Nand2tetris
Contents
어떤 것을 이해하는 가장 좋은 방법 중 하나는 그것의 단순하지만 충분히 강력한 형태를 밑바닥에서 만들어보는 것이다.
--- Hardware ---✔
다음과 같은 java 프로그램은 단순한 문자열을 출력한다.
위와 같은 프로그램이 실행될 때 컴퓨터에서 실제로 어떤 일이 일어나는지 이해하려 한다.
프로그램은 무의미한 기호열이 저장된 텍스트 파일에 불과하다. 그러므로 프로그램을 실행하려면 그것을 파싱하고, 문법을 분석하여, 컴퓨터의 기계어의 문법으로 표현된 기계어로 재표현해야 한다. 이 변환을 컴파일이라고 한다. 기계어는 이진 코드 집합이고, 이것은 하드웨어의 구조에 따라 결정된다. 하드웨어는 레지스터, 메모리 유닛, 덧셈기(adder) 등 칩들의 집합이고, 이 모든 것은 기초 논리 게이트로 구성된다. 이 모든 게이트들은 \(\operatorname{Nand}\) 나 \(\operatorname{Nor}\) 같은 원시 게이트로 구성될 수 있다. 이 게이트들은 몇가지 트랜지스터로 구현되는 스위칭 기기들로 만들어진다. 이 트랜지스터들의 구현에 대하여 논한다면, 컴퓨터 공학의 영역이 끝나고 물리학이 시작된다.
PC, 스마트폰, 서버 등 모든 컴퓨터는 기초 논리 게이트를 기반으로 세워졌다. \(\operatorname{Nand}\) 게이트는 현실에서 널리 사용된다. 하드웨어 플랫폼과 소프트웨어 위계가 어떻게 구성되었든지, 그 모든 것들은 같은 아이디어와 같은 기술을 기반으로 한다.

위와 같이 사람의 생각이 프로그램으로 변환되고, 컴파일러가 프로그램을 기계어로 변환하면, 컴퓨터가 기계어를 실행한다. 화살표는 각 레벨이 하위 레벨로 구현되었다는 것을 의미한다. 가령, 프로그램은 VM 코드 집합으로 구성되고, VM 명령들은 기계 명령어 집합으로 구성되고, 기계 명령어는 마이크로 코드로 구성된다는 식이다.
처치-튜링 추측(Church-Turing conjecture)는 모든 컴퓨터가 본질적으로 동등하다는 컴퓨터 공학의 원리이다. 이는 우리의 접근법이 일반적이라는 것을 보장해준다. 우리가 이해하는 개념은 다른 모든 컴퓨터의 하드웨어와 소프트웨어에도 적용되는 본질적으로 같은 개념이다.
보통 컴퓨터 시스템은 top-down 으로 설명된다. 이 방식은 그것의 고레벨 구현을 소개하고 이진 기계 명령어가 어떻게 마이크로 코드로 분해되어 컴퓨터 구조로 입력되며, 그것이 하드웨어 내부의 선들로 입력되어 ALU 와 RAM 칩들을 조작하는지 설명하는 방식이다. 하지만 지금은 down-top 방식으로 컴퓨터를 이해해보자. ALU 와 RAM 이 어떻게 마이크로 코드를 입력받아서 실행하는지, 그리고 그것이 어떻게 이진 기계 명령어를 구성하는지의 순서로 공부하는 것이다.
하드웨어 플랫폼은 논리 게이트와 칩의 집합을 기반으로 하는데, 모든 게이트와 칩들은 HDL(Hardware Description Language)을 사용하여 만들어진다. 하드웨어 설계자들도 이 언어로 하드웨어를 설계하고 그것의 타당성을 소프트웨어로 검증한다. HDL 로 설계된 하드웨어를 입력받아서 그것을 곧장 로봇 팔이나 3D 프린터 같은 물리적 출력기를 지녀서 물리적으로 출력해줄 수 있는 컴퓨터가 있다면, HDL 프로그램을 생성하여 물리적 구현체까지도 만들어낼 수 있다.
소프트웨어 플랫폼은 하드웨어 플랫폼의 정점에 세워진 대상들의 집합으로 이루어질 것이다. 그리고 그렇게 세워진 가장 저레벨 소프트웨어 플랫폼이 제공하는 블록들의 집합으로 고레벨 소프트웨어들이 만들어진다.
이때 중요한 것은 추상화이다. 어떻게 컴퓨터가 작동하는지, 어떻게 복잡한 문제를 작은 모듈로 나누어 관리할 수 있는지, 어떻게 대규모 하드웨어와 소프트웨어를 개발할 수 있는지 배워야 한다. 컴퓨터를 만들 때 컴퓨터를 이루는 계층을 추상화시켜서 만들게 된다. 이 추상화가 주는 효용은 각각의 계층을 독립적으로 다룰 수 있게 된다는 것이다. 이로써 하드웨어 → 소프트웨어 라는 순서로 컴퓨터를 설계하지 않아도 된다. 임의의 순서로 각각의 계층을 설계할 수 있고 이해할 수 있다. 이로써 우리는 다른 계층을 전혀 걱정하지 않고 독립적으로 우리가 신경쓰고 있는 계층의 설계에만 집중할 수 있게 된다. 하지만 추상적 계층을 잘 분리시켜서 시스템을 설계하는 것은 전적으로 경험 학문이라서, 많은 예시를 봐야 하고 많은 경험을 직접 해보아야 한다.
Boolean Logic✔
컴퓨터, 스마트폰, 네트워크 라우터 같은 모든 디지털 기기는 이진 정보를 저장하고 처리하도록 설계된 칩의 집합이다. 이 칩들의 모양과 형태가 달라도, 그것은 모두 논리 게이트라는 블록의 집합이다. 게이트는 물리적으로 다양한 기술에 의하여 구현될 수 있다. 실제로 논리 게이트를 물이나 흙이나 나무로도 설계할 수 있지만, 현재로써 가장 효율적인 것이 전자공학으로 논리 게이트를 설계하는 것이므로 논리 게이트의 밑에는 전자 공학 기술이 있다.
이제 Nand 게이트를 기반으로 다른 논리 게이트를 설계하고, 우리가 만들 컴퓨터가 16비트 값을 연산하므로 기본 게이트들의 16비트 버전도 설계할 것이다.
먼저 불 대수(boolean algebra)와 불 함수(boolean function)를 알아보자. 불 대수는 이진값을 다루는데, 이 값은 true/false, yes/no, on/off, 1/0 으로도 나타낼 수 있다. (참고로, 이 값은 실제 트랜지스터에서는 5v/1v 가 된다.) 불 함수는 \(n\)개의 이진값을 \(m\)개의 이진값으로 보내는 함수이다.
불 함수(boolean function)
불 함수 \(f\) 는 다음과 같이 정의되는 다변수 벡터함수이다.
이 불 함수가 논리 게이트로 구현되므로 불 함수를 설계하는 것이 하드웨어 설계의 시작이다.

위 그림은 모든 불 함수 \(\{0,1\}^{2}\to \{0,1\}\) 를 빠짐없이 나열한다. 일반적으로 \(n\)변수 불 함수의 수는 \(2 ^{2 ^{n}}\) 이다. 위 함수 중 중요한 함수는 \(\operatorname{And}\), \(\operatorname{Or}\), \(\operatorname{Not}\) 이다. 1차 논리 정리 1.5와 1.6에 의하여 이들의 집합과 부분집합이 모든 불 함수를 표현하는데에 충분하기 때문이다. 그러나 1.7은 \(\operatorname{Nand}\) 함수 단 하나만으로 임의의 모든 불 함수를 표현할 수 있다는 것을 말해준다.
다시 본론으로 돌아와서, 불 함수의 설계가 하드웨어 설계의 시작이다. 불 함수의 정의의 시작은 모든 가능한 입력과 그에 따라 당신이 원하는 출력을 다음과 같은 진리표로 나열해보는 것이다.

위와 같이 정의된 불 함수는 \(f(x, y, z) = (x + y) \cdot \bar{z}\) 와 같이 정의된다. 이 형식화는 다음과 같은 과정으로 이루어진다.
- 함숫값이 \(1\) 인 경우만 가져오기.
- \(1\) 인 경우를 \(\operatorname{Or}\) 로 묶기.
- 최소 연산만 사용하도록 최적화하기.
이 경우에 적용해보면 다음과 같이 된다.
- \((0, 1, 0) \mapsto 1\), \((1, 0, 0) \mapsto 1\), \((1, 1, 0) \mapsto 1\) 이므로 각각 \(\bar{x}y \bar{z}, x \bar{y}\bar{z}, xy \bar{z}\) 이다.
- \(f(x, y, z) = \bar{x}y \bar{z} + x \bar{y}\bar{z} + xy \bar{z}\)
- \(\bar{x}y \bar{z} + x \bar{y}\bar{z} + xy \bar{z}= (x + y) \cdot \bar{z}\) 이므로 최종적으로 함수를 \(f(x, y, z) = (x + y) \cdot \bar{z}\) 와 같이 정의한다.
이 구성법으로 알 수 있는 중요한 결론은 불 함수가 아무리 복잡해도 모두 \(\operatorname{And}\), \(\operatorname{Or}\), \(\operatorname{Not}\) 으로 표현가능하다는 것이다.
진리표는 자연 대상의 상태를 나타내는데에 유용하고, 불 함수는 진리표를 단순화시키고 형식화시키는데에 유용하다. 이것은 진리표로 상태를 규명해낼 수 있는 모든 자연 대상을 기계화할 수 있다는 것을 의미한다. 그 범위가 어디까지일까? 기계화할 수 있는 대상의 범위에 대한 심도 깊은 논의가 필요하겠지만, 알파고 같은 인공지능도 이 범위에 포함되므로 기계화가능한 것이고, 자율주행차에 탑재된 운전 인공지능도 이 범위에 포함되므로 기계화된 것이며, 우리가 각자 떠올린 매우 복잡하고 매우 놀라운 프로그램들 모두가 불 함수로 표현가능하므로 기계화가능한 대상들인 것이다. 이러한 논리 게이트를 통하여 프로그래밍 가능한 보편 튜링 기계의 모든 부품이 구현 가능했던 것이다. 한편, 이 기계화가능성에 대하여 진짜 심도 깊은 논의와 고민을 함으로써 그 한계와 천장이 무엇인지 규명해두는 것이 필요해보인다.
Logic Gate✔
게이트는 불 함수의 물리적 구현체이다. 불 함수가 \(f: \{0,1\} ^{n} \to \{0,1\} ^{m}\) 로 정의되었다면 게이트는 \(n\) 개의 입력 핀과 \(m\) 개의 출력 핀으로 구현된다.
이것을 어떻게 구현할지는 현재로써 전자공학이 최선이지만 연구자들은 자기장으로, 광학적으로, 생물학적으로, 수력학적으로, 양자적으로 등으로 구현하면 더 효율적인지 연구하고 있다. 한편, 이 말은 컴퓨터 공학이 그 물리적 기반에 대하여 전혀 걱정할 필요가 없다는 것을 의미한다. 컴퓨터 공학자들은 그 물리적 계층이 구현한 불 대수와 논리 게이트의 추상 계층만 생각하면 된다. 현재 게이트는 전자공학으로 칩으로 포장된 트랜지스터들에 의하여 구현된다. 따라서 칩(chip)과 게이트(gate)라는 말을 혼용할 수 있다.

위와 같은 게이트가 원시 게이트(primitive gate)이고, 그 안의 구현은 물리학의 영역이다. 이것이 컴퓨터 공학의 밑바닥이다. 더 이상 내려가면 컴퓨터 공학의 영역이 아니다.
클로드 섀넌이 최초로 논리 게이트의 동작을 분석하는데에 불 대수를 사용했다. 사실은, 논리 추론이 몇가지 생각 패턴으로 이루어진다는 것을 눈치채고 체계의 완전성을 확립하여 기계에게 생각과 추론을 따라하게 하려는 시도는 힐베르트가 최초가 아니었다. 1600년대에 라이프니츠가 초보적으로 기호로 논리 추론의 패턴을 정의하려 했고, 1800년대에 프레게가 체계적인 표기법으로 논리 추론을 정리하며 추론 패턴을 찾으려 했다. 러셀이 프레게의 연구를 뒤이어 수학 원리에 수학의 모든 논리 체계를 엄밀하게 규명하려했고, 힐베르트는 이 모든 것을 기반으로 완전성을 증명하고 수학 전체를 규명할 수 있는 기계적인 패턴을 찾아서 공리와 추론규칙을 정립하려 했다.
1854년 불(Boole)은 사람의 생각이 조립되는 것으로 이해하고, 생각을 조립하기에 충분한 3가지 접속사를 \(\operatorname{And}\), \(\operatorname{Or}\), \(\operatorname{Not}\) 이라고 정의했다. 이것이 불 논리이다. 섀넌은 디지털 논리회로를 만들 때 사용되는 스위치들이 \(\operatorname{And}\), \(\operatorname{Or}\), \(\operatorname{Not}\) 의 개념에 대응된다는 것을 깨닫고 논리 게이트를 불 대수로 표현하기 시작했다. 그런데 이 논리 회로의 아이디어에서 나온 논리 게이트로 튜링기계의 모든 부품, 즉, 튜링기계의 규칙표대로 실행하는 장치, 메모리, 메모리를 읽고 쓰는 장치를 설계할 수 있었다. 컴퓨터도 튜링기계이므로 명제 논리의 문장(또는 진리표, 또는 불 함수)으로 표현가능한 모든 대상은 컴퓨터에서 만들고 실행가능하다. 튜링의 논문과 수리논리학의 계산가능성 파트를 살펴보면, 튜링 기계는 규칙표를 따라 테이프에 기호를 읽거나 쓰는 기계에 불과하다. 서로 동형인 불의 함수와 섀넌의 논리 게이트로 이 튜링 기계를 만들 수 있고, 튜링의 보편 기계의 결과물이 컴퓨터이다. 튜링의 논문의 마지막 부분에 뇌도 튜링 기계인가 라는 질문을 했다. 이것은 뇌도 스위치로 구성된 논리 게이트로 표현가능한가 라는 질문이다. 뇌는 뉴런이라는 신경세포로 구성되어 있는데, 이 뉴런은 매우 간단한 수학 함수로 표현되고, 컴퓨터 프로그램으로 기계화할 수 있다. 뇌도 튜링 기계이다.
Primitive and Composite Gates✔
모든 논리 게이트가 \(\operatorname{And}\), \(\operatorname{Or}\), \(\operatorname{Not}\) 으로 구성되지만, 이것을 합성하여
모든 논리 게이트가 \(\{0,1\}\) 라는 입출력을 가지므로 그것을 합성하여 좀 더 복잡한 다변수 함수를 만들어낼 수 있다. 가령 \(\text{And} : \{0, 1\} ^{2} \to \{0, 1\}\) 을 합성하여 다음과 같은 합성함수를 만들 수 있다.
이것은 결합법칙이 성립하기 때문에 가능하다. 그렇다면 컴퓨터 공학이 성립하게 된 대수구조(마그마, 반군, 모노이드, 군, 환, 가환환, 체, 순서체, 완비순서체 등)를 규명할 수 있다. 컴퓨터의 대수구조를 규명하면, 컴퓨터 위에 설계된 모든 것을 대수구조를 기반으로 형식화할 수 있다. 이것이 이루어지면 좋은 점은, 컴퓨터의 모든 것을 통일된 하나의 추상적 표현으로 표현가능하다는 것이다.(취약점에 관하여)
Xor 게이트는 다음과 같은 합성함수로 정의된다.

