Probability Distribution
Contents
Statistics✔
질적 자료(qualitative data, 정성적 자료)
수치로 측정이 불가능한 자료이다.
- 전화번호, 성별, 종교분류 등이 있다.
양적 자료(quantitative data, 정량적 자료)
수치로 측정이 가능한 자료이다.
- 온도, 지능지수, 매출액 등이 있다.
변량(variate)
자료를 수량으로 나타낸 것이다.
-
예시
다음과 같이 학생들의 수학 점수를 숫자로 환원하여 나열한 것은 변량이다.
\[ 92, 84, 88, 45, 12, 29, 39, \dots \]다음과 같이 각 국가별 행복도를 수치로 환원하여 나열한 것은 변량이다.
\[ 15, 82, 10, 99, 28, \dots \]
계급(class)
변량을 일정한 간격으로 나눈 구간이다.
-
예시
학생들의 수학 점수를 나열한 변량 \(92, 84, 88, 45, 12, 29, 39, \dots\) 에 대하여 다음과 같이 일정 구간으로 나눈 것은 계급이라 한다.
\(10\) 점대 \(x_1\) 명, \(20\) 점대 \(x_2\) 명, \(\dots\) \(80\) 점대 \(x _{8}\) 명, \(90\) 점대 \(x_9\) 명
도수(frequency)
각 계급에 속하는 변량의 개수이다.
- 학생들의 수학 점수를 나열한 변량 \(92, 84, 88, 45, 12, 29, 39\) 에서 \(80\) 점대 계급에 속하는 변량의 개수는 \(2\) 이므로 도수가 \(2\) 이다.
상대도수(relative frequency)
전체 도수에 대한 각 계급의 도수의 비율이다.
-
예시
어떤 학생들의 수학점수에 대한 상대도수를 구하여 도수분포표에 추가해보면 다음과 같다.
점수 학생 수(명) 상대도수 \(61 \ssim 70\) \(1\) \(\dfrac{1}{20} = 0.05\) \(71 \ssim 80\) \(3\) \(\dfrac{3}{20} = 0.15\) \(81 \ssim 90\) \(10\) \(\dfrac{10}{20} = 0.5\) \(91 \ssim 100\) \(6\) \(\dfrac{16}{20} = 0.3\) 위와 같은 상대도수는 어떤 학생 \(1\) 명을 골랐을 때 해당 계급에 속할 확률이라고 볼 수도 있다. 즉, 어떤 학생 \(1\) 명을 골랐는데 수학점수가 \(81 \ssim 90\) 일 확률은 \(0.5 = 50 \%\) 이다.
Dispersion(deviation, variance, standard deviation)✔
산포도(dispersion, variability, scatter, spread)
데이터가 흩어져있는 정도를 나타내는 단위이다.
- 편차, 분산, 표준편차, 절대 편차 등이 있다.
편차(deviation)
자료의 한 변량에서 평균값을 뺀 값이다.
-
편차는 자료의 산포도를 나타내는 수치이다. 편차가 낮으면 값들이 평균 근처에 몰려있고, 편차가 높으면 값들이 평균으로부터 멀리 분포해있다.
-
예시
회사 \(A\) 와 회사 \(B\) 에서 직원 \(5\) 명의 연봉을 만원 단위로 다음과 같이 조사하였다고 하자.
회사 1 2 3 4 5 회사 \(A\) \(1200\) \(1600\) \(5600\) \(6000\) \(7000\) 회사 \(B\) \(4000\) \(4500\) \(4250\) \(5000\) \(3650\) 회사 \(A\) 와 회사 \(B\) 의 평균은 다음과 같이 두 곳 다 \(4280\)만원이다.
\[ \dfrac{1200 + 1600 + 5600 + 6000 + 7000}{5} \]\[ = \dfrac{4000 + 4500 + 4250 + 5000 + 3650}{5} = 4280 \]하지만 두 회사의 편차를 구해보면 다음과 같다.
회사 1 2 3 4 5 회사 \(A\) 의 편차 \(-3080\) \(-2680\) \(+1320\) \(+1720\) \(+2720\) 회사 \(B\) 의 편차 \(-280\) \(+220\) \(-30\) \(+720\) \(-630\)
분산(variance)
편차 제곱의 평균이다.
-
분산도 편차처럼 어떤 대상의 산포도를 나타내는 수치이다. 편차가 각 자료의 산포도를 알려주는 반면 분산은 전체 자료의 산포도를 대표하는 값이다.
-
원래 편차로부터 자료들의 산포도를 구할 수 있지만 모든 자료를 대표하는 산포도를 구하기 위하여 각 자료에 대한 편차를 더하면 \(0\) 이 된다. 따라서 이를 방지하기 위하여 각 자료에 대한 편차를 제곱해서 모두 양수로 바꿔준 후 더한다. 이것에 자료의 개수를 나누어 평균을 구함으로써 전체 대상에 대한 산포도를 관찰하는 것이 바로 분산인 것이다.
-
예시
편차의 예시에서 두 회사의 분산은 다음과 같다. 회사 \(A\) 의 분산은 다음과 같이 \(5753600\) 만원\(^{2}\) 이다.
\[ V _{A} = \dfrac{(-3080) ^{2} + (-2680) ^{2} + 1320 ^{2} + 1720 ^{2} + 2720 ^{2}}{5} = 5753600 \]회사 \(B\) 의 분산은 다음과 같이 \(208600\) 만원\(^{2}\) 이다.
\[ V _{B} = \dfrac{(-280) ^{2} + 220 ^{2} + (-30) ^{2} + 720 ^{2} + (-630) ^{2}}{5} = 208600 \]회사 \(A\) 의 분산이 회사 \(B\) 의 분산보다 훨씬 더 높다. 그러므로 회사 \(A\) 의 직원들간의 연봉 차이가 회사 \(B\) 의 직원들간의 연봉 차이보다 더 많다고 할 수 있다.
표준편차(standard deviation)
분산의 양의 제곱근이다.
-
표준편차도 분산처럼 어떤 대상의 산포도를 나타내는 수치이다. 편차란 각 자료에 대한 산포도를 보여주지만 모두 더해서 전체 대상에 대한 산포도를 관찰하려 하면 \(0\) 이 되버려서 산포도를 구할 수 없었다. 이것을 보완하려고 분산을 도입하여 편차의 제곱의 평균으로 전체 대상에 대한 산포도를 관찰하였다. 하지만 분산은 편차에 대한 제곱을 취하였기 때문에 원래의 단위에서 제곱이 취해졌고, 산포도 또한 불필요하게 커져버렸다. 따라서 표준편차를 도입하여 분산에 제곱근을 취하여 원래의 단위로 되돌려주고, 과하게 커져버린 산포도를 원래의 양으로 되돌려주는 것이다.
-
예시
분산의 예시에서 두 회사의 분산에 이어 표준편차를 구해보면 다음과 같다. 회사 \(A\) 의 표준편차는 다음과 같이 \(2398\) 만원이다.
\[ \sigma _{A} = \sqrt[]{V_A} = \sqrt[]{5753600} \approx 2398 \]회사 \(B\) 의 표준편차는 다음과 같이 \(456\) 만원이다.
\[ \sigma _{B} = \sqrt[]{V_B} = \sqrt[]{208600} \approx 456 \] -
분산으로 각 대상에 대한 산포도를 관찰하려 했을 때는 만원\(^{2}\) 이라는 이상한 단위가 나왔고, 그 값이 다음과 같이 비정상적으로 컸다.
\[ V_A = 5753600 \text{ 만원} ^{2} , \quad V_B = 208600 \text{ 만원} ^{2}\]하지만 다음과 같이 표준편차를 구함으로써 만원\(^{2}\) 이라는 단위도 원래의 단위로 되돌아왔고 뻥튀기 된 산포도가 원래의 양으로 되돌아왔다. 이 표준편차로 회사 \(A\) 연봉의 산포도가 회사 \(B\) 연봉의 산포도보다 높다는 것을 쉽게 알 수 있다.
\[ \sigma _{A} \approx 2398\text{ 만원} , \quad \sigma _{B} \approx 456 \text{ 만원}\]실제로 다시 자료를 관찰해보면 회사 \(A\) 의 각 자료들이 평균 \(4280\) 으로부터 약 \(2398\) 만큼 떨어져있고 회사 \(B\) 의 각 자료들이 평균 \(4280\) 으로부터 약 \(456\) 만큼 떨어져있다는 것도 알 수 있다.
회사 1 2 3 4 5 회사 \(A\) \(1200\) \(1600\) \(5600\) \(6000\) \(7000\) 회사 \(B\) \(4000\) \(4500\) \(4250\) \(5000\) \(3650\)
Probability Distribution✔
Random Variable✔
확률변수(random variable)
표본공간의 각 원소(근원사건)에 하나의 실수를 대응시킨 변수이다.
-
확률변수를 사용하면 표본공간을 수량화하여 여러 사건들의 확률을 수학적으로 동시에 다룰 수 있다.
-
확률이 특정 사건이 일어날 확률을 구하는 것이 목적이었다면 확률변수와 이 분야의 개념들은 표본공간 안의 모든 사건들의 확률을 구하여 그 분포를 해석함으로써 다른 사건의 확률을 추정하는 것이 목적이다.
