 영향을 받는다. 표본의 크기 \(n\)이 크다면 신뢰구간이 작아져서 모평균을 정밀하게 추정할 수 있고 \(n\) 이 작다면 신뢰구간이 커져서 모평균을 예측하기가 힘들어진다.
-
예시
어떤 모집단에서 다음과 같은 표본 \(3\) 개를 추출했다고 하자.
-
표본 \(1\) 은 크기 \(n=16\), 평균 \(\bar{X} = 98\), 표준편차 \(\sigma =24\) 를 가진다.
-
표본 \(2\) 은 크기 \(n=64\), 평균 \(\bar{X} = 96\), 표준편차 \(\sigma =24\) 를 가진다.
-
표본 \(3\) 은 크기 \(n=9\), 평균 \(\bar{X} = 97\), 표준편차 \(\sigma =24\) 를 가진다.
이때 각각의 표본들에서 모평균 \(\mu\) 이 포함될 \(95\%\) 신뢰구간은 다음과 같다.
-
표본 \(1\) 의 \(95\%\) 신뢰구간: \(98 \pm 1.96 \dfrac{24}{\sqrt[]{16}} = [86.2, 109.8]\)
-
표본 \(2\) 의 \(95\%\) 신뢰구간: \(96 \pm 1.96 \dfrac{24}{\sqrt[]{64}} = [90.1, 101.9]\)
-
표본 \(2\) 의 \(95\%\) 신뢰구간: \(97 \pm 1.96 \dfrac{24}{\sqrt[]{9}} = [81.3, 112.7]\)
이때 각각의 신뢰구간 길이는 표본 \(1\) 이 약 \(23.6\), 표본 \(2\) 가 약 \(11.8\), 표본 \(3\) 이 약 \(31.4\) 이다. 표본 \(2\) 의 신뢰구간 폭이 가장 좁으므로 표본의 크기가 가장 큰 표본 \(2\) 를 사용하여 모평균이 있을 구간을 추정한 신뢰구간이 가장 정밀한 추정이라고 할 수 있다.
-
Estimation of Population Ratio✔
모비율의 신뢰구간
모집단에서 임의추출한 크기가 \(n\) 인 표본의 표본비율을 \(\hat{p}\) 이라 할 때 충분히 큰 \(n\) 과 \(\hat{q} = 1 - \hat{p}\) 와 정규화된 확률변수 \(Z = \dfrac{\hat{p}- p }{\sqrt{\dfrac{pq}{n}}}\) 에 대하여 모비율의 신뢰구간은 다음과 같다.
-
신뢰도 \(95\%\) 의 신뢰구간 : \(\left [ \hat{p} - 1.96 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}, \hat{p} + 1.96 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \right ]\)
-
신뢰도 \(99\%\) 의 신뢰구간 : \(\left [ \hat{p} - 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}, \hat{p} + 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \right ]\)
-
신뢰도 \(\alpha \%\) 의 신뢰구간 : \(\left [ \hat{p} - k \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}, \hat{p} + k \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \right ]\)
-
모비율의 신뢰구간은 모비율 \(p\) 가 존재할 것으로 추정되는 구간이다.
-
표본평균의 분포로 모평균의 신뢰구간을 추정한 것처럼 표본비율의 분포로 모비율에 대한 신뢰구간을 추정할 수 있다.
-
모비율이 \(p\) 인 모집단에서 크기가 \(n\) 인 표본을 임의추출 했을 때 표본의 크기 \(n\) 이 충분히 크면 표본비율 \(\hat{p} = \dfrac{X}{n}\) 는 근사적으로 정규분포 \(q = 1 - p\) 에 대하여 \(N \bigg ( p, \dfrac{pq}{n} \bigg )\) 를 따른다. 따라서 \(\hat{p}\) 를 표준화한 확률변수 \(Z = \dfrac{\hat{p}- p }{\sqrt{\dfrac{pq}{n}}}\) 은 표준정규분포 \(N(0, 1)\) 을 따른다.
또한 모표준편차를 모를 때 표본의 크기 \(n\) 이 충분히 크다면 표본표준편차를 사용해도 되므로 \(\hat{p}\) 의 표준편차 \(\sigma (\hat{p}) = \sqrt[]{\dfrac{pq}{n}}\) 에서 \(p, q\) 대신 \(\hat{p}, \hat{q}\) 를 대입한 \(\sigma (\hat{p}) = \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}\) 도 표준정규분포 \(N(0, 1)\) 을 따른다. 그러므로 \(Z = \dfrac{\hat{p}- p }{\sqrt{\dfrac{\hat{p}\hat{q}}{n}}}\) 를 사용해도 된다.
모비율 \(p\) 을 신뢰도 \(95\%\) 로 추정하고 싶다고 하자. \(Z = \dfrac{\hat{p}- p }{\sqrt{\dfrac{\hat{p}\hat{q}}{n}}}\) 에 대하여 다음이 성립한다.
\[ \begin{align}\begin{split} 0.95 &= P(-1.96 \leq Z \leq 1.96) \\ &= P \left( -1.96 \leq \dfrac{\hat{p}- p }{\sqrt{\dfrac{\hat{p}\hat{q}}{n}}} \leq 1.96 \right ) \\ &= P \left(\hat{p} - 1.96 \sqrt{\dfrac{\hat{p}\hat{q}}{n}} \leq p \leq \hat{p} + 1.96 \sqrt{\dfrac{\hat{p}\hat{q}}{n}} \right) \\ \end{split}\end{align} \tag*{}\]따라서 모비율 \(p\) 이 구간 \(\bigg [ \hat{p} - 1.96 \sqrt{\dfrac{\hat{p}\hat{q}}{n}}, \hat{p} + 1.96 \sqrt{\dfrac{\hat{p}\hat{q}}{n}} \bigg ]\) 에 포함될 확률이 \(0.95\) 이다. 이 구간을 모비율 \(p\) 에 대한 신뢰도 \(95\%\) 의 신뢰구간이라 하는 것이다.