위 그림의 왼쪽 부분을 \(\operatorname{Xor}\) 의 인터페이스(interface), 오른쪽 부분을 구현(implementation)이라고 한다. 논리 게이트의 인터페이스는 유일하지만, 구현은 다양하다. 최대한 적은 게이트를 사용하는 방식으로 구현을 최적화시켜야 한다.
결론은 이것이다! 필요한 불 함수에 대응되는 게이트의 인터페이스를 만들고, 그것의 구현을 최적화시키는 방식으로 게이트를 구현하면 된다.
Hardware Description Language (HDL)✔
실제로 하드웨어를 설계할 때에는 위에서 했던 것처럼 수작업을 하지 않고 HDL 이라는 언어를 사용한다. 이 언어로 프로그램을 짜고 하드웨어를 가상으로 테스트를 해보는 것이다.
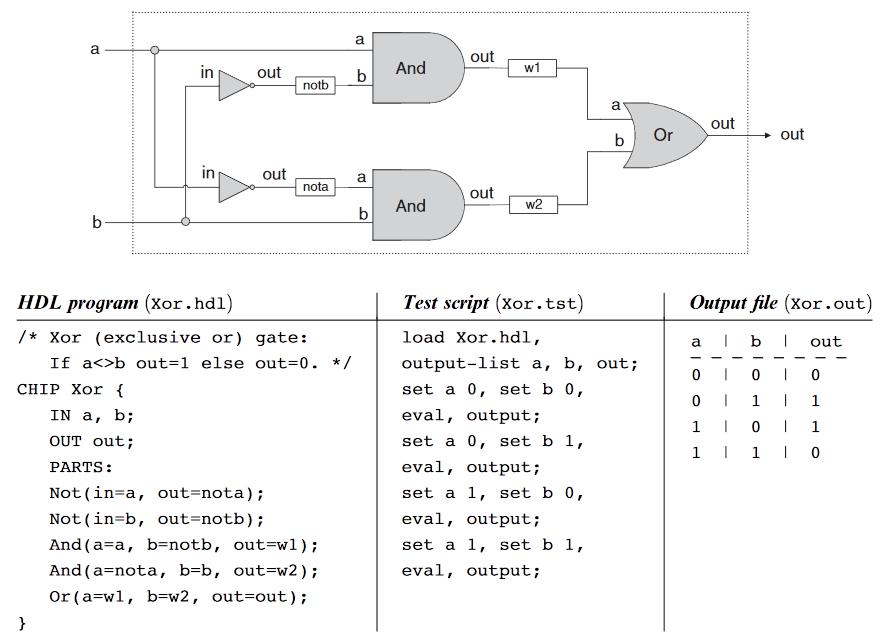
위와 같이 HDL 을 사용하여 Xor 게이트를 설계하고 테스트하는 것이다.
HDL 이 하드웨어 구현 언어이기 때문에 HDL 으로 프로그램을 짜고 디버깅하는 것은 소프트웨어에서 하던 그것과 매우 유사하다. 다만 차이점은 컴파일러를 사용하지 않고 하드웨어 시뮬레이터를 사용하여 디버깅하게 된다는 것이다.
Basic Gates✔
\(\operatorname{And}\), \(\operatorname{Or}\), \(\operatorname{Not}\) 의 설계는 1차 논리 정리 1.7에 의하여 \(\operatorname{Nand}\) 로부터 만들어지는 것으로써 자명하다.
이제 멀티플렉서(multiplexor)라는 개념을 알아야 하는데, 이는 입력 중 하나를 선택하여 출력하는 장치를 의미한다. 디멀티플렉서는(demultiplexor)는 여러개의 출력 중 하나를 선택하여 그곳으로 입력을 흘려보내주는 역할을 한다.
다음은 1비트 \(\operatorname{Mux}\) (multiplexor) 의 설계이다.

다음은 1비트 \(\operatorname{DMux}\) (demultiplexor)의 설계이다.

그러나 컴퓨터의 하드웨어의 아키텍처(architecture)가 실제로 저렇게 정직하게 1비트 연산만 하도록 설계되지는 않는다. 컴퓨터 하드웨어는 버스(bus)라고 부르는 multi-bit array 를 연산하도록 설계된다. 가령, 32비트 컴퓨터는 두 개의 32비트 버스 위에서 설계된 And 함수를 동작시킬 수 있다. 32비트 시스템에서는 게이트들이 32비트 입력 버스와 32비트 출력 버스를 갖도록 설계된다. 그러나 32비트 아키텍처에서는 4GB 메모리까지밖에 표현하지 못한다. \(2 ^{32} = 4,294,967,296\) 이기 때문에 하드웨어가 메모리 주소값을 입력하고 계산하고 출력하는 한계가 4GB 인 것이다. 따라서 최근의 컴퓨터들은 모두 64비트 아키텍처로 출시된다.
여기에서는 단순한 시스템을 설계할 것이기 때문에 16비트 아키텍처에서 설계되어 사용되는 16비트 논리 게이트를 정의한다.
다음은 16비트 \(\operatorname{Not}\) 의 설계이다.

다음은 16비트 \(\operatorname{And}\) 의 설계이다.

다음은 16비트 \(\operatorname{Or}\) 의 설계이다.

다음은 16비트 \(\operatorname{Mux}\) 의 설계이다.

일변수 또는 이변수 논리게이트는 다변수 논리게이트로 일반화될 수 있다.
다음은 8-way \(\operatorname{Or}\) 게이트의 설계이다.

다음은 4-way 16-bit \(\operatorname{Mux}\) 의 설계이다. m-way m-bit \(\operatorname{Mux}\) 의 선택 비트 sel 은 \(k = \log_{2} m\) 비트를 가진다. 4-way 이므로 선택 비트가 \(\log_{2} 4 = 2\) 로써 2비트가 된다.

우리가 설계하려는 하드웨어 플랫폼에서는 4-way 16-bit \(\operatorname{Mux}\) 와 8-way 16-bit \(\operatorname{Mux}\) 가 필요하다. 이 설계는 다음과 같다.

m-way n-bit \(\operatorname{DMux}\) 는 n비트의 입력을 m개의 출력중 하나로 흘려보내준다. 다음은 4-way \(\operatorname{DMux}\) 의 설계이다.

우리가 설계하려는 컴퓨터 플랫폼에서는 4-way 1-bit \(\operatorname{DMux}\) 와 8-way 1-bit \(\operatorname{DMux}\) 가 필요하다. 그 설계는 다음과 같다.

Implementation✔
수학에서의 공리처럼 기초 게이트들은 그것으로부터 만들어질 수 있는 모든 것의 기반이 된다. 지금은 기초 게이트(공리)로써 \(\operatorname{Nand}\) 만을 채택한다.
이 \(\operatorname{Nand}\) 로 다음과 같은 게이트를 구현할 것이다. 물론 게이트의 구현 방법은 어떤 정리를 증명하는 방법이 유일하지 않듯이 유일하지 않다. 더 간단할수록 좋은 구현(좋은 증명)이다.
- Not, And, Or/Xor, Multiplexor/Demultiplexor, Multi-Bit Not/And/Or, Multi-Bit Multiplextor, Multi-Way Gates
이것의 구현은 1차 논리 정리 1.7에서 나왔듯이 매우 쉽다. \(\operatorname{Xor}\) 과 \(\operatorname{Mux}\), \(\operatorname{DMux}\) 의 구현만 살펴보자.
CHIP Xor {
IN a, b;
OUT out;
PARTS:
Or(a=a, b=b, out=aorb);
Nand(a=a, b=b, out=anandb);
And(a=aorb, b=anandb, out=out);
}
CHIP Mux {
IN a, b, sel;
OUT out;
PARTS:
Not(in=sel, out=notsel);
And(a=notsel, b=a, out=sela);
And(a=sel, b=b, out=selb);
Or(a=sela, b=selb, out=out);
}
CHIP DMux {
IN in, sel;
OUT a, b;
PARTS:
Not(in=sel, out=notsel);
And(a=notsel, b=in, out=a);
And(a=sel, b=in, out=b);
}
물론 우리가 공리로 \(\operatorname{Nand}\) 를 채택한 것처럼 다른 공리체계를 기반으로 컴퓨터를 설계할 수도 있다. 가령 \(\operatorname{Nor}\) 게이트만으로도 완전한 컴퓨터를 구성해낼 수 있다. 이것은 기하학에서 다른 공리를 채택하여 기하학 체계의 정리들을 도출해내는 것과 이론적으로 동치이다.
그러면 우리가 어떤 프로그램을 만들고자 했을 때 그 프로그램을 "증명 대상" 라고 할 수 있겠고 우리가 사용할 수 있는 레고 블럭들을 "공리" 와 "정리" 라고 할 수 있다.
이로써 애초에 컴퓨터 프로그램을 만드는 것은 하드웨어 설계자가 제공하는 공리와 정리들을 사용하는 것임을 알 수 있다. 그런데도 우리는 하드웨어가 제공하는 공리와 정리를 사용하는 것이 아니라 이미 그 위에 많이, 그리고 높이 쌓여있는 잘 마련된 정리를 사용한다. 즉, syscall 을 사용하여 프로그래밍을 하는 것이 아니라 print 함수를 사용하여 프로그래밍을 한다.
그러면 컴퓨터는 완전 체계이고, 어떤 프로그램에 정의한 대상이 유일하다고 잘못 가정한 곳이 있다면 그 잘못 가정한 것에 대한 증명, 즉 완전 체계 내에서의 증명 시도 및 증명 가능성을 곧 "취약점" 으로 정의할 수 있고, 그것을 익스플로잇 하는 것을 "해킹" 으로 정의할 수 있다.
이것은 상당한 효용을 가져다 주는데 섀넌이 정보를 수학으로 형식화했었듯 해킹이나 취약점 같은 게 수학적으로 형식화되기 때문이다. 수학적으로 형식화된 대상은 기계적으로 다룰 수도 있다.
Boolean Arithmetic✔
이제 산술을 구현할 수 있는 칩 집합을 만들어야 한다. 산술 체계를 구현하려면 먼저 수를 표현할 수 있어야 하고, 산술 체계에 정의된 연산을 수행할 수 있어야 한다. 산술 연산을 수행하는 칩을 ALU 라고 하는데, 이 ALU 가 컴퓨터의 모든 명령어를 실행하는 CPU 의 계산의 중심이 된다.
Arithmetic Operations✔
컴퓨터 체계는 최소한 singed(부호 있는, 즉, 양수이거나 음수일 수 있는) 정수 데이터에 대한 다음과 같은 연산을 수행하도록 설계된다.
- 덧셈, 부호 변환(sign conversion), 뺄셈, 비교, 곱셈, 나눗셈
그런데 나머지 모든 산술 연산은 덧셈과 부호 변환이라는 2가지 빌딩 블록 위에서 구현된다. 덧셈은 컴퓨터 과학과 수학에서 단순하지만 깊은 의미를 갖는다. 디지털 컴퓨터에 의하여 수행되는 모든 함수는 이진수의 덧셈으로 환원되기 때문이다. 그러므로 이진수 덧셈의 설계를 이해하는 것이 컴퓨터 하드웨어에 의하여 수행되는 연산의 근본을 이해하는 것이다.
이진수를 이해하기 위하여 먼저 우리가 사용하는 10진수를 살펴보자. 10진수는 \(10\) 을 기반으로 숫자를 표현한다. 가령 \(6083\) 은 다음과 같이 10진수로 표현된다.
이진수는 \(2\) 를 기반으로 숫자를 표현한다. 가령, \(19\) 는 다음과 같이 이진수로 표현된다.
컴퓨터 안에서는 모든 것이 이진코드로 표현된다. 키보드 키 1, 9, Enter, 그리고 컴퓨터에 저장된 \(19\) 라는 수까지 모두 컴퓨터 안에서 이진코드로 저장된다. 컴퓨터는 이진코드로 저장된 10011 을 계산하여 이것이 \(19\) 에 해당하는 수라고 결론 내리고, 현재 폰트에 해당하는 비트맵 이미지로 1 과 9 라는 기호를 모니터에 출력한다.
정수는 무계이지만 컴퓨터는 유한하여 표현할 수 있는 워드 크기(word size)를 갖는다. 16비트 아키텍처의 레지스터는 16비트로 숫자를 표현하여 표현가능한 최대 수가 11111111 11111111 이다. 이 수는 \(2 ^{16}-1 = 65535\) 이다.
바이너리 덧셈은 가장 오른쪽 비트인 LSB(least significant bits) 부터 시작하여 캐리 비트(carry bit)가 발생하면 윗 자리로 넘겨서 가장 왼쪽 비트인 MSB(most significant bits) 가 더해질 때까지 더한다. 이때 다음과 같이 오버플로우(overflow)가 발생할 수도 있다.
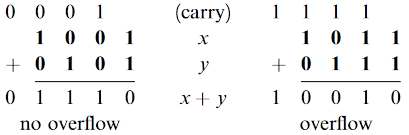
이진 코드로 양수와 음수를 표현하기 위해서는 양수와 음수를 더해서 \(0\) 가 나오도록 하기 위하여 2 의 보수를 사용한다.
2 의 보수(2's complement)
어떤 수 \(x\) 의 2 의 보수는 다음과 같이 정의된다.
이 2 의 보수를 사용하여 n비트 아키텍처에서는 \(-(2 ^{n-1})\) 부터 \(2 ^{n-1}-1\) 까지 \(2 ^{n}\) 개의 signed 수를 코딩할 수 있다. 양수의 MSB 는 0 으로 음수의 MSB 는 1 로 표현된다.
가령 \(4\) 비트 시스템에서 양수와 음수를 다음과 같이 표현한다.
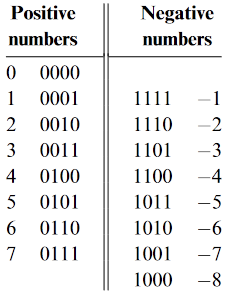
이렇게 2 의 보수로 숫자를 표현하면 양수와 음수를 그냥 더했을 때 오버플로우가 발생하여 비트가 버려져도 적절한 결과가 나온다.
이러한 이론적 기반으로 ALU 는 산술 연산과 논리 연산을 모두 지원하도록 설계되어있다. 이제 ALU 를 만들어볼텐데 가장 기본적인 덧셈기(adder) 칩부터 만들어보자.
Adders✔
덧셈기는 다음과 같이 구성된다.
- Half-adder : 2bits adder
- Full-adder : 3bits adder
- Adder : n-bit adder
- incrementer : 주어진 숫자에 1 을 더하는 덧셈기
Half-adder 를 다음과 같이 설계한다. MSB 를 carry 비트라고 표현했다.