-
예시
주사위를 던졌을 때 나오는 숫자를 확률변수 \(X_1\) 이라 하면 \(X_1 \in \{1,2,3,4,5,6\}\) 이다.
주사위를 \(2\) 번 던졌을 때 나오는 숫자의 합을 확률변수 \(X_2\) 이라 하면 \(X_2 \in \{2,3,4,5,6,7,8,9,10,11,12\}\) 이다.
-
예시
\(1\) 개의 동전을 \(2\) 번 던지는 시행에서 표본공간을 조건 "앞면이 나온 횟수" 로 분할하자. 그러면 분할된 각 사건과 그 확률의 대응관계는 앞면 \(H\), 뒷면 \(T\) 에 대하여 다음과 같다.
표본공간 \((T,T)\) \((H,T), (T, H)\) \((H,H)\) 앞면이 나온 횟수 \(0\) \(1\) \(2\) 확률 \(\dfrac{1}{4}\) \(\dfrac{2}{4}=\dfrac{1}{2}\) \(\dfrac{1}{4}\) 이때 "앞면이 나온 횟수" 를 확률변수 \(X\) 로 두면 각 사건을 다음과 같이 표현할 수 있다.
\[ X=0, X=1, X=2 \]이러한 \(X\) 들을 표본공간의 각각의 원소, 즉 근원사건에 실수를 대응시킨 것을 확률변수라 한다. 이 확률변수로 각각의 사건들이 특정되므로 \(X=x\) 로 표현할 수 있다.
확률변수로의 확률 표기
확률변수 \(X\) 에 대하여 어떤 사건 \(X = x\) 가 일어날 확률을 다음과 같이 표기한다.
\(X\) 가 \(a\) 이상, \(b\) 이하의 값을 취할 확률을 다음과 같이 표기한다.
-
어떤 사건이 일어날 확률을 \(P(A)\) 로 표기할 수 있으나 어차피 표본공간 내 모든 근원사건을 확률변수 \(X=x\) 로 특정할 수 있기 때문에 전체 사건(표본공간)에 대한 일관적인 표기를 위하여 \(P(X) = x\) 로 표기하는 것이 좋다.
-
예시
주사위를 던졌을 때 나오는 숫자를 확률변수 \(X_1\) 에서 \(x = 1,2,3,4,5,6\) 에 대하여 \(P(X_1 = x) = \dfrac{1}{6}\) 이다.
주사위를 \(2\) 번 던졌을 때 나오는 숫자의 합을 확률변수 \(X_2\) 이라 하면 \(P(X_2 = 2) = \dfrac{1}{36}\) 이다.
-
예시
"확률변수의 정의" 의 \(1\) 개의 동전을 \(2\) 번 던지는 시행에서 표본공간의 근원사건을 "앞면이 나온 횟수" 로 특정하는 예시에서 각각의 사건들을 확률변수
\[ X=0, X=1, X=2 \]로 표현할 수 있었다. 그러면 이제 이 사건들이 일어날 각각의 확률들을
\[ P(X=0) = \dfrac{1}{4}, P(X=1) = \dfrac{1}{2}, P(X=2) = \dfrac{1}{4} \]로 일관되게 표현할 수 있다. 한편 \(X\) 가 \(1\) 이상, \(2\) 이하의 값을 가질 확률, 즉 앞면이 \(1\) 번이나 \(2\) 번이 나올 사건이 일어날 확률을 다음과 같이 표현할 수 있다.
\[P(1 \leq X \leq 2) = \dfrac{1}{2} + \dfrac{1}{4} = \dfrac{3}{4}\]
Probability Distribution✔
확률분포(probability distribution)
확률변수 \(X\) 가 가질 수 있는 모든 값과 \(X\) 가 그 값을 취할 확률의 대응 관계(함수)를 확률변수 \(X\) 의 확률분포라 한다.
-
즉, 확률분포란 아래에서 살펴볼 확률질량함수(pmf), 또는 확률밀도함수(pdf)를 뜻하는 것이다.
-
예시
"확률변수의 정의" 의 \(1\) 개의 동전을 \(2\) 번 던지는 시행에서 표본공간의 근원사건을 "앞면이 나온 횟수" 로 특정하는 예시에서 확률변수 \(X\) 의 확률분포는 다음과 같다.
\(X\) \(0\) \(1\) \(2\) \(P(X=x)\) \(\dfrac{1}{4}\) \(\dfrac{1}{2}\) \(\dfrac{1}{4}\) -
위 예시처럼 확률분포는 확률분포표로 나타낼 수도 있고 좌표계에 확률분포 그래프로 나타낼 수도 있다.
Discrete Probability Distribution✔
이산확률변수(discrete random variable)
확률변수 \(X\) 가 가질 수 있는 값들이 셀 수 있을 때 \(X\) 를 이산확률변수라 한다.
-
예시
"확률변수의 정의" 의 \(1\) 개의 동전을 \(2\) 번 던지는 시행에서 표본공간의 근원사건을 "앞면이 나온 횟수" 로 특정하는 예시에서 확률변수 \(X\) 는 \(0, 1, 2\) 로 \(3\) 개의 값을 가질 수 있다. 따라서 \(X\) 는 이산확률변수이다.
확률질량함수(probability mass function)
이산확률변수 \(X\) 가 가질 수 있는 값이 \(x_1, x_2, x_3, \dots, x_n\) 일 때 \(X\) 의 각 값에 \(X\) 가 그 값을 취할 확률 \(p_1, p_2, p_3, \dots, p_n\) 을 대응시킨 다음과 같은 함수를 \(X\) 의 확률질량함수라고 한다.
-
예시
남학생 \(4\) 명, 여학생 \(3\) 명 중에서 임원 \(2\) 명을 뽑으려 할 때 뽑힌 여학생의 수를 확률변수 \(X\) 라 하자. \(X\) 의 확률질량함수를 구해보자.
먼저 여학생이 \(x\) 명 뽑혔고 남학생이 \(y\) 명뽑혔다고 할 때 \(x, y\) 는 \(x+ y =2\) 의 관계를 갖는다. 즉, \(y = 2 -x\) 이므로 확률변수 \(X = x\) 에 따른 각 사건들의 확률을 \(x\) 에 대하여 정리할 수 있다.
이제 확률을 구해보자. 확률은 \(7\) 명 중에서 \(2\) 명을 뽑는 경우의 수와 여학생이 \(x\) 명 뽑히는 경우의 수의 비
\[ \dfrac{{}_{3}C_{x} \times {}_{4}C_{2-x}}{{}_{7}C_{2}} \]이다. 이것은 확률변수 \(X = x\) 에 대한 함수와 같으므로 \(x = 0, 1, 2\) 에 대하여 다음과 같은 확률질량함수로 표현할 수 있다.
\[ P(X = x) = \dfrac{{}_{3}C_{x} \times {}_{4}C_{2-x}}{{}_{7}C_{2}} \]
이산확률분포(discrete probability distribution)
이산확률변수가 가지는 확률분포, 즉 확률질량함수를 통해 표현할 수 있는 확률분포이다.
- 확률변수가 이산확률분포라는 것은 확률변수가 가질 수 있는 값의 개수가 셀 수 있다는 것이다.
확률질량함수의 성질
이산확률변수 \(X\) 의 확률질량함수가 \(P(X = x_i) = p_i\) 일 때 \(i < j\) 인 \(i, j = 1, 2, \dots, n\) 에 대하여 다음이 성립한다.
-
\(0 \leq P(X = x_i) \leq 1\)
-
\(\displaystyle \sum_{i=1}^{n}P(X=x_i)= \sum_{i=1}^{n}p_i = p_1+p_2+p_3+\dots+p_n=1\)
-
\(\displaystyle P(x_i \leq X \leq x_j) = \sum_{k=i}^{j}P(X=x_k) = \sum_{k=i}^{j}p_k\)
-
확률질량함수는 어떤 사건에 대한 확률을 나타내는 함수이므로 전사건 \(S\) 과 임의의 사건 \(A\) 에 대한 다음의 확률의 기본 성질이 성립한다. 이 확률의 기본 성질을 기반으로 확률질량함수의 성질을 쉽게 이끌어낼 수 있다.
-
\(\boxed{ 0 \leq P(A) \leq 1}\)
-
\(\boxed{ P(S) = 1}\)
-
\(\boxed{ P(\varnothing ) = 0}\)
-
기댓값(expectation, expected value, 이산확률변수의 평균, mean of a discrete random variable)
이산확률변수 \(X\) 의 확률질량함수 \(P(X=x_i) = p_i\) 에 대하여 기댓값은 다음과 같이 확률변수에 그것의 확률을 곱하여 더한 값이다.
-
머신러닝에서 기댓값은 이렇게 표기된다. 이산확률분포 \(P(X)\) 를 따르는 확률질량함수 \(f(x)\) 의 기댓값은 다음과 같다.
\[ \Bbb{E}_{X \ssim P}[f(x)] = \sum_{x}^{}P(x)f(x) \]확률분포가 문맥상 명확할 때 단순히 \(\Bbb{E}_{X}[f(x)]\) 라고 표기한다. 확률변수도 문맥상 명확하면 더욱 단순히 \(\Bbb{E}[f(x)]\) 라고 표기한다.