모비율 \(p\) 을 신뢰도 \(99\%\) 에 대한 신뢰구간과 임의의 신뢰도 \(\alpha\%\) 에 대한 신뢰구간도 다음과 같은 방법으로 쉽게 구할 수 있다.
\[ P(-2.58 \leq Z \leq 2.58) = 0.95 \implies \\ \hat{p} - 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \leq p \leq \hat{p} + 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \iff \left [ \hat{p} - 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}, \hat{p} + 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \right ] \]\[ P(-k \leq Z \leq k) = \dfrac{\alpha }{100} \implies \\ \hat{p} - k \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \leq p \leq \hat{p} + k \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \iff \left[ \hat{p} - k \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}, \hat{p} + k \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \right ] \] -
예시
어떤 커뮤니티에서 회원들이 관심있는 분야를 조사하기 위하여 회원 \(300\) 명을 임의추출하여 설문조사를 했더니 \(75\) 명이 "의류" 에 관심이 있다고 응답했다. 전체 회원 중에서 의류에 관심있는 회원의 비율을 \(p\) 라고 할 때 모비율 \(p\) 의 신뢰구간을 추정해보자.
신뢰도 \(95\%\) 의 신뢰구간을 추정해보면 다음과 같다.
\[ \hat{p} - 1.96 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \leq p \leq \hat{p} + 1.96 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \]에서 표본의 크기가 \(n = 300\) 이고 표본비율 \(\hat{p} = \dfrac{75}{300} = 0.25\) 인데 표본의 크기가 충분히 크므로(\(n > 30\)) \(\hat{q} = 1 - \hat{p} = 0.75\) 에 대하여
\[ \iff 0.25 - 1.96 \sqrt[]{\dfrac{0.25\times 0.75}{300}} \leq p \leq 0.25 + 1.96 \sqrt[]{\dfrac{0.25\times 0.75}{300}} \]\[ \iff 0.201 \leq p \leq 0.229 \]이다. 따라서 신뢰도 \(95\%\) 의 신뢰구간은 \([0.201 \leq p \leq 0.229 ]\) 이다. 이로써 전체 회원 중에서 "의류" 에 관심이 있는 회원의 비율은 \(95\%\) 의 확률로 \(20.1\%\) 에서 \(22.9\%\) 사이값이라고 생각할 수 있다.
신뢰도 \(99\%\) 의 신뢰구간을 추정해보면 다음과 같다.
\[ \hat{p} - 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \leq p \leq \hat{p} + 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \]\[ \iff 0.25 - 2.58 \sqrt[]{\dfrac{0.25\times 0.75}{300}} \leq p \leq 0.25 + 1.96 \sqrt[]{\dfrac{0.25\times 0.75}{300}} \]\[ \iff 0.1855 \leq p \leq 0.3145 \]이다. 따라서 신뢰도 \(99\%\) 의 신뢰구간은 \([0.1855 \leq p \leq 0.3145 ]\) 이다. 이로써 전체 회원 중에서 "의류" 에 관심이 있는 회원의 비율은 \(99\%\) 의 확률로 \(18.5\%\) 에서 \(31.4\%\) 사이값이라고 생각할 수 있다.
그러나 이처럼 모평균에 대한 추정 확률이 높아질수록 구간추정의 정밀도가 떨어진다. 따라서 통상적으로(특히 보건업계에서) 신뢰도 \(95\%\) 의 신뢰구간을 널리 사용한다.
모비율의 신뢰구간 길이
모비율의 신뢰구간으로부터 모비율 \(p\) 의 신뢰구간 길이는 다음과 같다.
-
신뢰도 \(95\%\) 의 신뢰구간 길이 : \(\displaystyle 2 \times 1.96 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}\)
-
신뢰도 \(99\%\) 의 신뢰구간 길이 : \(\displaystyle 2 \times 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}\)
-
신뢰도 \(\alpha \%\) 의 신뢰구간 길이 : \(\displaystyle 2 \times k \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}\)
-
증명
신뢰도 \(95\%\) 의 신뢰구간은 폐구간 \(\bigg [ \hat{p} - 1.96 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}, \hat{p} + 1.96 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \bigg ]\) 이다. 그러므로 길이는 다음과 같다.
\[\bigg | \bigg ( \hat{p} - 1.96 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \bigg ) - \bigg ( \hat{p} + 1.96 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \bigg ) \bigg | = 2 \times 1.96 \sqrt{\dfrac{\hat{p}\hat{q}}{n}}\]마찬가지로 신뢰도 \(99\%\) 의 신뢰구간은 폐구간 \(\bigg [ \hat{p} - 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}}, \hat{p} + 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \bigg ]\) 이다. 그러므로 길이는 다음과 같다.
\[\bigg | \bigg ( \hat{p} - 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \bigg ) - \bigg ( \hat{p} + 2.58 \sqrt[]{\dfrac{\hat{p}\hat{q}}{n}} \bigg ) \bigg | = 2 \times 2.58 \sqrt{\dfrac{\hat{p}\hat{q}}{n}} \tag*{■} \]