Full-adder 를 다음과 같이 설계한다. Half-adder 에서처럼 덧셈 결과의 LSB 와 carry 비트 두 개만 출력한다.

n 비트 덧셈을 위한 Adder 를 다음과 같이 설계한다. n 은 16, 32, 64 등이 될 수 있다. 이 adder 를 multi-bit adder 라고도 하고 그냥 adder 라고도 한다. 다음은 16 비트 adder 를 표현한다.

다음은 incrementer 의 설계이다.

incrementer 는 이후에 현재 명령어를 실행한 이후 다음 명령어를 가져오는데에 사용된다. incrementer 의 기능을 Adder 칩이 충분히 해낼 수 있지만, 이렇게 \(1\) 을 증가시키도록 특화되어 있는 칩을 만들어주는 것이 훨씬 효율적이다.
ALU✔
위에서 소개한 adder 는 상당히 범용적이라 어떤 컴퓨터에서도 사용될 수 있다. 그러나 이 섹션에서는 우리가 설계할 컴퓨터 아키텍처인 Hack 플랫폼에서 사용하는 ALU(Arithmetic Logic Unit) 를 설계해보자. 하지만 이 ALU 의 설계 원리도 상당히 범용적이다.
Hack 플랫폼의 ALU 는 함수 16 비트 입력 \(x, y\) 와 16 비트 출력 \(o\) 에 대한 함수
를 계산한다. 이 함수 \(f_i\) 는 18 가지 경우의 정해진 함수이며, 산술 연산이나 논리 연산을 수행하게 된다. 함수 선택은 컨트롤 비트라고 불리는 6 비트의 입력을 통해 정해진다.

ALU 는 6 비트의 control 비트로 연산을 정의하므로 \(2 ^{6}=64\) 가지의 기능을 표현할 수 있긴하다. 어쨌든 ALU 의 18 가지 기능은 다음과 같다.

가령 위 표에서 \(x-1\) 을 계산할 때의 컨트롤 비트를 보자. \(x\) 에 대해서는 컨트롤 비트가 \(zx = nx = 0\) 이므로 \(x\) 가 zero 가 되지도 않고 반전되지도 않는다. \(y=-1\) 에 대한 컨트롤 비트는 \(zy = ny = 1\) 인데 이로써 입력 \(y\) 가 zero 가 된 다음 반전된다. 그래서 \(y\) 은 \(000 \dots 00\) 이 되었다가 \(-1\) 을 뜻하는 \(111 \dots 11\) 이 된다. 이때 \(f = 1\) 이므로 산술 덧셈이 연산으로써 선택되어 \(x+(-1)\) 연산을 하게 된다. 이로써 \(x-1\) 연산이 수행되는 것이다.
입출력의 상세는 슈도코드로 다음과 같이 정의된다.

이러한 덧셈기와 ALU 의 구현은 조금만 생각해보면 논리 게이트들로부터 쉽게 구현할 수 있다는 것이 떠오를 것이다. 실제로 half adder 는 다음과 같이 쉽게 정의되고, 이를 기반으로 논리 게이트를 조금 더 추가하여 덧셈기를 만들 수 있고, ALU 까지도 쉽게 만들 수 있다.
CHIP HalfAdder {
IN a, b;
OUT sum, carry;
PARTS:
Xor(a=a, b=b, out=sum);
And(a=a, b=b, out=carry);
}
CHIP FullAdder {
IN a, b, c;
OUT sum, carry;
PARTS:
HalfAdder(a=a, b=b, sum=sumab, carry=carryab);
HalfAdder(a=sumab, b=c, sum=sum, carry=carryabc);
Or(a=carryab, b=carryabc, out=carry);
}
CHIP Add16 {
IN a[16], b[16];
OUT out[16];
PARTS:
HalfAdder(a=a[0], b=b[0], sum=out[0], carry=carry0);
FullAdder(a=a[1], b=b[1], c=carry0, sum=out[1], carry=carry1);
FullAdder(a=a[2], b=b[2], c=carry1, sum=out[2], carry=carry2);
FullAdder(a=a[3], b=b[3], c=carry2, sum=out[3], carry=carry3);
FullAdder(a=a[4], b=b[4], c=carry3, sum=out[4], carry=carry4);
FullAdder(a=a[5], b=b[5], c=carry4, sum=out[5], carry=carry5);
FullAdder(a=a[6], b=b[6], c=carry5, sum=out[6], carry=carry6);
FullAdder(a=a[7], b=b[7], c=carry6, sum=out[7], carry=carry7);
FullAdder(a=a[8], b=b[8], c=carry7, sum=out[8], carry=carry8);
FullAdder(a=a[9], b=b[9], c=carry8, sum=out[9], carry=carry9);
FullAdder(a=a[10], b=b[10], c=carry9, sum=out[10], carry=carry10);
FullAdder(a=a[11], b=b[11], c=carry10, sum=out[11], carry=carry11);
FullAdder(a=a[12], b=b[12], c=carry11, sum=out[12], carry=carry12);
FullAdder(a=a[13], b=b[13], c=carry12, sum=out[13], carry=carry13);
FullAdder(a=a[14], b=b[14], c=carry13, sum=out[14], carry=carry14);
FullAdder(a=a[15], b=b[15], c=carry14, sum=out[15], carry=carry15);
}
CHIP ALU {
IN x[16], y[16], zx, nx, zy, ny, f, no;
OUT out[16], zr, ng;
PARTS:
Mux16(a=x, b=false, sel=zx, out=xval1); /* if zx then x=0 */
Not16(in=xval1, out=notxval);
Mux16(a=xval1, b=notxval, sel=nx, out=xval); /* if nx then x=!x */
Mux16(a=y, b=false, sel=zy, out=yval1); /* if zy then y=0 */
Not16(in=yval1, out=notyval);
Mux16(a=yval1, b=notyval, sel=ny, out=yval); /* if ny then y=!y */
Add16(a=xval, b=yval, out=sum);
And16(a=xval, b=yval, out=and);
Mux16(a=and, b=sum, sel=f, out=out1); /* if f then out=x+y else out=x&y */
Not16(in=out1, out=notout);
Mux16(a=out1, b=notout, sel=no, out=out2); /* if no then out=!out */
Or16Way(in=out2, out=outnonzero);
Mux(a=true, b=false, sel=outnonzero, out=zr); /* if out=0 then zr=1 else zr=0 */
IsNeg16(in=out2, out=neg);
Mux(a=false, b=true, sel=neg, out=ng); /* if out<0 then ng=1 else ng=0 */
Or16(a=out2, b=false, out=out);
}
Perspective✔
이렇게 ALU 를 설계해보았었는데 이는 최적화가 전혀 고려되지 않은 설계이긴 한다. 가령 carry 비트를 LSB 에서 MSB 까지 전달하는데 많은 시간이 걸린다. 이는 carry look-ahead 기술이라는 최적화 기술로 해결된다. 덧셈이 가장 자주 사용되는 연산이므로 덧셈에 가해지는 최적화는 체계의 성능을 극적으로 향상시킨다.
어떤 컴퓨터든 하드웨어와 소프트웨어 플랫폼의 전반적인 기능성은 ALU 와 OS 를 기반으로 한다. 그러므로 얼마나 많은 기능을 ALU 에 넣을지는 비용/성능의 문제에 달려있다. 일반적으로 산술/논리 연산을 많이 구현하면 비용이 더 들지만, 성능은 높아진다. 가령, incrementer 도 굳이 구현할 필요 없이 덧셈기를 사용하면 되지만 성능을 위하여 비용을 더 들여서 incrementer 를 구현하는 것처럼 말이다.
이러한 trade-off 가 있는데 우리는 기능을 덜 구현하고 소프트웨어 레벨에서 더 많은 기능을 구현하도록 한 것이다. 가령 우리의 ALU 에는 곱셈이나 나눗셈 floating point 연산이 없다. 우리는 이 기능과 여타 수학적인 기능을 OS 레벨에서 구현해볼 것이다.
참고로 ALU 의 상세한 설계에 대해서는 대부분의 컴퓨터 구조 전공서적에 자세히 나와있다.
Memory✔
논리 게이트로 값을 저장하는 칩을 만들 수도 있다. 이런 종류의 칩을 메모리 칩이라고 한다. ALU 를 만들기 위한 산술 칩들은 시간과 독립적이었다. 시간과 독립적인 칩의 출력은 입력의 조합에만 의존하기 때문에 조합적(combinational)이라고 한다. 그러나 이러한 칩들은 상태를 관리할 수 없다. 튜링 기계는 여러가지 상태를 관리하는 능력을 요구한다.
입력값과 시간에 출력이 의존하는 칩을 시퀸셜(sequential) 칩이라고 한다. 시퀸셜 칩을 설계하기 위해서는 논리로 시간의 흐름을 모델링할 수 있어야 한다. 이는 교류신호(0-1, low-high, tick-tack 등등)를 계속 생성하는 클락(clock)으로 해결된다. 클락이 생성하는 이 신호가 회로에 의하여 컴퓨터의 모든 시퀸셜 칩으로 전달된다. 클락에 의하여 "tick" 이 시작되고 "tock" 으로 끝나는 하나의 주기 싸이클(cycle)이 생성되는데, 이 싸이클로 컴퓨터의 모든 시간 의존적인 메모리 칩의 모든 동작을 정규화시킬 수 있다.
컴퓨터에는 데이터를 저장하는 능력, 즉, 시간이 지나도 데이터를 보존할 수 있는 능력이 요구된다. 이는 하드웨어 플랫폼이 상태를 유지할 수 있는 능력이다. 이를 위하여 먼저 클락을 도입하고, 상태를 \(0\) 이나 \(1\) 로 표현할 수 있는 시간의존적 논리게이트를 만들어야 한다. 이러한 게이트를 데이터 DFF(data flip-flop)라고 한다. DFF 가 다음과 같이 모든 메모리 기기의 기초 빌딩 블록이다.

ALU 에 7, 2 를 입력하고 "뺄셈" 을 설정하면 출력으로 5 가 나온다. 그러나 현실 세계에서 출력은 최소한 2가지 이유로 항상 지연된다. 첫번째 이유는 칩의 입력이 출력으로 가는데 걸리는 시간이고, 두번째 이유는 칩이 수행하는 계산에 걸리는 시간이다. 따라서 시간을 잘 맞춰야 한다.
시간이란 철학자와 물리학자에게는 무한소적으로 작은 변화의 연속이지만, 컴퓨터 공학에서는 시간을 이러한 연속적인 진적으로 보지 않고 고정된 주기인 싸이클의 이산적인 진전으로 본다. 따라서 실제 시간을 무한히 연속적인 화살표로 표현할 수 있지만, 싸이클은 원자적이고 개별적이다.

위 그림의 가장 위의 화살표가 물리학과 철학에서 바라보는 무한히 연속적인 시간의 진전을 나타낸다. 그 밑에는 컴퓨터 공학이 이산적인 진전으로 바라보는 시간을 나타낸다. 싸이클 \(n\) 에서의 세계의 상태를 알고, 그 이후의 싸이클 \(n+1\) 에서의 상태만을 안다. 그 사이의 상태는 신경쓰지 않는다.
컴퓨터 아키텍처에서 시간을 이렇게 설계하면 두 가지 이점이 있다. 먼저 통신과 계산 시간 지연에 연관되어 있는 무작위성을 정규화할 수 있다. 두번째는 체계 별로 다른 칩들의 연산을 동기화할 수 있다. 실제로 위 그림에서 나타는 \(\operatorname{Not}\) 게이트에 입력이 \(1\) 이 되었을 때 출력이 \(0\) 으로 바뀌는 물리학적인 시간 지연이 무작위적으로 일정량 발생한다. 그러나 이 시간 지연을 안전하게 포함할 수 있을만큼 싸이클을 정의하면, 논리 게이트의 동작에 소요되는 시간 지연 때문에 발생하는 계산의 부정확함을 제거할 수 있다.
그러므로 싸이클은 논리 게이트의 입출력에 소요되는 모든 시간 지연의 최댓값 이상으로 정의된다. 하지만 그렇다고 싸이클을 너무 길게 정의하면 하드웨어가 느려질 것이다. 이처럼 싸이클은 하드웨어 설계의 가장 중요한 파라미터 중 하나이다. 이 싸이클은 마스터 클락이 오실레이터(oscillator)를 사용하여 생성하며, 하드웨어의 회로를 통하여 이 싸이클이 모든 메모리 칩으로 전파된다.
Flip-Flops✔
정보를 저장, 기억하도록 설계된 메모리 칩은 플립플롭(flip-flop) 게이트를 기반으로 한다. 여기에서는 1비트 플립플롭인 DFF(data flip-flop)을 사용한다. DFF 는 마스터 클락에서 싸이클 신호와 데이터 입력을 입력받고 현재 시간 단위 \(t\) 와 게이트의 입출력 \(\operatorname{in}\) 과 \(\operatorname{out}\) 에 대한 \(\operatorname{out} (t) = \operatorname{in} (t-1)\) 의 동작을 구현한다. 시간 단위란 싸이클을 의미한다. 마스터 클락에서 전파하는 1 싸이클, 2 싸이클을 1 시간 단위, 2 시간 단위라고 표현하는 것이다. DFF 는 다음과 같이 설계된다.

DFF 는 레지스터, RAM 등 모든 메모리 칩의 기반이고, 모든 DFF 는 마스터 클락에 연결되어 있다.