-
기댓값은 매 시행마다 예상되는 값이다.
-
증명
평균은 \(i=1,2,3, \dots, n\) 에 대한 변량 \(x_i\) 과 도수 \(f_i\) 와 도수의 총합 \(N\) 에 대하여 다음과 같다.
\[ \begin{align}\begin{split} \dfrac{x_1f_1 + x_2f_2 + \dots + x_n f_n}{N} &= x_1 \dfrac{f_1}{N} +x_2 \dfrac{f_2}{N} + \dots + x_n \dfrac{f_n}{N} \\ &= x_1 p_1 +x_2 p_2 + \dots + x_n p_n \\ \end{split}\end{align} \tag*{} \]그러므로 확률변수의 기대값, 즉 평균은 다음과 같다.
\[ \mu = x_1 p_1 +x_2 p_2 + \dots + x_n p_n = \sum_{i=1}^{n} x_ip_i \tag*{■} \] -
예시
어떤 기계가 일주일 동안 고장날 횟수를 \(20\) 주 동안 관찰하여 얻은 도수분포표가 다음과 같다고 하자.
변량(고장횟수) 도수 \(0\) \(3\) \(1\) \(4\) \(2\) \(7\) \(3\) \(6\) 위 도수분포표에서 변량의 평균은 다음과 같다. 그러므로 이 기계가 일주일 동안 \(1.8\) 번 고장난 것으로 생각할 수 있다.
\[ \dfrac{0 \times 3 + 1 \times 4 + 2 \times 7 + 3 \times 6}{20} = 1.8 \]이제 고장난 횟수를 확률변수 \(x\) 로 하여 표본공간을 분류하고 그에 대한 확률 \(P(x)\) 를 정리하면 다음과 같다. 이때 확률은 각각의 상대도수와도 같다.
확률변수 \(x\) (고장횟수) 확률 \(P(x)\) \(0\) \(\dfrac{3}{20} = .15\) \(1\) \(\dfrac{4}{20} = .20\) \(2\) \(\dfrac{7}{20} = .35\) \(3\) \(\dfrac{6}{20} = .30\) 이제 기계가 일주일 동안 고장날 기대값(평균)을 구해보자. 기대값, 즉 확률변수의 평균은 다음과 같다.
\[ \mu = E(X) = 0 \times \dfrac{3}{20} + 1 \times \dfrac{4}{20} + 2 \times \dfrac{7}{20} + 3 \times \dfrac{6}{20} = 1.8 \] -
위 예시에서 볼 수 있듯이 이산확률변수의 확률변수, 확률, 기대값(평균), 분산, 표준편차는 도수분포표의 변량, 상대도수, 변량의 평균, 분산, 표준편차과 같다.
이산확률변수 도수분포표 확률변수 \(x\) 변량 확률 \(P(x)\) 상대도수 기대값 \(E(x) = \mu\) 변량의 평균 분산 \(V(x)\) 분산 표준편차 \(\sigma(x)\) 표준편차
이산확률변수의 분산(variance)
이산확률변수 \(X\) 의 확률질량함수가 \(P(X=x_i) = p_i\) 일 때 분산은 다음과 같다.
-
이산확률변수의 산포도를 나타내는 수치이다.
-
증명
분산의 정의는 "편차의 제곱의 평균" 이었다. 이산확률변수 \(X\) 의 편차의 제곱은 \((X - \mu) ^{2}\) 이므로 평균(기대값)의 정의 \(\displaystyle E(X) = \sum_{i=1}^{n}x_ip_i\) 에서 그냥 \(X\) 를 \((X- \mu) ^{2}\) 로 바꿈으로써 다음을 얻는다.
\[ V(X) = E((X- \mu ) ^{2}) = \sum_{i=1}^{n} (x_i - \mu) ^{2} p_i \]이때 위 식을 변형하면 \(\displaystyle \sum_{i=1}^{n}x_ip_i = \mu , \sum_{i=1}^{n}p_i = 1\) 이므로 다음이 성립한다.
\[ \begin{align}\begin{split} V(X) &=\sum_{i=1}^{n} (x_i - \mu ) ^{2} p_i \\ &= \sum_{i=1}^{n} (x_i ^{2} -2 \mu x_i + \mu ^{2} ) p_i \\ &= \sum_{i=1}^{n} x_i ^{2}p_i -2 \mu \sum_{i=1}^{n} x_ip_i + \mu ^{2} \sum_{i=1}^{n} p_i \\ &= \sum_{i=1}^{n} x_i ^{2}p_i -2 \mu \cdot \mu + \mu ^{2} \cdot 1 \\ &= \sum_{i=1}^{n} x_i ^{2}p_i - \mu ^{2} \\ &= E(X ^{2}) - \{E(X)\} ^{2} \\ \end{split}\end{align} \tag*{} \]■
-
예시
"기댓값" 의 예시에서 분산을 구해보면 다음과 같다. \(\mu = 1.8\) 이므로 다음을 얻는다.
\[ \begin{align}\begin{split} V(X) &=\sum_{i=1}^{n} (x_i - \mu ) ^{2} p_i \\ &= (0 - 1.8) ^{2}(0.15) + (1 - 1.8) ^{2}(0.20) \\ & \qquad + (2 - 1.8) ^{2}(0.35) + (3 - 1.8) ^{2}(0.3) \\ &= 1.06 \\ \end{split}\end{align} \tag*{} \]한편 \(V(X) = E(X ^{2}) - \{E(X)\}^{2}\) 이기도 하기 때문에 \(\mu = 1.8\) 와 \(X^2\) 의 기대값
\[ E(X ^{2}) = (0 ^{2}) \times \dfrac{3}{20} + (1 ^{2}) \times \dfrac{4}{20} + (2 ^{2}) \times \dfrac{7}{20} + (3 ^{2}) \times \dfrac{6}{20} = 4.3 \]에 대하여 다음이 성립한다.
\[ V(X) = E(X ^{2}) - \{E(X)\}^{2} = 4.3 - (1.8) ^{2} = 1.06 \]방금 구했던 \(1.06\) 의 값이 동일하게 나온 것을 알 수 있다.
이산확률변수의 표준편차(standard deviation)
이산확률변수 \(X\) 의 확률질량함수가 \(P(X=x_i) = p_i\) 일 때 표준편차는 다음과 같다.
-
이산확률변수의 산포도를 나타내는 수치이다. 분산에서 제곱으로 인하여 불필요하게 커져버린 산포도에 제곱근을 취하여 원래의 양으로 되돌려주는 것이다.
-
평균, 분산, 표준편차는 인공지능이 과거의 데이터로부터 어떤 특징이나 경향을 알아낼 수 있는 가장 기본적인 방법이다. 이것을 인공지능 모델을 만들기 전에 데이터의 특징을 파악할 때 사용한다.
-
예시
"이산확률변수의 분산" 의 예시에 이어서 표준편차 구해보면 다음과 같다.
\[ \sigma (X) = \sqrt[]{V(X)} = \sqrt[]{1.06} \approx 1.029 \]이로써 확률변수 \(X\) 가 평균 \(1.8\) 로부터 대충 \(1.029\) 만큼 떨어져있다고 생각할 수 있다.
-
예시
확률변수 \(X\) 의 확률분포가 다음과 같을 때 기대값, 분산, 표준편차를 구해보자.
\(X\) \(2\) \(4\) \(6\) \(P(X=x)\) \(\dfrac{1}{4}\) \(\dfrac{1}{2}\) \(\dfrac{1}{4}\) 확률변수 \(X\) 의 기대값(평균) \(E(X)\) : \(\displaystyle E(X) = 2 \times \dfrac{1}{4} + 4 \times \dfrac{1}{2} + 6 \times \dfrac{1}{4} = 4\)
\(X ^{2}\) 의 기댓값 \(E(X^2)\) : \(\displaystyle E(X ^{2}) = 2 ^{2} \times \dfrac{1}{4} + 4 ^{2} \times \dfrac{1}{2} + 6 ^{2} \times \dfrac{1}{4} = 18\)
분산 \(V(X)\) : \(\displaystyle V(X) = E(X ^{2}) - \{E(X)\} ^{2} = 18 - 4 ^{4} = 2\)
표준편차 \(\sigma (X)\) : \(\displaystyle \sigma (X) = \sqrt[]{V(X)} = \sqrt[]{2} \approx 1.414\)
이로써 확률변수 \(X\) 가 평균 \(4\) 로부터 대충 \(1.414\) 만큼 떨어져있다고 볼 수 있다.
이산확률변수의 평균, 분산, 표준편차의 성질
이산확률변수 \(X\) 와 두 상수 \(a, b(a \neq 0)\) 에 대하여 다음이 성립한다.
-
\(E(aX+b) = aE(X)+b\)
-
\(V(aX+b) = a ^{2}V(X)\)
-
\(\sigma (aX+b) = |a|\sigma (X)\)
-
이제 우리는 이산확률변수 \(X\) 의 평균, 분산, 표준편차를 구하는 법을 알게 되었다. 그러나 \(X\) 라는 확률변수로부터 \(2X +1\) 이나 \(3X\) 라는 확률변수의 평균, 분산, 표준편차를 구해야하는 상황이 있다. 이 정리는 그러한 상황을 위하여 확률변수 \(X\) 가 실수 \(a, b\) 에 대한 확률변수 \(aX+b\) 와 어떤 관계를 갖는지 알려준다.