위 그림은 일반적인 시퀸셜 논리의 설계를 보여준다. 시퀸셜 칩은 조합적 칩과 연결되어 상호작용하며, 피드백 루프를 통하여 시퀸셜 칩의 출력이 조합적 칩의 입력으로 다시 들어갈 수 있게 한다. 이로써 이전 시간 단위에서 나온 출력을 다시 입력으로 사용하는 것이다. 그러나 사실 피드백 루프라는 존재 자체가 조합적 칩에는 문제가 된다. 조합적 칩에는 시간이라는 개념 자체가 상정되어 있지 않기 때문이다. 따라서 조합적 칩에 피드백 루프를 사용하면 이전 시간 단위에서 나온 출력이 잘 입력된다는 것이 보장되지 않는다. 그러나 조합적 칩과 피드백 루프 사이에 DFF 가 있으면 고유의 시간 지연을 발생시켜주기 때문에 시간 \(t\) 의 출력이 시간 \(t-1\) 의 출력에 잘 의존되도록 유도해준다.
시퀸셜 칩은 컴퓨터 아키텍처 전반의 동작이 잘 동기화되도록 하는 매우 중요한 효용을 준다. 가령, ALU 가 \(x+y\) 를 계산하는데 \(x\) 는 가까운 레지스터의 출력이고 \(y\) 는 멀리 있는 RAM 레지스터의 출력이라고 하자. 그러면 물리적인 거리 때문에 \(x\) 와 \(y\) 가 ALU 에 도착하는 시간이 다를 수밖에 없다. 그러나 ALU 는 시간과 독립적인 조합적 칩이므로 단지 입력되는 신호에 따라 덧셈을 수행하고 출력을 내뱉을 뿐이다. 따라서 ALU 의 출력의 타당성을 보장하기 위해서는 일정 시간이 필요하다. 그 전의 ALU 의 출력은 무의미한 쓰레기값이다. 그러므로 신호가 컴퓨터 내에서 서로 가장 멀리 떨어진 칩과 칩 사이의 거리를 오가는데 걸리는 시간과 모든 칩의 계산 중에서 가장 오래걸리는 시간을 더한 시간 보다 클락의 싸이클 주기를 조금 더 길게 설정해야 한다. 이로써 ALU 의 출력이 항상 타당하다는 것을 보장할 수 있다.
Specification✔
-
DFF 는 Clock 의 입력과 1비트 데이터 입력을 받아서 시간 기반으로 \(\text{out}(t) = \text{in}(t-1)\) 을 출력한다.
-
레지스터는 어떤 값을 기억하는 기능을 하고, 로드 비트에 따라 값을 새로운 값을 쓸지 결정한다. 즉, \(\text{ out }(t) = \text{ out }(t-1)\) 의 기능을 한다. 반면 DFF 는 오직 이전 입력에 의하여 기능한다. 즉, \(\text{ out }(t) = \text{ in }(t-1)\) 이다. 다음은 1비트 레지스터 Bit 의 설계이다.

-
Bit 를 기반으로 다음과 같은 16비트 레지스터 Register 를 설계한다. 이 설계의 파라미터는 레지스터의 width 이다. width 는 레지스터가 몇 비트를 저장할 것인지 결정한다. 보통 16, 32, 64 비트가 된다. multi-bit 레지스터 내부의 데이터를 words 라고 부른다.

-
Register 를 쌓고 다음과 같이 동작하게 하면 임의의 길이의 RAM(random accses memory)을 쉽게 구현가능하다. random accses memory 라는 이름은 임의의 위치의 데이터를 위치에 관계없는 동일한 속도로 읽거나 쓸 수 있게끔 구현했다는 말이다.
-
n 개의 레지스터로 구현된 RAM 의 각각의 word 에 주소값(0 부터 n-1)을 부여한다.
-
n 레지스터의 배열을 만들뿐 아니라 주소값 j 가 주어지면 주소값 j 를 갖는 레지스터를 선택할 수 있는 논리 게이트 설계를 만든다. 이 주소값은 물리적으로 대응되지 않고, 논리적으로 대응된다.
RAM 은 입력 데이터, 주소값, load bit 라는 3가지 입력을 받는다. load=0 이면 읽기이고 load=1 이면 쓰기이다. RAM 의 설계 파라미터는 width 와 size 이다. width 는 레지스터가 저장할 비트(word)이고, size 는 word 들의 갯수이다.

-
-
Counters 는 매 시간 단위마다 상태값을 증가시키는 시퀸셜 칩이다. 즉, \(\text{ out }(t) = \text{ out }(t-1) + c\) 의 기능을 한다. \(c\) 는 보통 1 이다. 카운터는 컴퓨터에서 중요한 역할을 한다. 가령, PC(program counter) 는 다음에 실행할 명령어의 주소값을 저장하는데, 이때 카운터가 사용된다. 카운터는 다음과 같이 설계된다.

Meltdown 은 소프트웨어 설계가 모순적으로 되었을 때 발생하는 취약점만이 취약점이 아니라 하드웨어 설계가 모순되었을 때도 취약점이 발생한다는 것을 말해준다.
Implementation✔
-
DFF 게이트는 다음과 같은 \(\operatorname{Xor}\) 게이트의 조합으로 구성되는 SR NOR latch 게이트를 기반으로 구현된다.

위와 같은 SR NOR latch 에서 \(Q\) 와 \(\bar{Q}\) 는 다음과 같이 정의되고, \(Q\) 가 메모리 역할을 하여 \(R=0,S=0\) 가 된 이후에도 이전 값을 유지하게 된다.
\[ Q = \lnot (R \lor \bar{Q}) \qquad \bar{Q} = \lnot (S \lor Q) \]\(R=0, S=1\) 인 경우 \(S=1\) 이므로 \(\bar{Q}\) 는 무조건 \(0\) 으로 설정되고, 이에 따라 \(Q\) 는 \(1\) 로 설정된다. 이후 \(R\) 과 \(S\) 가 \(0\) 으로 떨어져도 \(Q\) 는 \(1\) 이라는 값을 유지한다. 이것이 \(Q\) 가 \(R=0, S=0\) 인 동안 이전 값을 기억한다는 것이다.
\(Q\)(메모리)에 \(0\) 을 쓰고 싶을 때는 \(R = 1, S = 0\) 을 입력하면 \(Q=0\) 가 되고, 이에 따라 \(\bar{Q} = 1\) 이 된다. 이후 다시 \(R=0, S=0\) 가 되어도 \(Q\) 는 \(0\) 을 유지한다. 이렇게 DFF 게이트는 클락이 정의하는 단위 시간이 흘러갈 때마다 다음과 같은 방식으로 값을 기억한다.
단위 시간 \(S\) \(R\) \(Q\) \(t\) \(1\) \(0\) \(1\) \(t+1\) \(0\) \(0\) \(1\)(기억) \(\vdots\) \(0\) \(0\) \(1\)(기억) \(t+n\) \(0\) \(1\) \(0\) \(t+(n+1)\) \(0\) \(0\) \(0\)(기억) \(\vdots\) \(0\) \(0\) \(0\)(기억) DFF 는 이 SR NOR latch 를 기반으로 마스터 클락과의 상호작용까지 구현하는 방식으로 다소 복잡하게 설계됨으로써 \(\operatorname{out} (t) = \operatorname{in} (t-1)\) 기능을 하게 된다. DFF 의 실제 설계가 복잡하지만, 여기에서 배울 점은 많지 않다. 따라서 DFF 의 실제 설계는 그냥 패스하자.
-
1비트 레지스터 Bit 는 다음과 같이 구현된다.

왼쪽은 잘못된 설계이고 오른쪽이 올바른 설계이다.
-
멀티비트 레지스터인 Register 는 단지 1비트 레지스터 Bit 를 쌓아놓은 것이다. 우리가 할 일은 load 입력을 모든 레지스터에 뿌려주는 것이다. 실제로 다음과 같이 구현된다.
RegisterCHIP Register { IN in[16], load; OUT out[16]; PARTS: Bit(in=in[0], load=load, out=out[0]); Bit(in=in[1], load=load, out=out[1]); Bit(in=in[2], load=load, out=out[2]); Bit(in=in[3], load=load, out=out[3]); Bit(in=in[4], load=load, out=out[4]); Bit(in=in[5], load=load, out=out[5]); Bit(in=in[6], load=load, out=out[6]); Bit(in=in[7], load=load, out=out[7]); Bit(in=in[8], load=load, out=out[8]); Bit(in=in[9], load=load, out=out[9]); Bit(in=in[10], load=load, out=out[10]); Bit(in=in[11], load=load, out=out[11]); Bit(in=in[12], load=load, out=out[12]); Bit(in=in[13], load=load, out=out[13]); Bit(in=in[14], load=load, out=out[14]); Bit(in=in[15], load=load, out=out[15]); }
우리가 만들 Hack 아키텍처는 16K(16384)개의 16비트 레지스터의 RAM 을 필요로 한다. 16K RAM 은 다음과 같이 구성된다.

-
RAM8 : 8 개의 레지스터 배열을 쌓아서 만들어진다. RAM8 의 구현은 다음과 같다.
RAM8CHIP RAM8 { IN in[16], load, address[3]; OUT out[16]; PARTS: DMux8Way(in=load, sel=address, a=loada, b=loadb, c=loadc, d=loadd, e=loade, f=loadf, g=loadg, h=loadh); Register(in=in, load=loada, out=outa); Register(in=in, load=loadb, out=outb); Register(in=in, load=loadc, out=outc); Register(in=in, load=loadd, out=outd); Register(in=in, load=loade, out=oute); Register(in=in, load=loadf, out=outf); Register(in=in, load=loadg, out=outg); Register(in=in, load=loadh, out=outh); Mux8Way16(a=outa, b=outb, c=outc, d=outd, e=oute, f=outf, g=outg, h=outh, sel=address, out=out); } -
RAM64 : 임의의 길이의 메모리는 작은 메모리 유닛으로부터 재귀적으로 구성할 수 있다. 가령 아래 그림의 오른쪽 부분과 같이 RAM64 는 RAM8 로 재귀적으로 구성할 수 있다. 64-레지스터의 주소값은 6비트로 구성하여 xxxyyy 의 형태를 띈다. MSB 인 xxx 부분은 RAM8 의 칩을 선택하고 LSB 인 yyy 는 RAM8 중 하나의 레지스터를 선택한다.
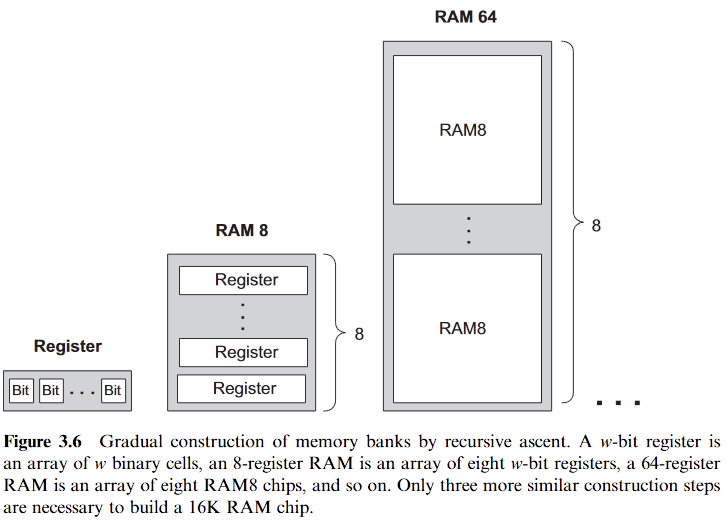
위와 같은 아이디어와 같은 방식으로 RAM512, RAM4K, RAM16K 를 재귀적으로 구성해낼 수 있고, 주소값을 형성할 수 있다.
-
Counter : 매 단위 시간마다 값을 증가시키는 메모리 유닛이다. 카운터는 초기값을 \(0\) 이나 다른 값으로 설정할 수 있어야 한다.
n비트 카운터는 n비트 레지스터와 조합적 논리 게이트로 설계된다. 조합적 칩은 카운팅과 카운터의 상태를 설정하게 된다. 카운터의 설계는 위에서 살펴보았고, 구현은 다음과 같다.
CounterCHIP PC { IN in[16],load,inc,reset; OUT out[16]; PARTS: Inc16(in=regout, out=plusone); Mux16(a=false, b=plusone, sel=inc, out=incout); Mux16(a=incout, b=in, sel=load, out=loadout); Mux16(a=loadout, b=false, sel=reset, out=toload); Or(a=load, b=reset, out=loadorreset); Or(a=loadorreset, b=inc, out=loadflag); Register(in=toload, load=loadflag, out=regout); Or16(a=regout, b=regout, out=out); }
Machine Language✔
기계어가 컴퓨터에 가할 수 있는 능력의 한계이다. 기계어라는 형식 언어로부터 컴퓨터라는 형식 체계를 완전히 설명할 수 있다. 기계어부터가 실질적인 시작이다. 기계어 밑에 있는 하드웨어에 대한 물리적인 조작은 해킹의 영역이 아니다. 물론 나중 가서는 로봇공학이 발전되면 물리 영역까지 해킹의 범주를 넓힐 수 있겠지만 그것은 나중의 이야기이다. C언어, 파이썬, Rust 같은 프로그래밍 언어, 여타 다른 프로그램, 모두 기계어의 조합에 불과하다. 해킹 경로를 찾는 도달가능성 문제는 기계어의 조합으로 이루어져야 한다. 그러므로 바둑의 한 수 한 수를 학습하는듯이 컴퓨팅 기기 간의 도달가능성 증명을 위한 시도들도 기계어의 한 수 한 수로 학습된다.
지금까지 프로세싱 칩과 메모리 칩을 설계했는데, 하드웨어 플랫폼을 완성하기 위해서는 컴퓨터의 목적이 무엇인지 정의해야 한다. 컴퓨터의 목적을 정의하기 위해서는 체계가 제공하기로 되어 있는 함수를 정의해야 한다. 따라서 하드웨어 플랫폼이 구현할 기계어(machine language)를 정의해야 한다. 기계어로 쓰여진 프로그램을 실행하는 것이 컴퓨터의 궁극의 함수이다. 기계어는 기계 명령어(instruction)을 코딩하도록 설계된 형식 언어이다. 우리는 기계 명령어를 사용하여 컴퓨터 프로세서가 산술/논리 연산을 하거나, 메모리의 값을 읽고 쓰거나, 조건을 테스트하여 어떤 명령을 가져와서 실행할지 결정하도록 명령할 수 있다. 고레벨 프로그래밍 언어가 크로스플랫폼에 대한 호환가능성과 표현력에 중점을 두고 설계된다면, 기계어는 특정 하드웨어의 능력을 완전히 통제할 수 있도록 설계된다. 반대로 하드웨어도 마찬가지로 주어진 기계어를 실행할 수 있도록 설계된다.
기계어가 하드웨어와 소프트웨어가 만나는 중간지점이다. 기계어는 프로그래머의 추상적 생각이 형식적 기호로 표현되어 하드웨어에서 실행되는 지점이다. 아무리 복잡하고 정교하고 아름답고 강력한 기능을 하는 프로그램이라고 하더라도 그것은 기계어의 나열에 불과하다.
General Machine Language✔
먼저 특정 하드웨어 플랫폼에서 특수한 논의를 하는 것이 아니라 컴퓨터 일반론에서 통용되는 기계어에 대하여 논의해보려 한다.
기계어(machine language)
기계어는 프로세서와 레지스터 집합을 사용하여 메모리를 조작하도록 설계된 형식 언어이다.
-
메모리는 주소값(address)으로 접근가능한 레지스터의 연속적인 열이다.
-
프로세서는 CPU(Central Processing Unit)을 뜻하며, 원시 연산 집합을 수행하는 역할을 한다. 원시 연산 집합에는 산술/논리 연산, 메모리 접근 연산(읽기/쓰기), 컨트롤 연산(브랜칭 연산)이 포함된다. 프로세서는 입력을 특정 레지스터나 메모리의 주소에서 읽고, 출력을 특정 레지스터나 메모리 주소에 쓴다. 프로세서는 ALU, 레지스터 집합, 이진 명령어(기계어)를 파싱하고 실행하는 논리 게이트로 구성된다.
-
레지스터는 프로세서와 메모리 사이에서 자주 사용되는 데이터를 저장하는 임시 저장소이다. CPU 레지스터는 데이터 레지스터, 주소 레지스터로 분류된다.
기계어 프로그램은 2가지의 동등한 방식으로 작성될 수 있다. 그것은 이진코드와 기호코드이다.
16비트 아키텍처에서의 기계어 프로그램은 16비트 명령어(16자리 이진법 수)의 수열이다. 가령 16 비트 시스템의 어느 한 명령어는 \(1010001100011001 _{2}\) 와 같이 표현된다. 이러한 16자리 이진법 수가 어떤 의미인지 알기 위하여 하드웨어 플랫폼의 규칙을 이해해야 한다. 가령 이런 명령어는 4비트 필드로 구성되어 있는데, 첫 4비트 필드는 CPU 의 어떤 기능을 지시하고, 나머지 4비트 필드들은 파라미터를 명시하게 된다. 이런 규칙은 전적으로 하드웨어 설계과 기계어 문법에 의해 결정된다.
한편 이러한 이진법 수가 사람이 알아보기 쉽지 않으므로 일대일 대응되는 기호가 제공된다. 가령 \(1010\) 이 add 를 나타내고 이후의 4비트 필드들이 R3, R1, R9 레지스터를 나타내는 것이라면 add R3 R1 R9 와 같은 형식문으로 사상되는 것이다.
원래, 초기에는 컴퓨터가 수작업으로 프로그래밍 되었다. add R3 R1 R9 에 해당하는 명령어를 입력하기 위해서는 기계적 스위치를 누르거나 올려야 했다. 이 명령어 수백개를 모아서 한 프로그램을 만들었으므로 이 프로그램이 생각대로 작동하지 않아서 디버깅을 해야 한다면, 그 작업이 너무 힘들었다. 이 불편함 때문에 프로그래머들은 add R3 R1 R9 같은 기호 코드를 개발하여 종이 위에서(물론, 현대에는 모니터 화면에서) 디버깅을 할 수 있도록 만들었다.
그러므로 n비트 아키텍처에서 하드웨어에 행할 수 있는 능력의 한계를 규정하기 위해서는 \(2 ^{n}\) 개의 명령어를 하드웨어에 입력해보는 일들이 필요하다. 공식적으로 제공되는 명령어는 물론 이것보다 적겠지만, 실제와 공식적인 성명은 동치가 아니므로 비공식적인 명령어들이 하드웨어에 어떤 영향을 미치는지 정립해둘 필요가 있다.
이는 한 하드웨어 플랫폼의 메모리 상태를 관찰함으로써 이루어진다. 메모리란 RAM 과 레지스터를 포함함 모든 메모리 기기를 뜻한다. 먼저 하드웨어 플랫폼의 메모리를 충분히 포함하고 관찰할 수 있는 다른 컴퓨터에서 해당 컴퓨터의 아키텍처의 메모리를 관찰한다. 그리고 \(2 ^{n}\) 개의 명령어의 첫번째 명령어인 \(\overbrace{000 \dots 0}^{n}\) 와 \(2 ^{n}\) 번째 명령어인 \(\overbrace{111 \dots 1}^{n}\) 까지 입력해보며 메모리가 어떻게 변화하는지 관찰한다.
기호 코드로 프로그램을 작성하면 변역기를 사용하여 그것을 CPU 에 곧바로 입력 가능한 이진코드로 변환하면 되었다. 형식문으로 된 그러한 프로그램을 어셈블리어(assembly language)라고 하고, 그것을 기계어로 변환하는 함수를 어셈블러(assembler)라고 한다.
컴퓨터들의 하드웨어 아키텍처에 따라서 CPU 기능, 레지스터 개수와 타입, 어셈블리 형식문의 문법이 모두 다르다. 하지만 이들은 모두 이론적으로 동등하고, 또한 다음과 같이 모든 기계어가 공통적으로 제공하는 명령어들이 존재한다.
-
산술/논리 연산 : 모든 컴퓨터는 덧셈과 뺄셈같은 기본적인 산술 연산을 지원하고, \(\operatorname{And}\), \(\operatorname{Or}\), \(\operatorname{Not}\), bit-wise negation, bit shift 같은 기본적인 논리 연산을 지원한다.
-
메모리 상호작용 : 모든 메모리 접근 명령어는 두 종류이다. 하나는, 레지스터와 메모리의 데이터에 작동하는 산술연산과 논리연산이다. 두번째는, 레지스터와 메모리 사이의 데이터를 이동시키는 명령이다.
메모리 접근 명령어를 사용하기 위해서는 주소값을 표현해야 하는데, 컴퓨터에 따라 주소값 표현 방식이 달라진다. 그러나 모든 컴퓨터는 다음과 같은 주소 표현식을 지원한다.
-
Direct addressing : 해당 주소값의 절대값으로 표현하는 것이다. 가령
load r1, 67은 Memory[67] 의 값을 r1 에 옮기겠다는 것이다. -
Immediate addressing : 해당 값을 바로 표현하는 것이다. 가령
loadi r1, 67은 Memory[67] 가 아닌 67 을 그대로 r1 에 옮기겠다는 것이다. -
Indirect addressing : 해당 주소값을 상대값으로 표현하는 것이다. 이것이 필요한 경우는 어떤 주소값이 하드코딩되어 있지 않은 경우이다. 가령
x=foo[j]라는 코드는foo라는 배열의j번째 word 단위 이후의 데이터를 가져와서x에 저장하겠다는 것인데foo의 주소값이 어디에 할당될지 아직 알 수 있기 때문에foo의 베이스 주소값에j만큼만 더하는 것이다. 그러면 이후에 프로그램이 실제로 실행될 때foo의 실제 주소값이 구체화될 것이다.
-
-
실행 흐름 통제 : 컴퓨터 프로그램의 기본적인 실행 흐름은 선형적이고, 한 명령어가 끝나면 다음 명령어가 실행된다. 그러나 분기 명령어를 사용하여 선형적인 흐름을 바꿀 수 있는데, 이로써 여러가지 실행흐름이 생기고 반복문도 만들 수 있다. 이때 필요한 것이 조건부 실행인데, 이는 술어 \(\phi (...)\) 를 만족할 때와 만족하지 않을 때 어떤 함수를 계산할 것인지 정하는 것과 같다. 이를 위하여 기계어는 조건부 분기와 무조건 분기 명령어를 제공한다. 다음 그림은 간단한 분기 명령어의 예시를 보여준다.