-
증명
1:
이산확률변수 \(X\) 와 실수 \(a \neq 0, b\) 에 대하여 새로운 확률변수 \(Y = aX + b\) 를 생각하자. 그러면 \(i = 1,2, \dots, n\) 에 대한 확률변수 \(X\) 의 값 \(x_i\) 은 확률변수 \(Y\) 가 갖는 값 \(y_i\) 와 다음의 관계를 갖는다.
\[ y_i =ax_i + b \]단순히 \(x_i\) 에 \(a\) 배를 하고 \(b\) 를 더했기 때문에 \(y_i\) 가 일어날 확률은 \(x_i\) 가 일어날 확률과 같다. 그러므로 확률변수 \(Y\) 의 기대값 \(E(Y)\) 는 다음과 같다.
\[ \begin{align}\begin{split} E(Y) &=\sum_{i=1}^{n} y_ip_i = \sum_{i=1}^{n}(ax_i + b)p_i \\ &= a \sum_{i=1}^{n}x_ip_i+b \sum_{i=1}^{n}p_i \\ &= a E(X) + b \\ \end{split}\end{align} \tag*{} \]■
2:
\(E(X) = \mu\) 로 두면 \(E(Y) = a \mu + b\) 이므로 확률변수 \(Y\) 의 분산 \(V(Y)\) 는 다음과 같다.
\[ \begin{align}\begin{split} V(Y) &=\sum_{i=1}^{n} \{y_i - E(Y)\} ^{2} p_i \\ &= \sum_{i=1}^{n} \{y_i - (a \mu +b)\} ^{2}p_i \\ &= \sum_{i=1}^{n} \{(ax_i + b) - (a \mu +b)\} ^{2}p_i \\ &= \sum_{i=1}^{n} (ax_i - a \mu ) ^{2}p_i \\ &= a ^{2}\sum_{i=1}^{n} (x_i - \mu ) ^{2}p_i \\ &= a ^{2} V(X) \\ \end{split}\end{align} \tag*{} \]■
3:
\(Y\) 의 표준편차 \(\sigma (Y)\) 는 다음과 같다.
\[ \sigma (Y) = \sqrt[]{V(Y)} = \sqrt[]{a ^{2}V(X)} = |a| \sqrt[]{V(X)} = |a| \sigma (X) \tag*{■} \] -
예시
확률변수 \(X\) 에 대하여 \(E(X) = 4, E(X^2) = 25\) 일 때 확률변수 \(Y = 3X - 4\) 의 평균, 분산, 표준편차를 구해보자.
\(E(Y) = E(3X-4) = 3E(X) - 4 = 3 \cdot 4 - 4 = 8\)
\(\displaystyle V(X) = E(X ^{2}) - \{E(X)\} ^{2} = 25 - 4 ^{2} = 9\)
\(\leadsto V(Y) = 3 ^{2} V(X) = 9 \cdot 9 = 91\)
\(\displaystyle \sigma (X) = \sqrt[]{V(X)} = \sqrt[]{9} = 3\)
\(\leadsto \sigma (Y) = |3| \sigma(X) = 3 \cdot 3 = 9\)
Binomial Distribution✔
이항분포(binomial distribution)
한 번의 시행에서 사건 \(A\) 가 일어날 확률이 \(p\) 이고 \(n\) 번의 독립시행에서 사건 \(A\) 가 일어나는 횟수를 확률변수 \(X\) 라고 할 때 \(q=1-p\) 와 \(x = 0,1,2,\dots, n\) 에 대한 확률변수 \(X\) 의 확률질량함수는 다음과 같다.
이 확률변수 \(X\) 가 갖는 확률분포를 이항분포 \(B(n, p)\) 라 한다.
-
확률변수 \(X\) 의 확률분포가 이항분포 \(B(n, p)\) 이면 확률변수 \(X\) 가 이항분포 \(B(n, p)\) 를 따른다고 말한다.
-
예시
흰 공 \(3\) 개, 검은 공 \(1\) 개가 있는 주머니에서 공을 꺼내고 다시 넣는 시행을 \(3\) 번 반복한다고 하자. 이때 검은 공이 나오는 횟수를 확률변수 \(X\) 로 두고, 확률변수 \(X\) 의 확률질량함수를 구해보자. 이것은 \(3\) 회의 독립시행이고 검은 공이 나올 확률이 \(\dfrac{1}{4}\) 이므로 확률변수 \(X\) 는 이항분포 \(B \bigg (3, \dfrac{1}{4}\bigg )\) 를 따른다. 그러므로 확률질량함수는 \(x=0,1,2,3\) 에 대하여 다음과 같다.
\[ P(X=x) = {}_{3}C_{x}\bigg (\dfrac{1}{4} \bigg ) ^{x} \bigg ( \dfrac{3}{4} \bigg ) ^{3-x} \]이때 검은공이 \(2\) 번 이상 나올 확률을 구해보면 다음과 같다.
\[ \begin{align}\begin{split} P(X \geq 2) &=P(X=2) + P(X=3) \\ &= {}_{3}C_{2}\bigg (\dfrac{1}{4}\bigg )^{2} \bigg (\dfrac{3}{4} \bigg )^{1} + {}_{3}C_{3}\bigg ( \dfrac{1}{4} \bigg )^{3}\bigg (\dfrac{3}{4}\bigg )^{0} = \dfrac{5}{32} \\ \end{split}\end{align} \tag*{} \]
이항분포의 평균
확률변수 \(X\) 가 이항분포 \(B(n,p)\) 를 따를 때 이항분포의 평균은 다음과 같다.
-
증명
일반적인 이산확률변수 \(X\) 의 확률질량함수가 \(i = 1, 2, \dots, n\) 에 대하여 \(P(X = x_i) = p_i\) 이었고 그에 대한 확률변수 \(X\) 의 평균은 다음과 같다.
\[ E(X) = \sum_{i=1}^{n}x_i P(X=i) = \sum_{i=1}^{n}x_ip_i \]이 확률변수 \(X\) 가 이항분포 \(B(n, p)\) 를 따른다면 확률변수 \(X\) 가 갖는 값은 \(0, 1, 2, \dots, n\) 이므로 \(i=0,1,2,\dots, n\) 에 대하여 \(x_i = i\) 이다. 따라서 평균은 다음과 같다.
\[ \begin{align}\begin{split} E(X) &= \sum_{i=0}^{n}i \cdot P(X=i) = \sum_{r=0}^{n}r \cdot P(X=r) \\ &= \sum_{r=0}^{n}r \cdot {}_{n}C_{r}p ^{r}q ^{n-r} = \sum_{r=1}^{n}r \cdot \dfrac{n!}{(n-r)!r!}p ^{r}q ^{n-r} \\ &= \sum_{r=1}^{n}\dfrac{n!}{(n-r)!(r-1)!}p ^{r}q ^{n-r} = \sum_{r=1}^{n}np \cdot \dfrac{(n-1)!}{(n-r)!(r-1)!}p ^{r-1}q ^{n-r} \\ &= np \sum_{r=1}^{n} \dfrac{(n-1)!}{(n-r)!(r-1)!}p ^{r-1}q ^{n-r} = np \sum_{r=1}^{n} {}_{n-1}C_{r-1} p ^{r-1}q ^{(n-1)-(r-1)} \\ &= np \sum_{r=0}^{n-1} {}_{n-1}C_{r} p ^{r}q ^{(n-1)-(r)} \\ &= np (p+q) ^{n-1} \quad \left( \because (a+b) ^{n} = \sum_{r=0}^{n}{}_{n}C_{r}a ^{n-r}b ^{r} \right)\\ &= np \quad \left( \because p+q=1 \right)\\ \end{split}\end{align} \tag*{} \]■
이항분포의 분산
확률변수 \(X\) 가 이항분포 \(B(n,p)\) 를 따를 때 이항분포의 분산은 \(q = 1-p\) 에 대하여 다음과 같다.