-
기호 : 위 그림에서 왼쪽 코드와 오른쪽 코드는 논리적으로 동등하지만, 왼쪽 코드처럼 실제 주소값을 코드에 박아버리면 범용성이 매우 떨어진다. 메모리 상황이 달라질 때마다 저 실제 주소값을 바꿔주어야 하기 때문이다. 오른쪽 코드처럼 기호 레퍼런스가 지원되면 코드를 훨씬 쉽게 작성할 수 있다.
이렇게까지가 모든 컴퓨터 아키텍처의 기계어의 본질이다. 이 본질을 기반으로 각 하드웨어 플랫폼마다 명령어들이 특수화되거나, 문법이 달라지거나 해서 기계어들이 달라진다. 그러나 모든 기계어와 아키텍처들은 이론적으로 동등하다.
가령, 가장 대중적인 PC 하드웨어 플랫폼인 x64 아키텍처의 스펙은 AMD 공식 페이지와 인텔 공식 페이지에서 제공된다.
Hack Machine Language✔
Hack 아키텍처는 다음과 같이 정의된다.
-
폰 노이만 구조이다.
-
16비트 시스템이다.
-
명령어 메모리, 데이터 메모리의 두 가지로 구분된 메모리 모듈을 갖는다.
-
screen, keyboard 의 두 I/O 디바이스를 갖는다.
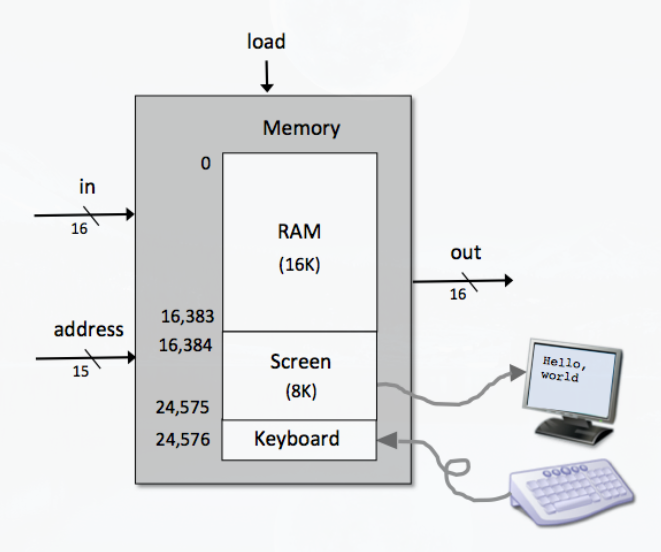
Memory Address Spaces✔
Hack 시스템은 명령어 메모리와 데이터 메모리로 구분되어 있다. 두 메모리는 16비트 wide 에 15비트 주소 공간을 갖는다. 즉 16bit word 의 최대 32K 메모리 주소가 존재할 수 있다.
데이터 메모리는 RAM 이라고 부르고, 명령어 메모리는 ROM(read-only memory)이다. 즉, 프로그램을 로드하는 것은 ROM 을 갈아치우는 것을 뜻한다. 따라서 Hack 플랫폼은 기계어 프로그램을 명령어 메모리로 로드하는 기능을 제공해야 한다.

Registers✔
Hack 시스템은 3가지 16비트 레지스터 D(data register), A(address register), M(memory register)를 갖는다. 레지스터로 A=D-1 이나 D=!A 와 같이 산술연산과 논리연산을 수행할 수 있다.
데이터 레지스터 D 는 16비트 값을 저장하는데 사용된다. A 는 주소 레지스터와 데이터 레지스터 두 역할을 한다. A 에 17 을 저장하고 싶다면 @17 이라는 명령어를 사용하면 된다. D 에 17 을 저장하고 싶다면 2가지 명령어를 조합하여 @17; D=A 와 같이 하면 된다.
즉, @value 라는 명령어는 특정한 값을 A 레지스터에 저장한다. 가령 sum 이 메모리 주소 17 을 나타낸다면 @17 과 @sum 둘 다 A 에 17 을 저장한다는 뜻이다.
A-instruction✔
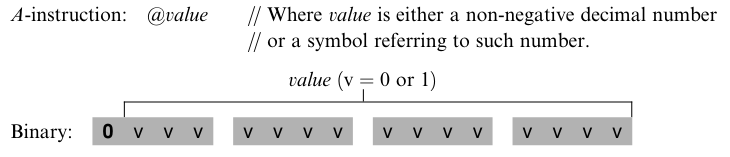
A-명령어가란 @value 이다. value 는 음이 아닌 정수이다. A-instruction 은 위와 같이 레지스터 A 를 15 비트 값으로 초기화한다. 가령 @5 명령어는 A 를 0000000000000101 로 초기화한다.
C-instruction✔
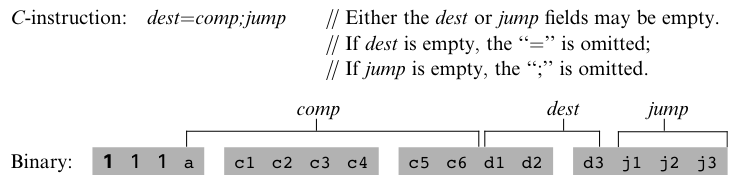
C-instruction 은 1) 무엇을 계산할지, 2) 계산된 값을 어디에 저장할지, 3) 그 이후에 뭘할지 라는 세 가지 질문으로 기계어 코드가 구성된다. 위와 같이 MSB 의 1 은 C-instruction 임을 의미한다. 그 다음 2 비트는 사용되지 않는다.
C-instruction 의 문법은 dest = comp;jump 이다. comp 는 ALU 에게 무엇을 계산할지 지정하고, dest 는 계산된 ALU 출력을 어디에 저장할지 지정하고, jump 는 다음에 실행할 명령에 대한 점프 조건을 명시한다. 각각의 필드를 자세히 살펴보자.
-
The Computation Specification : Hack ALU 는 D, A, M 레지스터를 계산하도록 설계되었다. M 은 Memory[A] 를 뜻한다.
comp필드는 7 비트로 구성되었는데, 이로써 128 개의 기능을 구별할 수 있다. 하지만 다음과 같은 28 개의 기능만 사용한다.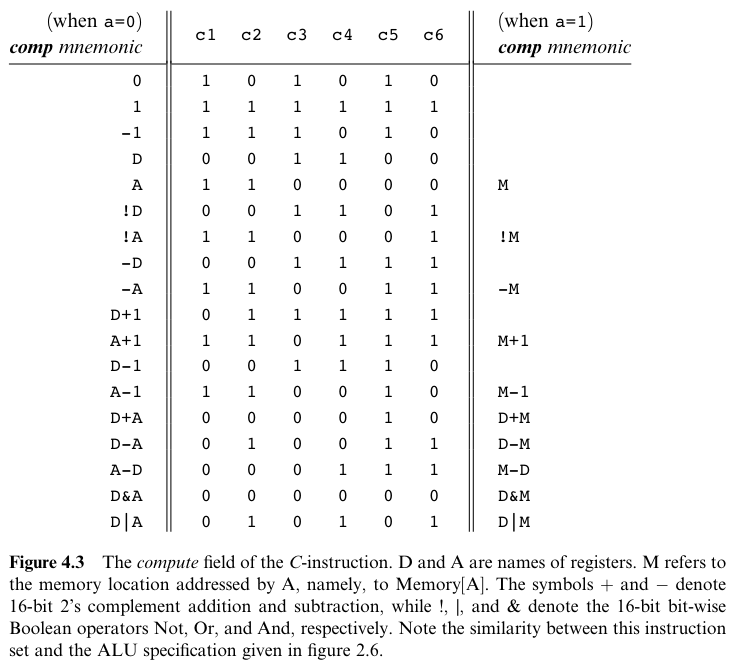
-
The Destination Specification : C-instruction 으로 계산된 값은
dest필드의 3 비트가 지정하는 곳에 저장된다. 첫번째, 두번째 d 비트는 A 레지스터에 저장할지, D 레지스터에 저장할지 구별한다. 세번째 d 비트는 Memory[A] 와 같은 M 에 저장할지 결정한다.
가령 Memory[7] 의 값을 증가시키고 D 레지스터에 저장하려면 다음과 같은 기계어 코드를 입력하면 된다.
0000 0000 0000 0111 // @7
1111 1101 1101 1000 // MD=M+1
-
The Jump Specification :
jump필드는 이후에 무엇을 할지 지정한다. 두 가지 가능성이 있는데 다음 명령어를 실행하거나, 다른 위치에 있는 명령어를 실행하는 것이다. 후자의 경우 A 레지스터가 위치 주소값을 지니고 있다고 가정한다.jump필드의 세 비트는 다음과 같이 ALU 출력이 특정 조건을 만족할 때 점프를 할지 결정한다.out이 ALU 의 출력을 뜻하고, j1 이 활성화되면 양수 조건이 추가되고 j2 가 활성화되면 \(= 0\) 조건이 추가되고 j3 가 활성화되면 음수 조건이 추가된다. 활성화된 조건 중 ALU 의 출력인out이 하나만 만족해도 점프를 하게 된다.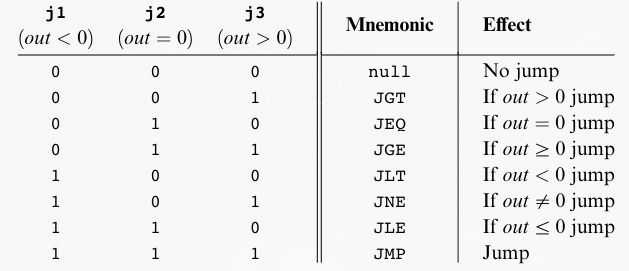
마지막
JMP는 무조건 분기를 뜻한다.
Symbols✔
어셈블리 명령어는 상수나 기호(Symbols)를 사용하여 메모리 주소를 표현할 수 있다. 기호는 다음과 같은 3가지 방법으로 표현된다.
-
Predefined symbols: RAM 주소의 특별한 부분집합은 다음과 같은 Predefined symbols 로 표현된다.
-
Virtual registers: 어셈블리 프로그래밍을 단순화하기 위하여
R0부터R15는 각각 RAM 주소의 0 부터 15 를 표현하기 위해 사용된다. -
Predefined pointers:
SP, LCL, ARG, THIS, THAT은 각각 RAM 주소의0부터5을 표현한다. 가령 주소 2 는R2로도 지칭할 수 있고ARG로도 지칭할 수 있다. -
I/O pointers:
SCREEN, KBD는 각각 RAM 주소의 16384(0x4000) 과 24576(0x6000) 을 지칭한다.
-
-
Label symbols:
goto명령의 label 목적지를 표현하기 위한 사용자정의 기호이다. 이 기호는Xxx로 정의된다. -
Variable symbols:
Xxx로 정의된 사용자정의 기호는 variable 로 여겨지며 어셈블러가 RAM 주소 16(0x0010) 로 시작되는 주소값을 부여한다.
Input/Output Handling✔
Hack 플랫폼은 screen 과 keyboard 에 연결된다. 이 두 IO 장비는 memory map 을 통하여 컴퓨터와 상호작용한다. 가령 스크린에 픽셀을 그리기 위하여 스크린과 연관된 메모리에 바이너리 값을 써야한다는 것이다. 또 키보드의 입력을 받는 것은 키보드와 연관된 메모리의 값을 읽는 것이다. IO 장비와 연관된 메모리 맵은 refresh loop 에 의하여 동기화된다.
-
Screen: Hack 컴퓨터는 512 픽셀을 갖는 256 행으로 구성되고 각 픽셀은 검정이나 흰색을 가진다. 스크린의 내용은 8K 메모리 맵으로 이루어지고, 이 맵은 RAM 주소 16384(0x4000) 에서 시작한다. 물리적 스크린의 각 행은 왼쪽 위에서부터 시작하고 이는 32개의 16비트 word 들로 표현된다.
즉, 한 행이 512 픽셀로 구성되었지만, 이것이 16비트 word 의 32개 블록으로 구성되었으므로 \(r\) 행을 선택하기 위하여 \(16384 + r \cdot 32\) 의 주소를 택한다. 그리고 512 픽셀의 열을 택하기 위하여 32개의 블록 중 \(c/16\) 을 더하여 해당 블록을 택한다. 따라서 \(16384 + r \cdot 32 + c / 16\) 으로 16비트 블록을 택할 수 있다. 이 블록 중에서 16비트 중 한 픽셀을 읽거나 쓰기 위하여 \(c\%16\) 비트를 택하면 된다.
따라서 r 행의 c 열은 \(16384+r \cdot 32 + c/16\) 주소의 \(c\%16\) 비트로 매핑된다. 스크린에 흑백을 쓰거나 읽기 위하여 이 메모리에 비트를 다음과 같이 쓰면된다. 1 을 쓰면 흑이고 0 을 쓰면 백이다.
예를 들어서 0 행의 400 열을 읽거나 쓰기 위하여 \(16384 + 0 \cdot 32 + 400 / 16 = 16384 + 0 + 25 = 16409\) 의 블록을 택하고, 이 블록은 16비트로 이루어져있으므로 이 블록 중에서 \(400 \% 16 = 0\) 번째 픽셀이 비로소 0 행 400 열의 픽셀이 된다.
-
Keyboard: Hack 컴퓨터의 키보드는 RAM 의 24576(0x6000) 의 한 word 에 매핑이된다. 키보드의 키를 누르면 이것은 16 비트 ascii 코드가 RAM[24576] 의 16비트 블록에 배핑이된다. 키보드를 누르지 않으면 이 블록에 0 이라는 값이 존재한다. 대표적인 ascii 코드는 다음과 같다.

Syntax Conventions and File Format✔
-
Binary Code Files: 이 파일은 텍스트 라인들로 구성된다. 각 라인은 16 개의 0 또는 1 의 아스키 캐릭터 수열이다. 이 수열이 하나의 기계어를 나타낸다. 전체의 라인은 기계어 프로그램을 나타낸다. n 번째 라인이 n 번째 기계어 코드를 나타낸다. Hack 플랫폼의 기계어 프로그램은
hack이라는 확장자를 가진다. 가령Prog.hack처럼. -
Assembly Language Files: 어셈블리 프로그램은
asm확장자에 저장된다. 가령Prog.asm. 어셈브릴 프로그램은 instruction 또는 symbol 을 나타내는 텍스트 라인으로 구성된다. instruction 은 A-instruction 혹은 C-명령어를 뜻한다. symbol 은 labelSymbol에 메모리 주소값을 부여한다.
아래의 컨벤션은 어셈블리 프로그램에 적용되는 것들이다.
-
Constants and Symbols: Constants 는 음이 아닌 수이다. 사용자 정의 symbol 은 글자, 숫자, "_", ".", "$", ":" 이 될 수 있다.
-
Comments: // 은 주석이다.
-
White Space: 공백문자는 무시된다.
-
Case Conventions: 모든 assembly mnemonics 은 대문자이다. 다른 것들, 즉 사용자 정의 label 과 변수이름같은 것들은 case sensitive 하다. label 에는 대문자를 사용하고 변수 이름에는 lowercase 를 사용한다.
Perspective✔
Hack 기계어는 정말 단순한 기계어이다. 다른 컴퓨터들은 더 많은 instruction, 더 많은 데이터 타입, 더 많은 registers, 더 많은 instruction format, 더 많은 주소값 지칭 모드를 가진다. 하지만 Hack 플랫폼에서 지원하지 않는 기능들은 소프트웨어에서 구현될 것이다. 가령 Hack 은 곱셈과 나눗셈을 지원하지 않는데 이는 OS 수준에서 구현될 것이다.
Hack 은 @xxx 뒤에 나오는 D=D+M 같은 기계어를 지원하는데 이것이 귀찮으므로 D=D+M[xxx] 으로 쓸 수 있고 @yyy 뒤에 나오는 GOTO 대신 GOTO yyy 로 쓸 수 있다.
Computer Architecture✔
이 장이 하드웨어 파트의 마지막이다. 1~3장에서 모든 칩들을 설계하였고 4장에서 기계어를 설계하였고, 이로써 Hack 플랫폼을 만들었다.
이 장에서는 먼저 폰 노이만 구조를 살펴보고, Hack 플랫폼은 폰 노이만 구조의 변형임을 알아본다. 이후 Hack 플랫폼의 하드웨어 스펙을 정의하고, 지금까지 만든 칩으로 Hack 플랫폼을 만든다.
Hack 플랫폼을 가능한 한 최대한 단순하게 만들어볼텐데, 필요이상으로 단순하게 만들지는 않을 것이다.
Computer Architecture Fundamentals✔
Stored Program Concept✔
다른 기계와 비교했을 때 컴퓨터는 매우 다재다능하다. 이는 컴퓨터가 프로그램을 저장할 수 있다는 특징 때문이다. 컴퓨터는 고정된 하드웨어이다. 컴퓨터 프로그램은 하드웨어를 조립하여 제작된 것이 아니다. 프로그램은 데이터처럼 메모리에 저장되고 조작되며 실행된다. 기존의 기계는 그 기계의 목적을 달성하기 위한 프로그램을 직접 하드웨어로 만들었었다. 그러나 컴퓨터는 프로그램을 데이터로 추상화시켜 메모리에 저장했고, 이것들을 실행하기 위한 매우 매우 추상적인 연산들만을 하드웨어로 고정시켰다.
그래서 컴퓨터가 할 수 있는 일들은 그것의 공리가 되는 논리 게이트들을 조합하여 할 수 있는 모든 일이 된다. 논리 게이트는 결국 논리 기호가 되고 이 게이트들이 기계어가 되었다. 우리가 실질적으로 사용할 수 있는 것은 논리 게이트가 아니라 기계어이기 때문에 기계어를 공리로 보고, 그것들의 모든 정리들을 프로그램으로 보아야 한다. 또 이 모든 정리 집합, 즉 프로그램 집합이 바로 컴퓨터가 할 수 있는 일들의 범위가 된다.
그러나 또 다시 "실질적으로" 컴퓨터에 대하여 할 수 있는 행동들이 정의된다. 키보드를 두드릴 수 있을 때, 하드웨어에 직접 접근할 수 있을 때, USB 만 꽂을 수 있을 때, 외부 컴퓨터에 네트워크로만 접근할 수 있을 때, 보안이 강한 서버와 통신해야 할 때 등등 각각의 상황에서 우리가 실질적으로 해당 컴퓨터에 할 수 있는 밑바닥을 규명할 수 있다. 이 행동 집합이 정의되면 그 집합을 구분하여 정상적인 행위, 비정상적인 행위(해킹) 같은 부분집합을 분할할 수 있다.
von Neumann Architecture✔
프로그램을 저장한다는 것이 많은 컴퓨터 모델의 핵심 개념이다. 가장 대표적으로 universal Turing machine(1936) 과 von Neumann machine(1945)가 있다. 튜링 머신은 매우 단순한 모델로써 컴퓨팅에 관한 근본적인 논리적 분석을 위하여 주로 이론적으로만 다루어진다. 반면 폰 노이만 구조는 실질적으로 컴퓨터를 만들기 위하여 사용되는 구조이다.
폰 노이만 구조는 다음 그림과 같이 CPU 를 기반으로 memory 와 상호작용한다. 이 상호작용이란 input 장치에서 데이터를 받아서 output 장치로 데이터를 내보내는 상호작용이다. 이 구조의 핵심이 stored program 개념이다.

Memory✔
메모리란 물리적 관점에서, 그리고 논리적 관점에서 정의할 수 있다. 물리적으로 메모리란 주소가 부여된 레지스터의 선형 배열이다. 논리적으로 메모리란 두 영역으로 나뉜다. 한 영역은 데이터를 저장하며 다른 영역은 프로그램을 저장한다.
사실 이 특징 때문에 취약점이나 해킹같은 것이 생겨난다. "자전거를 해킹한다" 라는 말은 어불성설이다. 왜냐하면 자전거의 프로그램은 물리적 구현체로 완성되었기 때문에 자전거의 동작을 해커가 조작한다는 것은 어불성설이다. 반면 컴퓨터 프로그램의 동작은 물레적 구현체로 고정되어 버린 것이 아니라 메모리에 저장되어서 조작 가능하다. 컴퓨터라는 기계를 해킹 가능한 것은 컴퓨터의 동작은 메모리에 있는 데이터가 결정짓기에 이런 일이 가능하고, 자전거라는 기계를 해킹하는 게 불가능한 이유는 자전거의 동작이 물리적으로 고정되었기 때문에 불가능한 것이다.
이 차이점이 컴퓨터라는 기계와 다른 기계들 사이에 존재하는 구조 사이에서 갖는 의미를 밝혀내면 해킹이 무엇인지 정의할 수도 있고 그 보다 더욱 일반화되거나 특수화된 구조를 갖는 기계 또한 정의할 수 있다.
폰 노이만 구조의 어떤 변형은 데이터 메모리와 명령어 메모리를 같은 메모리에 저장하지만, 어떤 변형은 다른 물리적 메모리에 저장한다. 후자의 구조를 하버드 구조라고 한다.
그러나 메모리는 그 역할과 관계 없이 같은 방법으로 접근 가능하다. 특정 메모리를 조작하기 위하여 주소값을 통해 레지스터를 선택해야 한다.
고레벨 언어가 다루는 변수, 배열, 객체등은 모두 메모리에 저장되는 이진 코드로 변환되어 메모리에 저장된다. 마찬가지로 고레벨 언어의 프로그램들 또한 기계어의 이진 코드로 변환되어 메모리에 저장된다. 따라서 프로그램이 컴퓨터에서 실행될 때는 프로그램의 코드가 명령어 메모리에 로드되어야 한다.
CPU✔
CPU 는 명령어 메모리에 있는 프로그램의 동작을 정의한 명령어를 실행하는 장치이다. 명령어가 CPU 에게 명령하는 것은 어떤 계산을 수행할지이다. 즉, 어떤 레지스터에게 무엇을 읽거나 쓸지, 어떤 명령어를 다음이 실행할지를 가르쳐준다. CPU 는 이 계산을 ALU, 레지스터들, control unit 을 통해 수행한다.
-
ALU(Arithmetic Logic Unit) : ALU 는 low-level 산술연산과 논리연산을 수행하는 장치이다. 두 숫자의 덧셈과 And 연산 같은 것들은 기본적으로 할 수 있다. ALU 의 하드웨어에 곱셈이나 나눗셈 Or 연산이나 Xor 연산 같은 추가적인 기능을 탑재하는 것은 필요성, 예산, 물리적 조건 등에 따라 결정된다. 만약 ALU 에 추가적인 기능을 물리적으로 구현하지 않는다면 OS 레벨에서 소프트웨어적으로 구현해야 하는데 물리적 구현보다 성능이 느려진다.
-
Registers : CPU 의 성능을 높이기 위하여 ALU 의 결과를 매번 멀리 있는 RAM 에 저장하는 게 아라 밀접한 곳에 있는 Register 에 저장한다.
-
Control Unit : 컴퓨터의 instruction 은 16, 32, 64 비트의 이진코드로 되어있다. 이 명령어가 실행되기 위하여 디코딩 되어야 하며 이 이진코드의 동작은 ALU, register, memory 의 하드웨어에 의해 결정된다. instruction 디코딩을 하는 장치를 control unit 이라고 부른다.
이제 CPU 의 동작을 다음의 무한 루프로 볼 수 있다. 이 싸이클을 fetch-execute cycle 이라 한다.
- instruction 디코딩
- 실행
- 다음 instruction 정하기
- 그 명령어를 가져오기
Registers✔
사실 register 는 변수, instruction, 주소값 등의 bit 뭉치를 저장할 수 있는 장치에 자유롭게 사용되는 단어이다. 여기에서는 CPU register 를 다뤄보자.
CPU register 가 없으면 매 연산마다 멀리 있는 RAM 을 사용해야 한다. Data register 에는 CPU 의 임시 결과값이 저장된다. Address register 에는 각종 읽기 주소, 쓰기 주소, instruction 주소 등이 저장된다. Program counter 라는 특별한 레지스터에는 다음에 실행될 instruction 의 주소값이 저장된다.
I/O✔
컴퓨터는 다양한 Input, Output 기기와 상호작용한다. 모니터, 키보드, 디스크, 프린터, 스캐너, 네트워크 카트 등등이 있고 자동차, 카메라, 의료기기 등등도 I/O 기기이다.
그런데 프로그래머는 이렇게 다양한 I/O 기기들의 상세한 구조를 몰라도 된다. 왜냐하면 컴퓨터 과학자들이 이들 I/O 기기들에 정교한 스키마를 만들어서 컴퓨터가 이들 모두를 동일한 방식으로 대할 수 있게 되었기 때문이다. 이 기술을 memory-mapped I/O 라고 한다.
memory-mapped I/O 란 I/O 장치가 CPU 에게 마치 하나의 정식 memory segment 처럼 보이게 하는 것이다. 이는 각각의 I/O 장치를 컴퓨터 메모리에 할당하는 것이다. 가령 키보드의 경우 사용자가 키보드를 누르면 해당 키의 이진코드가 키보드의 memory map 에 write 되고, 이것이 끊임없이 반영된다. 모니터의 경우 모니터에 할당된 memory map 이 픽셀로 변환되어 끊임없이 모니터로 반영된다. 따라서 컴퓨터는 단순히 I/O 기기에 할당된 메모리를 조작함으로써 I/O 기기를 통제할 수 있다. 이것이 memory-mapped I/O 이다.
이를 위하여 I/O 장치는 할당된 메모리의 값에 의하여 초당 몇번씩 갱신된다.
이러한 memory-mapped I/O 를 이루기 위하여 필요한 조건이 있다.
-
I/O 장치의 데이터가 컴퓨터의 메모리에 매핑되어야 한다. 가령 모니터의 2차원 픽셀이 컴퓨터 메모리의 1차원 벡터로 변환되어야 한다.
-
I/O 장치는 컴퓨터 프로그램이 일관된 상호작용을 할 수 있는 프로토콜을 가져야 한다. 가령 어떤 이진코드가 키보드에서 "A" 를 뜻할지 일관된 규칙이 있어야 한다.