-
증명
확률변수 \(X\) 의 분산은 다음과 같다.
\[ V(X) = E(X ^{2}) - \{E(X)\} ^{2} \]\(E(X) = np\) 이므로 \(E(X ^{2})\) 를 구해보자. 확률변수 \(X\) 가 이항분포 \(B(n, p)\) 를 따른다면 확률변수 \(X\) 가 갖는 값은 \(0, 1, 2, \dots, n\) 이므로 확률변수 \(X^2\) 가 갖는 값은 \(0 ^{2}, 1 ^{2}, 2 ^{2}, \dots, n ^{2}\) 이다. 따라서 \(X^2\) 의 평균은 다음과 같다.
\[ E(X ^{2}) = \sum_{r=0}^{n}r ^{2} \cdot P(X ^{2}=r) \]그런데 이항분포 \(B(n, p)\) 를 따르는 확률변수 \(X\) 의 확률질량함수 \(P(X=x)\) 는
\(q = 1 - p\) 에 대하여 \(P(X=x) = {}_{n}C_{x}p ^{x}q ^{n-x}\) 인데 확률변수 \(X\) 에 제곱을 하여 \(X^2\) 를 만들었다고 해도 그에 대응되는 확률이 변하지는 않으므로 확률질량함수는 변하지 않는다. 따라서 다음을 얻는다.
\[ \begin{align}\begin{split} &= \sum_{r=0}^{n} r ^{2} {}_{n}C_{r}p ^{r}q ^{n-r} \\ &= \sum_{r=0}^{n} r(r-1) {}_{n}C_{r}p ^{r}q ^{n-r}+\sum_{r=0}^{n} r {}_{n}C_{r}p ^{r}q ^{n-r} \quad (\because r ^{2} = r(r-1) + r)\\ &= \sum_{r=2}^{n} r(r-1) \dfrac{n!}{(n-r)!r!} p ^{r}q ^{n-r}+E(X) \\ &= n(n-1)p ^{2}\sum_{r=2}^{n} \dfrac{(n-2)!}{(n-r)!(r-2)!} p ^{r-2}q ^{(n-2)-(r-2)}+np \\ &= n(n-1)p ^{2}\sum_{r=0}^{n-2} \dfrac{(n-2)!}{(n-(r+2))!r!} p ^{r}q ^{(n-2)-r}+np \\ &= n(n-1)p ^{2}\sum_{r=0}^{n-2} \dfrac{(n-2)!}{(n-2-r)!r!} p ^{r}q ^{(n-2)-r}+np \\ &= n(n-1)p ^{2}\sum_{r=0}^{n-2} {}_{n-2}C_{r} p ^{r}q ^{(n-2)-r}+np \\ &= n(n-1)p ^{2} (p+q) ^{n-2} + np \quad \left(\because (a+b) ^{n} = \sum_{r=0}^{n}{}_{n}C_{r}a ^{n-r}b ^{r} \right)\\ &= n(n-1)p ^{2} + np \quad \left( \because p + q = 1 \right) \\ &= n ^{2} p ^{2} - n p ^{2} + np = n ^{2} p ^{2} + np(1-p) \\ \end{split}\end{align} \tag*{}\]따라서 확률변수 \(X\) 의 분산은 다음과 같다.
\[ \begin{align}\begin{split} V(X) &= E(X ^{2}) - \{E(X)\} ^{2} \\ &= n ^{2} p ^{2} + np(1-p) - n ^{2}p ^{2} \\ &=npq \\ \end{split}\end{align} \tag*{} \]■
이항분포의 표준편차
확률변수 \(X\) 가 이항분포 \(B(n,p)\) 를 따를 때 이항분포의 표준편차는 \(q = 1-p\) 에 대하여 다음과 같다.
-
증명
표준편차의 정의에 의하여 쉽게 증명된다.
-
예시
각 면에 \(1,2,3,4\) 가 적혀있는 정사면체를 \(100\) 번 던져서 밑면의 숫자가 \(2\) 가 되는 횟수를 확률변수 \(X\) 라고 하자. \(X\) 의 평균, 분산, 표준편차를 구해보자. 먼저 \(100\) 의 시행이 독립시행이고 한 번의 시행에서 숫자 \(2\) 가 나올 확률이 \(\dfrac{1}{4}\) 이므로 확률변수 \(X\) 는 이항분포 \(B \bigg (100, \dfrac{1}{4} \bigg )\) 를 따른다. 따라서 확률변수 \(X\) 의 평균과 분산과 표준편차는 다음과 같다.
\[ E(X) = np = 100 \times \dfrac{1}{4} = 25 \]\[ V(X) = npq = 100 \times \dfrac{1}{4} \times \dfrac{3}{4} = \dfrac{75}{4} \]\[ \sigma (X) = \sqrt[]{\dfrac{75}{4}} = \dfrac{ 5 \sqrt[]{3}}{2} \]\(E(X) = 25\) 를 통해 정사면체를 \(100\) 번 던졌을 때 숫자 \(2\) 가 \(25\) 정도 나올 것이라고 생각할 수 있다.
Law of large number✔
체비셰프의 부등식(Bienaymé-Chebyshev Inequality)
확률변수 \(X\) 가 어떤 \(\mu \in \R\) 에 대하여 \(E(X) = \mu\) 이고 어떤 \(\sigma ^{2} \in \R _{>0}\) 에 대하여 \(V(X) = \sigma ^{2}\) 이면 모든 \(k>0\) 에 대하여 다음이 성립한다.
-
이 정리는 확률 분포를 정확히 모를 때 평균과 표준편차만으로 특정 확률의 최소값을 말해준다. 이 정리에 의하여 다음이 성립한다.
\[ P(|X - \mu | \leq k \sigma) \geq 1- \frac{1}{k ^{2}} \]\[ \leadsto P(\mu -k \sigma\leq X \leq \mu + k \sigma ) \geq 1- \frac{1}{k ^{2}} \]그러면 가령 \(X\) 가 \(\mu \pm 2\sigma\) 내에 있을 확률은 \(k = 2\) 로 두면 확률 분포에 관계 없이 \(1 - \frac{1}{2} ^{2} = \frac{3}{4}\) 이상이다.
-
증명
https://proofwiki.org/wiki/Bienaym%C3%A9-Chebyshev_Inequality#Proof_1
큰 수의 법칙(law of large number)
어떤 시행에서 사건 \(A\) 가 일어날 확률이 \(p\) 일 때 \(n\) 번의 독립시행에서 사건 \(A\) 가 일어나는 횟수를 \(X\) 라 하면 확률변수 \(X\) 는 이항분포 \(B(n, p)\) 를 따른다. 이때 임의의 양수 \(h\) 에 대하여 다음이 성립한다.
-
주사위를 \(n\) 번 던지는 시행에서 \(5\) 가 나오는 횟수를 \(X\) 라고 하자. 그러면 확률변수 \(X\) 는 \(n\) 번의 독립시행과 \(\dfrac{1}{6}\) 의 사건이 일어날 확률을 갖는 이항분포 \(B \bigg (n, \dfrac{1}{6}\bigg )\) 를 따른다. 그러므로 확률변수 \(X\) 의 확률질량함수 \(P(X=x)\) 는 \(x = 1,2,3, \dots, n\) 에 대하여
\[ P(X=x) = {}_{n}C_{x} \bigg (\dfrac{1}{6}\bigg ) ^{x} \bigg ( \dfrac{5}{6}\bigg ) ^{n-x} \]이다. 이제 \(n=10\) 번의 시행에서 \(5\) 가 \(X\) 번 나왔다고 하면 이것을 상대도수이자 확률 \(\dfrac{X}{10}\) 로 표현할 수 있다. 이 통계적 확률이 수학적 확률 \(\dfrac{1}{6}\) 과 얼마나 차이를 가지는가?
통계적 확률 \(\dfrac{X}{10}\) 과 수학적 확률 \(\dfrac{1}{6}\) 의 차이가 \(0.1\) 미만일 확률을 구해보면 다음과 같다.
\[ \begin{align}\begin{split} P \bigg ( \bigg | \dfrac{X}{10} - \dfrac{1}{6} \bigg | < 0.1 \bigg ) &=P \bigg ( -0.1 < \dfrac{X}{10} - \dfrac{1}{6} < 0.1 \bigg ) \\ &= P \bigg ( -1 < X - \dfrac{5}{3} < 1 \bigg ) = P \bigg ( \dfrac{2}{3} < X < \dfrac{8}{3} \bigg ) \\ &= P(X=1) + P(X=2) = 0.323 + 0.291 = 0.614 \\ \end{split}\end{align} \tag*{}\]그렇다면 시행을 \(30\) 번 반복했을 때 통계적 확률 \(\dfrac{X}{30}\) 과 수학적 확률 \(\dfrac{1}{6}\) 의 차이가 \(0.1\) 미만일 확률은 어떨까?
\[ \begin{align}\begin{split} P \bigg ( \bigg | \dfrac{X}{30} - \dfrac{1}{6} \bigg | < 0.1 \bigg ) &= P \bigg ( -0.1 < \dfrac{X}{30} - \dfrac{1}{6} < 0.1 \bigg ) \\ &= P \bigg ( 2 < X < 8 \bigg ) \\ &= P(X=3) + P(X=4) + \dots + P(X=7) \\ &= 0.137 + 0.185 + \dots + 0.110 = 0.784 \\ \end{split}\end{align} \tag*{}\]이제 시행횟수를 \(50\) 회로 높혀서 통계적 확률 \(\dfrac{X}{30}\) 과 수학적 확률 \(\dfrac{1}{6}\) 의 차이가 \(0.1\) 미만일 확률을 구해보자.