이로써 다양한 기계의 물리적 구현체들이 컴퓨터 메모리 안의 이진수 벡터로 추상화된다. 이는 자연수로 표현가능한 존재하는 모든 기계를 컴퓨터로 통제할 수 있다는 것이다. 만약 인간의 뇌를 자연수로 표현할 수 있다고 하면, 이론적으로 인간의 뇌를 컴퓨터로 통제할 수 있다. 또 다른 예를 들어보면 컴퓨터 또한 자연수로 표현가능하므로 컴퓨터 또한 컴퓨터로 통제할 수 있다. 따라서 컴퓨터는 어떤 대상이 지니는 정보량보다 더 큰 메모리 공간을 가져야만 그 대상을 통제할 수 있다.
Hack Hardware Platform: Specification✔
Hack 플랫폼은 16비트 폰 노이만 구조를 갖는다. Hack 플랫폼의 CPU 는 data memory 와 instruction memory 와 상호작용하고 모니터와 키보드라는 2개의 I/O 장치를 갖는다.
Hack CPU 는 ALU 와 data register D, address register A, program counter PC 레지스터를 갖는다. D 레지스터가 데이터만 저장하는 반면 A 레지스터는 데이터를 저장할 수도, instruction memory 의 주소를 포인팅할 수도, data memory 의 주소를 포인팅할 수도 있다.
instruction 은 ixxaccccccdddjjj 라는 16비트 형식을 가진다. i비트는 instruction type 을 결정한다. 0 은 A-명령어가고 1 은 C-명령어가다. A-instruction 은 A 레지스터에 로드될 16비트 이진값으로 여겨진다. C-instruction 은 ALU 컨트롤 비트로 여겨진다.
CPU✔
Hack CPU 는 16비트 명령어를 실행하도록 설계되었다. Hack CPU 는 data memory, 그리고 instruction memory 와 연결되어 있다. instruction memory 는 ROM32K 라고 불리며 다음과 같이 설계된다.

Hack CPU 는 다음과 같이 instruction memory 에서 명령어를 읽어와서 data memory 와 상호작용한다.

inM, outM 은 M-레지스터를 뜻하며 addressM 은 outM 이 쓰여질 주솔르 뜻한다.
instruction 이 A-명령어가면 A 레지스터에 저장될 16비트를 로드한다. C-명령어가면 instruction 에 따라 ALU 연산을 진행하고 연산결과를 A, D, M 레지스터에 적절히 저장한다. M 레지스터에 저장하는 상황에 writeM 비트가 활성화된다.
reset 이 0 이면 CPU 가 ALU 의 결과를 사용하며 PC 레지스의 다음 명령어를 실행한다. 1 이면 PC 를 0 으로 초기화한다.
outM 과 writeM 은 combinational 하며 instruction 의 실행결과에 영향을 받는다. addressM 과 PC 의 결과는 clock 에 영향을 받으며 다음 time 의 instruction 의 결과에 영향을 받는다.
이렇게 Hack 기계어 프로그램을 실행하는 기계를 만들어보았다. 그렇다. 컴퓨터의 실체는 기계어를 실행하는 기계 그 이상도 이하도 아니다. 그러면 운영체제의 의미는 무엇인가? 운영체제도 컴퓨터가 실행할 기계어 프로그램에 불과하다. 그러나 매번 컴퓨터에 USB 같은 물리적 인터페이스로 기계어 프로그램을 입력하기 힘들기 때문에 컴퓨터와 프로그래머가 짠 기계어 프로그램을 중계해주는 소프트웨어적인 인터페이스를 만들어둔 것이다.
이론적으로 컴퓨터와 인간의 인터페이스가 기계어인 것은 맞지만, 편의상 컴퓨터와 기계어 사이에 인터페이스를 하나 더 만들어두어야 했다. 그것이 운영체제이다.
이렇게 이론적으로 컴퓨터를 이해하는 것도 좋지만, 현실에서 컴퓨터가 어떻게 설계되어있는지 이해하는 것도 중요하다. 튜링의 논문만 읽으면 가상 메모리가 무엇인지 알 수 없다.
Assembler✔
ch 1-5 에서 하드웨어 플랫폼을 구성했다면 6-12 에서 소프트웨어 플랫폼을 구축해본다. 소프트웨어 플랫폼 구성의 끝은 운영체제와 컴파일러를 만드는 것이다. 하지만 그 시작은 어셈블러를 만드는 것이다. 우리는 기계어라는 이진코드를 어셈블리어라고도 불렀다. Hack assembler 는 프로그램을 이진코드로 변환하여 하드웨어 플랫폼에서 실행가능하도록 만들어준다.
사실 어셈블리언어 문법을 이진코드로 변환하는 것은 매우 쉬운 일이다. 어려운 일이 뭐냐면 어셈블리 프로그램에서 사용하는 기호 reference 를 물리 메모리 주소에 대응하는 것이다. 이 일은 symbol table 을 사용하여 이루어진다. symbol table 은 소프트웨어 변환 프로젝트에서 자주 사용되는 데이터 구조이다.
기계어는 symbolic 하게, binary 하게 표현된다. binary 하게, 즉 이진코드로 표현된다고 함은 가령 1000011110110000000 로 표현된다는 것이다. 이것은 각각의 하드웨어 플랫폼의 논리회로 설계에 따라 기능하게 된다. 가령 왼쪽 8비트가 CPU 의 load 명령을 뜻할 수도 있고 오른쪽 8비트가 R3 를 뜻할 수도 있다. 따라서 하드웨어 플랫폼은 CPU 에 입력되는 비트 수의 경우의 수만큼의 명령어를 지닐 수 있다. 가령 32비트 시스템은 \(2 ^{32}\) 개의 명령어를 포함할 수 있다.
그러나 많은 경우 몇백개의 기계어를 마련한 후 나머지 이진코드들은 exception 으로 처리한다. (따라서 CPU 회사가 명시하지 않은 기계어인데 exception 으로 처리되지 않은 기계어는 에러이고 취약점을 유발한다.) 이 기계어들의 이진코드를 사람들이 기억하기에 쉽지 않으니 symbolic 대응을 만든다. 가령 이진코드 10001010111111 를 LOAD R3, 7 로 대응시키는 것이다.
symbolic 언어를 assembly 라 부르고 이 언어를 이진코드로 변환하는 프로그램을 assembler 라고 부른다.
또한 가령 LOAD R3, apple 이나 goto loop 처럼 apple 이나 loop 라는 기호 reference 를 사용하면 이것을 각 reference 의 주소값으로 대체해주어야 한다. LOAD R3, 7 이나 goto 259 처럼 말이다.
7 이나 259 같은 것들은 무의미한 기호이므로 사람이 잘 기억할 수 없고 잘 다룰 수 없기 때문이다. 이것은 무의미한 기호에 의미를 붙여가는 과정이다. 만약 기계적으로 7 이나 259 를 그대로 다룬다면 이를 통해 추상적인 작업을 구상할 수 있는 생각 공간이 줄어든다. 이것들에 의미를 부여하여 추상화시킴으로써 무의미한 기호로 구성도니 기계 공간이 아니라 인간이 부여한 의미 공간에서 작업을 할 수 있다.
한편 하드웨어 플랫폼 구성, 소프트웨어 플랫폼 구성, 프로그램 위계 구성 등등의 일들은 점점 더 무의미한 기호 체계에서 인간이 사용하는 유의미한 추상적인 대상들로 나아가는 방향으로 이루어지고 있다. 아무런 의미를 찾을 수 없었던 튜링 머신과 On/Off 의 1/0 신호들과 기계어와 이진코드 위에서 인간은 사랑을 나누고 재미를 느끼고 전투를 하고 일상적인 대화를 하고 업무를 하며 금전거래를 한다. 이 방향성은 점점 더 추상적인 인간의 행동과 마음을 무의미한 기호로 구성해내려 하는 방향성이다. 이렇게 하는 이유는 컴퓨터 내부로 인간의 행동이나 자연적 대상이나 인간의 생각이 사상되면 편리한점이 한 두가지가 아니기 때문이다.
이 흐름의 최종 목표는 모든 인간이 동의하나 동의하지 않으나 어쩔 수 없이 일반 지능을 컴퓨터 내부의 무의미한 기호로 구성하는 것이다. 이 시점은 "인간이 자연 대상을 컴퓨터 내부로 사상시키는 행위" 자체를 컴퓨터 내부로 사상시키는 시점이다. 이 시점부터 인간은 불필요한 존재가 된다. 그러나 정지 문제에서 살펴보았듯이 이 기계의 존재불가능성을 가정한다면, 이 기계보다는 덜 일반적인, 인간이 기계화할 수 있는 가장 고차원적인 생각과 대상이 기계화되는 시점이 인간의 가치가 추락하는 시점이 된다.
symbol 은 사실 두 가지 소스로부터 생긴다. 하나는 변수이고 하나는 라벨이다. 프로그래머가 변수를 만들면 컴파일러가 변수에 자동으로 주소값을 부여해준다. 프로그래머가 프로그램 상의 어떤 위치에 라벨을 만들면 컴파일러가 주소값으로 변환해준다.
Symbol Resolution✔
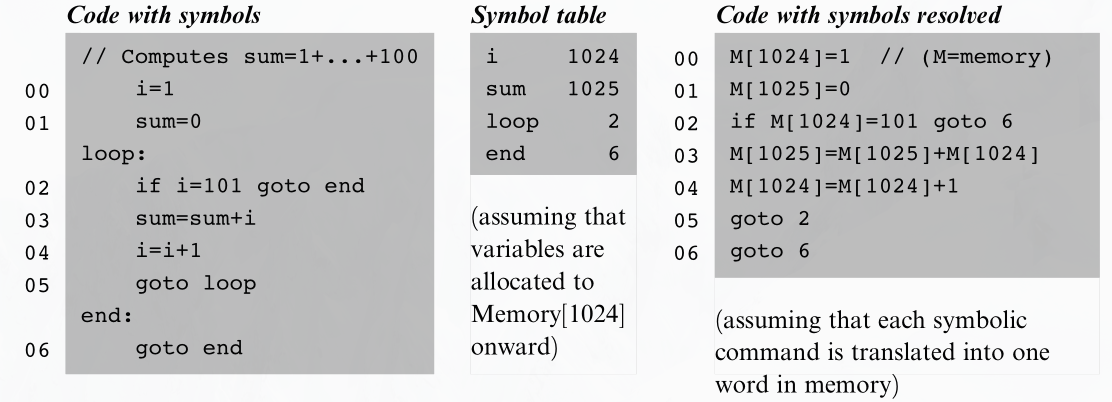
위 그림은 symbol 을 물리적 주소로 대응시키는 과정을 보여준다. 어떻게 이 과정을 설계할 수 있을까? 먼저 프로그램의 코드가 주소 0 부터 할당된다고 가정하고, 변수들은 주소 1024 부터 할당되어야 한다고 가정하자. 이 시작점 주소는 하드웨어 플랫폼에 따라 달라진다. 메모리 주소값 영역의 시작 주소를 알았다면 symbol table 을 만든다. 이는 xxx 라는 심볼에 대응하는 주소 \(n\) 에 대한 튜플 \((xxx, n)\) 의 집합이다.
위 그림은 변수 i 와 sum 은 각각 1024, 1025 에 할당한다.
Assembler✔
어셈블러는 어셈블리어를 이진코드로 변환한다. 이진코드는 instruction memory 에 로드되어 CPU 에 의해 실행된다.
-
symbolic 명령어를 field 로 파싱한다.
-
각 field 를 이진코드로 변환한다.
-
symbolic reference 를 물리적 주소로 변환한다.
-
이진코드를 종합하여 실행될 최종 프로그램을 만든다.
1, 2, 4 번 task 는 매우 쉽다. 3번 task 가 어렵다.
--- Software ---✔
High-level 언어를 컴파일하는 컴파일러를 만들어 볼텐데 ch 10-11 에서 high-level 프로그램을 바이트코드로 변환해보고 ch 7-8 에서 바이트코드를 기계어로 변환해볼 것이다.
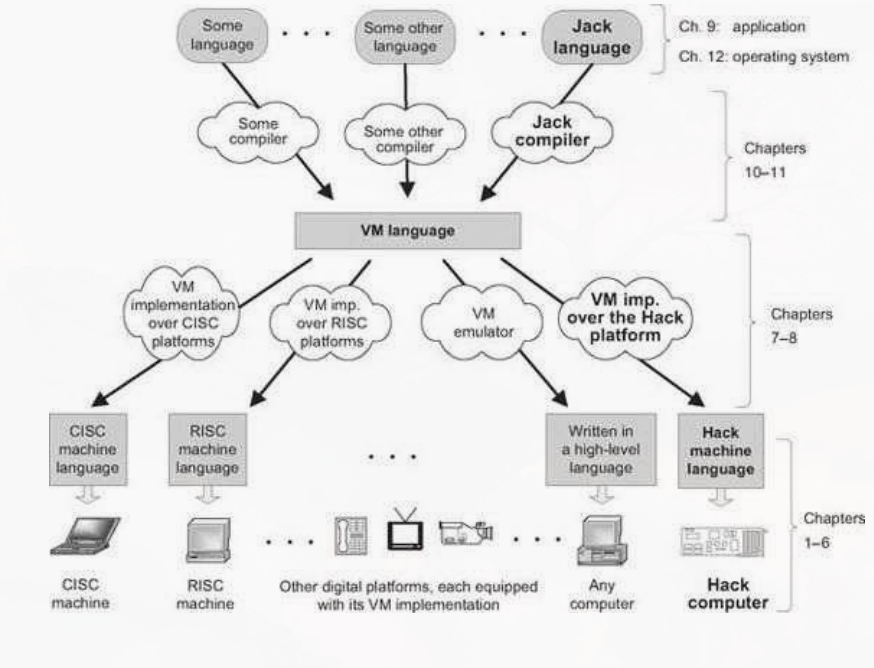
이러한 프로그래밍 언어 모델이 개발된 이유는 이식성 때문이다. 이런 언어는 실제 하드웨어 플랫폼에서 직접 실행되는 것이 아니라 VM 위에서 실행된다.