\[ \begin{align}\begin{split} P \bigg ( \bigg | \dfrac{X}{50} - \dfrac{1}{6} \bigg | < 0.1 \bigg ) &= P \bigg ( -0.1 < \dfrac{X}{50} - \dfrac{1}{6} < 0.1 \bigg ) \\ &= P \bigg ( \dfrac{10}{3} < X < \dfrac{40}{3} \bigg ) \\ &= P(X=4) + P(X=5) + \dots + P(X=13) \\ &= 0.040 + 0.075 + \dots + 0.032 = 0.946 \\ \end{split}\end{align} \tag*{}\]이처럼 시행횟수 \(n\) 이 증가할수록 더할 수 있는 \(P(X=x)\) 들이 많아지면서 통계적 확률 \(\dfrac{X}{n}\) 이 수학적 확률 \(\dfrac{1}{6}\) 과 차이가 \(0.1\) 미만일 확률도 증가한다. 그러면 \(n \to \infty\) 일 때 다음이 성립한다. 즉, 무한히 많은 시행이 이루어지면 통계적 확률과 수학적 확률의 차이가 \(0.1\) 미만일 확률이 \(100\%\) 가 된다. 이 결과는 양수 \(h\) 를 \(0.1\) 이 아니라 임의의 작은 양수로 만들어도 성립한다.
\[ \lim_{n \to \infty} P \bigg ( \bigg | \dfrac{X}{n} - \dfrac{1}{6} \bigg | < 0.1 \bigg ) = 1 \]그러므로 이제 양수 \(0.1\) 을 임의의 양수 \(h\) 로 두고 수학적 확률 \(\dfrac{1}{6}\) 도 일반적인 확률 \(p\) 로 잡자. 그러면 통계적확률(상대도수) \(\dfrac{X}{n}\) 과 수학적확률 \(p\) 이 똑같아질 확률이 무한한 시행이 이루어지면 \(100\%\) 가 된다는 결론을 얻는다.
\[ \lim_{n \to \infty} P \bigg ( \bigg | \dfrac{X}{n} - p \bigg | < h \bigg ) = 1 \]즉, 무한히 많은 시행이 이루어지면 통계적 확률이 수학적 확률과 같아진다.
-
증명
Bernoulli Distribution✔
베르누이 분포(bernoulli distribution)
베르누이 분포는 오직 두 가지 결과만 일어나는 실험을 단 한 번 시행하여 그 값이 \(0\) 또는 \(1\) 로 결정되는 확률변수 \(X\) 가 갖는 확률분포이다.
-
베르누이 분포는 이항분포의 특수한 경우에 불과하며, 이항분포의 특성을 상속받아 사건이 발생할 확률 \(p \in [0, 1]\) 에 대하여 다음과 같은 성질을 갖는다.
\[ P(X = 1) = p, \quad P(X = 0) = 1 - p, \quad P(X = x) = p ^{x}(1 - p) ^{1-x} \]\[ \Bbb{E}_{X}[X] = p, \quad V _{X}(x) = p(1 - p) \]
Multinoulli Distribution✔
멀티누이 분포(multinoulli distribution, categorical distribution)
두 가지 이상의 결과를 갖는 확률변수가 갖는 확률분포이다.
-
멀티누이 분포의 확률변수가 \(k\)개의 사건이 될 수 있다고 할 때 벡터 \(p \in [0, 1]^{k-1}\) 이 첫번째 사건과 \(k-1\)번째 사건까지의 확률을 표현해주고 \(k\)번째 사건의 확률은 \(1 - 1 ^{\top}p\) 가 된다.
-
멀티누이 분포는 다항분포의 특수한 경우이다. 이항분포도 다항분포의 특수한 경우이지만, 멀티누이 분포가 이항분포의 특수한 경우는 아니다.
Multinomial Distribution✔
다항분포(multinomial distribution)
어떤 시행이 \(k\)가지 값을 가지고, 그 값이 나타날 확률이 \(p_1, \dots, p_k\) 라고 할 때 \(n\)번의 시행에서 \(i\)번째 값이 \(x_i\) 회 나타날 확률
을 확률질량함수로 갖는 확률분포이다.
- 이항분포, 베르누이 분포, 멀티누이 분포가 다항분포의 특수한 경우이다.
Continuous Probability Distribution✔
연속확률변수(continuous random variable)
어떤 구간에 속하는 모든 실수의 값을 가지는 확률변수 \(X\) 이다.
-
예시
신생아 \(100\) 명의 몸무게를 측정할 때 측정값을 \(X\) 로 두면 \(X\) 값은 kg 단위로 다음과 같을 수 있다. 이 확률변수 \(X\) 는 어떤 구간 내에서 모든 실수 값을 가지므로 연속확률변수이다.
\[ X = 2.54, 3.1, 4.0, 2.9, \dots \]
확률밀도함수(probability density function)
연속확률변수 \(X\) 가 구간 \([\alpha , \beta ]\) 에 속하는 모든 실수 값을 가질 때 \(X\) 의 확률분포를 나타내는 함수 \(f(x)\) 이다.
-
확률밀도함수에서는 특정 상태의 확률을 직접 알아내는 것이 아니라 특정 구간 \([a, b]\) 에서 확률 영역 \(\displaystyle \int_{[a,b]}^{}p(x)dx\) 를 구하는 식으로 확률을 구한다.
-
대표적인 확률밀도함수가 정규분포곡선이다.
연속확률분포(continuous probability distribution)
확률밀도함수를 이용해 분포를 표현할 수 있는 확률분포이다.
- 연속확률분포에는 정규분포(normal distribution), 지수분포(exponential distribution), 스튜던트 \(t\) 분포(Student's t-distribution), 파레토 분포(Pareto distribution), 로지스틱 분포(logistic distribution) 등등이 있는데, 이산확률분포도 무한히 반복하면 연속확률분포 중 하나로 수렴한다.
확률밀도함수의 성질
구간 \([\alpha , \beta ]\) 에 속하는 모든 실수 값을 가지는 연속확률변수 \(X\) 의 확률분포를 나타내는 확률밀도함수 \(f(x)\) 는 다음 성질을 만족한다.
-
\(\alpha \leq x \leq \beta :f(x) \geq 0\)
-
\(\displaystyle \int_{\alpha }^{\beta }f(x)dx=1\)
-
\(\displaystyle P(a \leq X \leq b) = \int_{a}^{b}f(x)dx\)
-
\(\displaystyle P(a \leq X \leq b) = P(a < X \leq b) = P(a \leq X < b) = P(a < X < b)\)
-
증명
4:
연속확률변수 \(X\) 가 하나의 값 \(a\) 을 가질 확률은 \(F'(x) =f(x)\) 에 대하여 다음과 같이 \(0\) 이다.
\[ P(X = a) = P(a \leq X \leq a) = \int_{a}^{a}f(x)dx = F(a)-F(a) = 0 \] -
예시
구간 \([0, 3]\) 위에서 정의된 연속확률변수 \(X\) 의 확률밀도함수 \(f(x) = \dfrac{2}{9}x\) 을 갖는 확률변수 \(X\) 가 \(1 \leq X \leq 2\) 일 확률 \(P(1 \leq X \leq 2)\) 은 다음과 같다.
\[ P(1 \leq X \leq 2) = \int_{1}^{2}\dfrac{2}{9}x dx = \bigg [ \dfrac{1}{9}x ^{2} \bigg ] ^{2} _{1} = \dfrac{3}{9} = \dfrac{1}{3} \]이다. \(X\) 가 \(X \geq \dfrac{5}{2}\) 일 확률 \(P \bigg (X \geq \dfrac{5}{2} \bigg )\) 은 다음과 같다.
\[ \begin{align}\begin{split} P \bigg (X \geq \dfrac{5}{2} \bigg ) &= P \bigg (\dfrac{5}{2} \leq X \leq 3 \bigg ) = \int_{5/2}^{3} \dfrac{2}{9}x dx \\ &= \bigg [ \dfrac{1}{9}x ^{2} \bigg ] ^{3} _{5/2} = 1 - \dfrac{25}{36} = \dfrac{11}{36} \\ \end{split}\end{align} \tag*{} \]
연속확률변수의 평균
구간 \([\alpha, \beta ]\) 위의 연속확률변수 \(X\) 의 확률밀도함수가 \(f(x)\) 의 평균은 다음과 같다.
-
평균은 변량에 확률을 곱한 것의 총합이므로 연속확률변수 \(X\) 의 평균도 다음과 같이 구간 \([\alpha , \beta ]\) 에서 정의된 확률질량함수 \(f(x)\) 에 대하여 변량 \(x\) 와 확률 \(f(x)\) 을 곱한 것의 총합으로 평균을 구한다.
-
머신러닝에서 기댓값은 보통 이렇게 표기된다. 연속확률분포 \(p(X)\) 를 따르는 확률질량함수 \(f(x)\) 의 기댓값은 다음과 같다.
\[ \Bbb{E}_{X \ssim p}[f(x)] = \int p(x)f(x)dx \]확률분포가 문맥상 명확할 때 단순히 \(\Bbb{E}_{X}[f(x)]\) 라고 표기한다. 확률변수도 문맥상 명확하면 더욱 단순히 \(\Bbb{E}[f(x)]\) 라고 표기한다.
연속확률변수의 분산
구간 \([\alpha, \beta ]\) 위의 연속확률변수 \(X\) 의 확률밀도함수가 \(f(x)\) 의 분산은 다음과 같다.