위와 같이 각 하드웨어 플랫폼에 따른 컴파일러를 만드는 것이 아니라 VM 을 만들어서 바이트코드를 만들면 다양한 플랫폼에서 컴파일 없이 VM 으로 원본 소스코드를 실행할 수 있다.
Virtual Machine I: Processing✔
이 챕터는 JVM 모델 패러다임을 기반으로 VM 구조를 소개한다. 가상머신(VM) 은 언어를 갖는데 VM 은 VM 코드를 받아서 Hack 어셈블리어로 변환하여 실행해준다.
다음 장에서는 기본적인 변환기를 확장해본다.
Virtual Machine Paradigm✔
고수준 언어는 반드시 해당 플랫폼의 기계어로 변환되어야 하는데 이 변환 과정을 컴파일이라 한다. 이는 고수준 언어가 기계어에 의존하기 되기 때문이다. 이 의존성 때문에 다양한 플랫폼이 갖는 다양한 기계어를 위하여 고수준 언어의 컴파일러가 각각 개발되어야 한다.
이 의존성을 분리하기 위하여 고수준 언어를 중간 언어로 변환시키고 그것을 해당 플랫폼의 기계어로 변환시킬 수 있다. VM 이 중간 언어를 받으면 그것을 실행시켜준다.
이렇게 하면 각 플랫폼마다 VM 의 구현만 수정하면 된다.
Stack Macine Model✔
다른 프로그래밍 언어처럼 VM 언어도 산술연산, 메모리접근, 흐름통제, 서브루틴으로 구성된다.
pass
Virtual Machine II: Control✔
프로그래머들은 서브루틴 호출, 파라미터 전달, 재귀, 메모리 할당 같은 기술을 컴파일러에게 맡기고 당연시하지만 이 블랙박스를 열어보자.
기계어를 추상화시켜서 의미를 부여하면 \(x = -b + \sqrt[]{b ^{2} -4ac}\) 같은 코드도 작성할 수 있어서 우리가 생각하는 알고리즘적인 생각을 코드로 표현할 수 있게 된다. 가령 print 라는 함수가 수많은 바이너리로 구성되었지만 그 바이너리에 "print" 라는 이름을 붙이고 print 함수가 하는 기능을 하도록 만들면 무의미한 이진수 배열들이 의미 있는 출력기능을 하는 함수가 되는 것이다.
의미를 찾기 힘든 기계어를 의미가 훤히 보이는 high-level 언어로 추상화시키기 위한 대표적인 기술은 다음과 같다.
-
서브루틴에 파라미터 전달
-
서브루틴 호출 전 caller 함수 상태 저장
-
서브루틴의 변수를 위한 공간 할당
-
서브루틴으로의 실행 흐름 변경
-
서브루틴으로부터 caller 함수로 실행 흐름 변경
-
할당된 메모리 해제
-
caller 함수 상태 복원
Program Flow✔
컴퓨터 프로그램의 실행 흐름은 기본적으로 선형적이라 한 명령어를 실행하고 다음 명령어를 실행한다. 이 선형성은 분기 명령어에 의하여 깨진다.
pass
High-Level Language✔
지금까지의 것들, 어셈블리, VM 언어(바이트코드)들은 모든 저수준(low-level)이었다. 저수준이란 인간의 이해력과 상관없이 오직 기계를 효과적으로 통제할 수 있도록 설계되었다는 뜻이다. 인간은 저수준으로 생각할 수 없다. 인간의 생각은 고레벨로 추상화된 언어로 표현 가능하다. 고레벨이란 인간 프로그래머가 작성할 수 있도록 설계되었다는 뜻이다.
Jack 이라는 고레벨 언어를 만들어볼 것이고, 10장 11장에서 이 언어의 컴파일러를 만들어 볼 것이다. 그리고 Jack 으로 쓰여진 운영체제를 12장에서 만들면, 이것으로 컴퓨터의 구성이 완료된다.
pass
Compiler I: Syntax Analysis✔
컴파일러는 원본 언어를 타겟 언어로 변환하는 프로그램이다. 이 변환을 컴파일이라고 한다. 컴파일을 위해서는 먼저 원본 언어의 문법을 이해하고 그것의 의미를 밝혀야 한다. 의미를 분석해내면, 그것을 타겟 언어의 문법으로도 표현할 수 있기 때문이다. 따라서 문법 분석, 그리고 코드 생성의 순서로 컴파일이 이루어진다.
이 장에서 문법 분석을 어떻게 하는지 알아보고, 다음 장에서 분석된 의미를 기반으로 코드 생성을 어떻게 하는지 알아본다.
그러니까 컴파일러는 문법 분석기와 코드 생성의 2가지 모듈로 구성된다. 문법 분석기를 만들면 그것이 분석해낸 의미 트리를 XML 파일로 생성해내는 것으로 테스트를 하게 된다.
pass
Compiler II: Code Generation✔
pass
Operating System✔
운영체제는 하드웨어와 소프트웨어 사이의 갭을 더욱 좁히기 위하여 설계된다.
가령, Hello World 를 스크린에 출력하기 위해서는 수백개의 픽셀을 특정 스크린 위치에 그려야 하고, 이는 해당 하드웨어의 스펙를 참고하며 특정 RAM 주소에 비트를 on 또는 off 해주어야만 한다. 이 일을 하기 위하여 얼마나 복잡하고 정교한 기계어 프로그램을 짜야 하겠나?
또한, 설령 이런 기계어 프로그램을 짜서 USB 에 담아서 물리적으로 입력하여 컴퓨터를 실행했다고 하더라도, 컴퓨터는 이 프로그램을 실행한 다음 곧바로 종료될 것이다. 그리고 그 다음 프로그램을 실행하려면, 또 다시 기계어 프로그램을 짜서 USB 에 담아서 컴퓨터에 꽂고 실행해도, 컴퓨터는 다시 종료된다.
(여기에서 작은 프로그램을 실행하기 위하여 USB 에 담아서 컴퓨터에 꽂는다는 말로 프로그램을 입력하는 것을 표현했는데, 운영체제OS를 개발하면 실제로는 HDD 나 SSD 에 저장하고 컴퓨터 본체에 직접 조립하여 실행하게 된다. 프로그램을 컴퓨터로 실행하기 위해서는 저장 장치에 프로그램을 저장하여 물리적으로 컴퓨터에 꽂아야 한다는 것은 본질적으로 똑같다.)
하지만 실제로는 운영체제가 있기 때문에 운영체제에 탑재된 표준 라이브러리 덕분에 단지 print("Hello World") 라는 코드 한줄로 이 일을 할 수 있고, 이 프로그램을 실행해도 컴퓨터가 종료되지 않는다. 컴퓨터는 본질적으로 운영체제를 계속 실행하고 있는 상태이므로!
운영체제는 최소한 1) 하드웨어 스펙에 따른 저레벨 서비스들을 고레벨 소프트웨어 서비스로 캡슐화하여 제공해야 하고, 2) 고레벨 언어를 일반적으로 자주 사용되는 함수와 추상화된 데이터 타입으로 확장해야 한다.
OS 는 메모리와 입출력과 장치들 간의 처리를 잘 조작하여 하드웨어를 잘 통제하고 가려줌으로써 고레벨 프로그래머들이 하드웨어에 전혀 신경쓰지 않고 고레벨 코드들을 사용할 수 있게 해주어야 한다. 또한, OS 가 컴퓨터에서 실행될 모든 프로그램을 실행하고 관리하는 역할을 해야 하므로 효율이 매우 중요하다. 컴퓨터 하드웨어 자원을 낭비하지 않고 가장 효율적으로 하드웨어를 사용할 수 있어야 하고, 똑같은 프로그램이라도 가능한한 더 빠르게 하드웨어에 입력하여 처리하고 사용자에게 출력을 되돌려주는 OS 가 좋은 OS 이다.
그래서 Arch Linux 커널 사용자들은 실제로 Arch Linux 를 더욱 효율적으로 최적화한 Zen Arch Linux 를 사용하기도 한다. zen arch linux 운영체제에서는 똑같은 프로그램이 Arch Linux 보다 더 빠르게 실행되고 처리된다.
일반적으로 OS 성능은 윈도우보다 리눅스가 더 좋다. 그럼에도 개인 PC 에서 윈도우를 OS 로 사용하는 것은 리눅스보다 사용자 편의성이 더 좋기 때문이다. 따라서 컴퓨터에 이미 능숙한 개발자들은 서버 컴퓨터가 필요할 때에는, 하드웨어 성능을 극대화시켜주는 OS 인 리눅스를 설치하여 사용하게 된다. 그리고 리눅스 중에서도 우분투, 민트 리눅스 같은 GUI 기반 OS 는 Arch 리눅스 같은 완전 경량화되어있고 최적화 되어있는 CLI 기반 OS 보다 더 무겁기 마련이다. 그래서 서버 컴퓨터 하드웨어 자원의 성능을 극도로 효율적으로, 최적화하여 사용하게 해주는 수많은 리눅스 OS 종류 중에서 가장 좋은 OS 를 선택하여 사용하면 된다.
사실 리눅스를 쓴다고 하면 이미 윈도우 보다 훨씬 더 빠르고 경량화되고 최적화되고 효율적이라서, 리눅스 안에서는 그렇게 드라마틱한 차이는 없지만, 그래도 강박적으로 최대한 하드웨어 자원을 극단적으로 효율적으로 사용하고 싶은 리눅스 스트롱 유저들은 우분투 같은 좀 더 유저 친화적 리눅스 디스트로 보다는 Arch 리눅스 같은 것을 사용한다. 여기에서 한술 더 뜨면 Arch 리눅스를 한층 더 최적화한 zen arch 를 사용하기도 한다. zen linux 는 커널 해커들이 리눅스 커널을 더욱 효율적으로 최적화한 커널이다.
Background✔
컴퓨터는 다양한 입출력 장치, 키보드, 스크린, 마우스, 저장장치, 네트워크 인터페이스 카드(NIC), 마이크, 스피커 등등에 연결된다. 이 입출력 장치, 즉, I/O 장치들은 각자 전자기계적 특성을 갖고, 외부 환경을 바이너리로 변환하여 입력하거나, 바이너리를 외부 환경으로 변환시켜서 출력한다. 가령, 키보드는 사람의 손에 의한 키보드 입력을 바이너리로 변환하여 RAM 에 입력하고, 마이크는 소리를 바이너리로 변환하여 RAM 에 입력하고, 스피커는 RAM 의 바이너리를 소리로 변화하여 외부로 출력하고, 특이한 케이스이긴 한데 진동기는 바이너리를 진동으로 변환하여 외부로 출력한다.
OS 가 해야할 일은 기본적으로 유저에게 프로그램을 입력시킬 수 있는 프롬프트 Enter: 또는 > 를 띄우는 것이다. 이것이 유저가 OS 를 사용하여 얻어야 하는 첫번째 이점이고, 가장 기본적인 효용이다. 유저는 매번 USB 같은 저장장치에 프로그램을 입력하여 컴퓨터에 꽂아서 컴퓨터를 실행하고 그 프로그램이 끝나면 컴퓨터가 종료되어야만 하는 피곤함을 없앨 수 있다. 왜냐하면 OS 가 저장장치에 저장되어 있는 프로그램을 저런 식으로 프롬프트를 띄워서 경로를 입력시킴으로써 실행하고, 그 프로그램이 끝나면 다시 프롬프트로 돌아올 수 있게 해주기 때문이다.
하지만 이런 식의 명령어 라인 인터페이스(CLI)는 프로그래머들에게 편할지 몰라도, 일반인에게는 매우 불편했다. 일반인은 디렉토리 구조도 모르고 트리 구조도 모르고 실행파일과 비실행파일도 제대로 구별할 수 없고 명령어 이름을 외울 시간이 없기 때문이다. 따라서 그래픽 유저 인터페이스(GUI)가 개발되어 마우스 클릭으로 프로그램을 실행할 수 있게 되었다. 그러나 아무리 GUI 라고 해도, 그것은 결국 본질적으로 프롬프트에 명령어를 입력하는 것을 마우스 클릭으로 대신할 수 있게끔 도와주는 역할을 하는 것에 불과하다. GUI 에서 하는 모든 일은 결국에 프롬프트에 명령어를 입력하는 일로 환원된다.
그런데 우리에게 Enter: 라는 프롬프트를 띄우는 것은 너무 쉽고 당연한 일이지만, OS 를 개발하는 레벨에서는 이 프롬프트를 띄우기 위해서는 모니터의 정해진 위치에 Enter: 라는 문자열에 해당하는 픽셀들만 On 시키고 나머지는 Off 시킬 수 있도록, 모니터에 할당된 RAM 의 특정 주소값의 값을 1 로, 나머지를 0 으로 지정해주어야 한다.
그리고 OS 는 프로그램이 실행될 때 메모리를 할당 해주고, 종료되면 적절히 메모리를 비워줄 수 있어야 한다. 또한, 프로그램 마다 가상 메모리 공간을 만들어 주어서 효과적인 메모리 할당을 할 수 있게끔 해주어야 한다.
이런 식의 세부적인 사항은 공룡책을 읽어서 배우는 게 훨씬 더 자세하고 깊게 컴퓨터를 이해할 수 있다.