-
증명
분산은 편차 제곱의 평균이다. 구간 \([\alpha , \beta ]\) 위의 확률질량함수 \(f(x)\) 에 대한 연속확률변수 \(X\) 의 분산은 다음과 같다.
\[ \begin{align}\begin{split} V(X) &= E((X - \mu ) ^{2}) = \int_{\alpha }^{\beta }(x - \mu ) ^{2}f(x)dx \\ &= \int_{\alpha }^{\beta } \{ x ^{2}f(x) - 2x \mu f(x) + \mu ^{2} f(x) \} dx \\ &= \int_{\alpha }^{\beta } x ^{2}f(x) dx -2 \mu \int_{\alpha }^{\beta } x f(x) dx + \mu ^{2} \int_{\alpha }^{\beta } f(x) dx \\ &= \int_{\alpha }^{\beta } x ^{2}f(x) dx -2 \mu \cdot \mu + \mu ^{2} \cdot 1 \quad \left( \because \int_{\alpha }^{\beta }f(x) dx = 1 \right)\\ &= \int_{\alpha }^{\beta } x ^{2}f(x) dx - \mu ^{2} = E(X ^{2}) - \{E(X)\} ^{2}\\ \end{split}\end{align} \tag*{} \]■
연속확률변수의 표준편차
구간 \([\alpha, \beta ]\) 위의 연속확률변수 \(X\) 의 확률밀도함수가 \(f(x)\) 의 표준편차은 다음과 같다.
-
예시
구간 \([-1,2]\) 위의 확률밀도함수 \(\displaystyle f(x) = \dfrac{4}{9} - kx\) 를 갖는 연속확률변수 \(X\) 를 생각하자.
먼저 \(k\) 값을 구해보면 \(\displaystyle \int_{-1}^{2} f(x)dx = 1\) 이므로 다음과 같다.
\[ \int_{-1}^{2} \bigg ( \dfrac{4}{9} - kx \bigg ) dx = \bigg [ \dfrac{4}{9}x - \dfrac{k}{2}x ^{2} \bigg ] ^{2} _{-1} =\dfrac{4}{3}-\dfrac{3}{2}k = 1 \implies k = \dfrac{2}{9}\]확률변수 \(X\) 의 평균, 분산, 표준편차를 구해보자.
\[ \begin{align}\begin{split} E(X) &= \int_{-1}^{2}xf(x)dx =\int_{-1}^{2}x \bigg ( \dfrac{4}{9}-\dfrac{2}{9}x \bigg )dx \\ &=\int_{-1}^{2} \bigg (\dfrac{4}{9}x - \dfrac{2}{9}x ^{2} \bigg )dx = \bigg [ \dfrac{2}{9}x ^{2} - \dfrac{2}{27}x ^{3} \bigg ] ^{2}_{-1} = \dfrac{2}{3}-\dfrac{2}{3}=0 \\ \end{split}\end{align} \tag*{}\]\[ \begin{align}\begin{split} V(X) &= E(X ^{2}) - \{E(X)\} ^{2} = \int_{-1}^{2}x ^{2}f(x)dx - 0 ^{2} \\ &= \int_{-1}^{2} \bigg ( \dfrac{4}{9}x ^{2}-\dfrac{2}{9}x ^{3} \bigg ) dx = \bigg [ \dfrac{4}{27}x ^{3} - \dfrac{1}{18}x ^{4} \bigg ] ^{2} _{-1} = \dfrac{1}{2} \\ \end{split}\end{align} \tag*{}\]\[ \sigma (X) = \sqrt[]{V(X)} = \sqrt[]{\dfrac{1}{2}} \]
연속확률변수의 평균, 분산, 표준편차의 성질
연속확률변수 \(X\) 와 두 상수 \(a, b(a \neq 0)\) 에 대하여 다음이 성립한다.
-
\(E(aX+b) = aE(X) + b\)
-
\(V(aX+b) = a ^{2} V(X)\)
-
\(\sigma (aX+b) = |a| \sigma (X)\)
-
증명
구간 \([\alpha,\beta]\) 위의 연속확률변수 \(X\) 의 확률밀도함수가 \(f(x)\) 에 대하여 다음이 성립한다.
\[ \begin{align}\begin{split} E(aX + b) &= \int_{\alpha }^{\beta }(ax + b) f(x)dx \\ &= a \int_{\alpha }^{\beta }xf(x)dx + b \int_{\alpha }^{\beta }f(x)dx \\ &= a E(X)+b \\ \end{split}\end{align} \tag*{} \]\[ \begin{align}\begin{split} V(aX+b) &= \int_{\alpha }^{\beta }\{ax+b-(a \mu +b) \}^{2}f(x)dx \\ &= a ^{2} \int_{\alpha }^{\beta }(x-\mu) ^{2}f(x)dx \\ &= a ^{2}V(X) \\ \end{split}\end{align} \tag*{} \]\[ \sigma (aX+b) = \sqrt[]{a ^{2} {V(X)}} = |a|\sigma (X) \]■
Normal Distribution✔
정규분포(normal distribution, 가우스 분포, Gaussian distribution)
연속확률변수 \(X\) 의 확률밀도함수 \(N(x; \mu , \sigma ^{2})\) 의 평균 \(\mu \in \R\), 표준편차 \(\sigma \in (0, \infty)\) 에 대하여 \(N(x; \mu , \sigma ^{2})\) 가 구간 \((-\infty , \infty )\) 에서
와 같이 정의될 때 확률변수 \(X\) 의 확률분포를 정규분포 \(N(\mu , \sigma ^{2})\) 라 한다.
-
자연 대상을 관찰하여 얻은 상대도수를 계급의 크기를 충분히 작게하여 히스토그램으로 나타내면 다음과 같이 정규분포에 가까워진다.
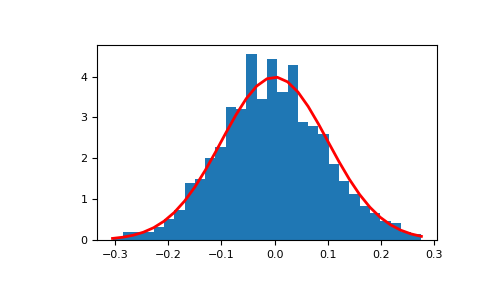
-
\(X\) 의 확률분포가 정규분포를 따를 때 확률밀도함수 \(y = N(x; \mu , \sigma ^{2})\) 의 그래프를 정규분포곡선이라 한다. 다음 그래프는 정규분포 \(N(1, 1)\) 을 따르는 확률변수 \(X\) 의 확률밀도함수 \(\displaystyle N(x; \mu , \sigma ^{2}) = \dfrac{1}{\sqrt[]{2 \pi } } e ^{- \frac{(x-1)^{2}}{2 }}\) 의 정규분포곡선이다.
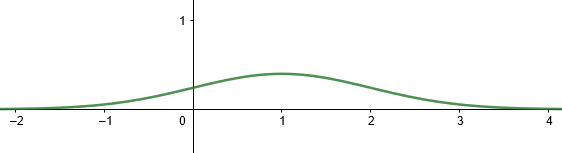
-
그러나 실제로 정규분포의 확률밀도함수를 계산할 때 \(\sigma ^{2}\) 의 제곱근의 역수를 취해야 하는 불편함이 있다. 따라서 실제로 \(\beta \in (0, \infty)\) 에 대하여 다음과 같은 형태로 정규분포를 다루는 경우가 많다.
\[ N(x; \mu , \beta ^{-1}) = \sqrt[]{\dfrac{\beta }{2 \pi} } \exp \left( - \frac{1}{2 }\beta (x- \mu )^{2}\right)\]
정규분포의 성질
연속확률변수 \(X\) 의 확률밀도함수 \(N(x; \mu , \sigma ^{2})\) 의 평균 \(\mu\) 과 표준편차 \(\sigma (>0)\) 에 대하여 \(X\) 가 정규분포를 따를 때 다음이 성립한다.
-
\(N(x; \mu , \sigma ^{2})\) 의 그래프가 직선 \(x=\mu\) 에 대하여 좌우 대칭인 종 모양 곡선이다.
-
\(N(x; \mu , \sigma ^{2})\) 의 최댓값은 \(x=\mu\) 에서 \(\dfrac{1}{\sigma\sqrt[]{2 \pi } }\) 이다.
-
\(x\) 축을 점근선으로 가진다.
-
\(\displaystyle \int_{-\infty }^{\infty }N(x; \mu , \sigma ^{2})dx = 1\)
-
표준편차 \(\sigma\) 가 일정할 때 평균 \(\mu\) 에 따라 대칭축의 위치는 바뀌지만 곡선의 모양은 불변한다.
-
평균 \(\mu\) 가 일정할 때 표준편차 \(\sigma\) 가 커지면 곡선의 가운데 부분이 낮아지면서 양쪽으로 퍼지고 표준편차 \(\sigma\) 가 작아지면 곡선 가운데 부분이 높아지면서 좁아진다.
-
5:
표준편차 \(\sigma\) 가 일정할 때 평균 \(\mu\) 에 따라 대칭축의 위치는 바뀌지만 곡선의 모양은 불변한다. 각각 정규분포 \(N \bigg (0, \dfrac{1}{3} \bigg ), N \bigg (1, \dfrac{1}{3} \bigg ), N \bigg (2, \dfrac{1}{3} \bigg )\) 을 따르는 그래프
\[ y = \dfrac{3}{\sqrt[]{2 \pi }}e ^{-9 \frac{x ^{2}}{2}} , y = \dfrac{3}{\sqrt[]{2 \pi }}e ^{-9 \frac{(x-1) ^{2}}{2}} , y = \dfrac{3}{\sqrt[]{2 \pi }}e ^{-9 \frac{(x-2) ^{2}}{2}} \]를 순서대로 다음과 같이 그려보자.
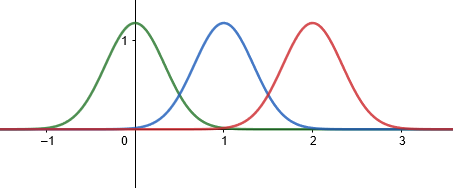
6:
평균 \(\mu\) 가 일정할 때 표준편차 \(\sigma\) 가 커지면 곡선의 가운데 부분이 낮아지면서 양쪽으로 퍼지고 표준편차 \(\sigma\) 가 작아지면 곡선 가운데 부분이 높아지면서 좁아진다.
각각 정규분포 \(N \bigg (0, \dfrac{1}{3} \bigg ), N \bigg (0, \dfrac{1}{2} \bigg ), N (0, 1)\) 을 따르는 그래프
\[ y = \dfrac{3}{\sqrt[]{2 \pi }}e ^{-9 \frac{x ^{2}}{2}} , y = \dfrac{2}{\sqrt[]{2 \pi }}e ^{-2 x ^{2}} , y = \dfrac{1}{\sqrt[]{2 \pi }}e ^{- \frac{x ^{2}}{2}} \]를 다음과 같이 그려보자. 순서대로 빨간선, 파란선, 초록선이다.
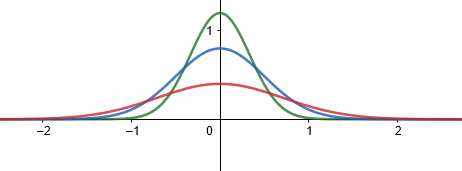
Standard Normal Distribution✔
표준정규분포(standard normal distribution)
평균과 표준편차가 \(\mu=0, \sigma = 1\) 인 정규분포를 표준정규분포 \(N(0, 1)\) 라 한다.
-
표준정규분포를 따르는 확률변수는 특별히 \(Z\) 또는 \(z\) 로 표기한다.
-
자연 대상을 관찰하여 정리하면 그 특성이 정규분포에 수렴한다. 자연 대상이 어떤 범위에 속하는 확률을 구해야 한다면 다음과 같이 복잡한 정규분포곡선을 항상 적분해야만 한다. 그런데 이것은 너무 귀찮다.
\[ N(x; \mu , \sigma ^{2}) = \dfrac{1}{\sqrt[]{2 \pi } \sigma } e ^{- \frac{(x- \mu )^{2}}{2 \sigma ^{2}}} \]따라서 평균과 표준편차가 \(\mu=0, \sigma = 1\) 인 정규분포를 표준정규분포로 정의하여 표준정규분포의 확률밀도함수
\[ N(x; 0 , 1) = \dfrac{1}{\sqrt[]{2 \pi } } e ^{- \frac{x^{2}}{2} } \]에 대한 적분값을 미리 계산해둔다. 그러면 모든 정규분포들을 표준정규분포로 표준화시켜서 미리 계산해둔 값을 사용할 수 있다. 표준정규분포에 대한 적분 결과가 정리된 것이 표준정규분포표이다.
-
확률변수 \(Z\) 에 대한 표준정규분포의 확률밀도함수 \(\displaystyle f(z) = \dfrac{1}{\sqrt[]{2 \pi } } e ^{- z^{2}/2 }\) 의 그래프개형은 다음과 같다.
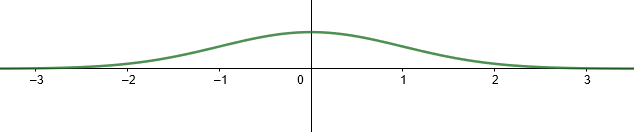
표준점수(standard score, 표준값, \(z\) 값, \(z\) value, \(z\) 점수, \(z\) score)
정규분포의 어떤 수치 \(x\) 의 표준점수는 모집단의 표준편차 \(\sigma\) 와 모집단의 평균 \(\mu\) 에 대하여 다음과 같은 무차원 수이다.
-
표준정규분포를 따르는 확률변수로써 정규분포를 구성하는 한 원소가 표준정규분포의 어떤 위치에 있는지 보여주는 무차원 수이다. 통상적으로 시험성적을 평가할 때 원점수로는 시험의 난이도를 알아볼 수 없다. 다음 예시에서 알 수 있듯이 원수치의 상대적 위치를 알기 위하여 표준점수를 사용한다.
-
예시
어떤 학생이 영어에서는 \(80\) 점을 받았고 수학에서는 \(50\) 점을 받았다면 정말로 수학보다 영어를 잘한 것일까? 그 학교의 학생들의 영어점수와 수학점수를 확률변수 \(X_1, X_2\) 로 두고 조사했는데 두 확률변수가 각각 정규분포
\[ N(95, 5 ^{2}), N(20, 2 ^{2}) \]를 따랐다고 하자. 그러면 이 학생의 영어 표준점수와 수학 표준점수는 각각
\[ z _{1} = \dfrac{80 - 95}{5} = -3, z _{2} = \dfrac{50 - 20}{2} = 15 \]이다. 이로써 수학을 영어보다 훨씬 잘했다는 것을 알 수 있다.
편차치(\(T\) 점수, \(T\) score)
편차치는 표준점수 \(z\) 에 대하여 \(t = 10 z + 50\) 이다.
- 편차치는 표준점수에서 음수가 나오는 것을 극복하기 위한 점수이다.
표준정규분포표
표준정규분포 \(N(0, 1)\) 를 따르는 확률변수 \(Z\) 와 양수 \(a\) 에 대한 다음과 같은 확률의 적분값들을 미리 정리해둔 표이다.
-
예시
표준정규분포를 따르는 확률분포에서 확률 \(\displaystyle P(0 \leq Z \leq 1.76) = \int_{0}^{1.76}\dfrac{1}{\sqrt[]{2 \pi } } e ^{- \frac{z^{2}}{2} }\) 은 다음과 같은 표준정규분포표에서 \(0.4608\) 임을 알 수 있다.
\(z\) \(0.00\) \(\dots\) \(0.06\) \(\vdots\) \(1.7\) \(0.4608\) -
표준정규분포표를 통하여 모든 경우의 구간에 대한 확률을 구할 수 있다. \(0 < a \leq b\) 에 대하여 다음이 성립한다는 것을 통하여 구간을 적절히 변환시켜 표준정규분포표를 사용하게 할 수 있다.
\[ P(a \leq Z \leq b) = P(0 \leq Z \leq b) - P(0 \leq Z \leq a) \]\[ P(-a \leq Z \leq b) = P(0 \leq Z \leq b) + P(0 \leq Z \leq a) \]\[ P(-a \leq Z \leq a) = 2P(0 \leq Z \leq a) \]\[ P(Z \geq a) = 0.5 - P(0 \leq Z \leq a) \]\[ P(Z \leq a) = 0.5 + P(0 \leq Z \leq a) \]
정규분포를 표준화하여 확률을 구해도 그 값을 불변한다.
-
증명
\(x = \sigma z\) 로 두고 치환적분법을 적용하면 다음을 얻는다.
\[ \begin{align}\begin{split} P(\mu \leq X \leq \mu + \sigma ) &=\int_{\mu }^{\mu + \sigma } \dfrac{1}{\sqrt[]{2 \pi } \sigma }e ^{- \frac{(x-\mu )^{2}}{2 \sigma ^{2}}}dx = \int_{0 }^{\sigma } \dfrac{1}{\sqrt[]{2 \pi } \sigma }e ^{- \frac{x^{2}}{2 \sigma ^{2}}}dx \\ &= \int_{0}^{1} \dfrac{1}{\sqrt[]{2 \pi }}e ^{-\frac{z ^{2}}{2}}dz = P(0 \leq Z \leq 1) \\ \end{split}\end{align} \tag*{}\]즉, 표준화를 해도 구간에 대한 확률밀도함수의 넓이, 즉 확률이 동일하다. ■
정규분포의 표준화(standardization)
정규분포를 표준정규분포로 변환하는 것으로써 확률변수 \(X\) 가 정규분포 \(N(\mu , \sigma ^{2})\) 를 따를 때 \(X\) 를 확률변수 \(Z = \dfrac{X - \mu }{\sigma }\) 로 변환하여 표준정규분포 \(N(0, 1)\) 를 따르게 하는 것이다.
-
다양한 정규분포의 계산을 쉽게 하려고 표준정규분포를 만든 것을 이해하였으니 이제 실제로 정규분포를 표준정규분포로 변환하여 사용하는 법을 알아봐야 한다. 임의의 값을 갖는 평균과 표준편차 \(\mu , \sigma\) 에 대하여 확률변수 \(X\) 의 확률분포가 정규분표 \(N(\mu , \sigma ^{2})\) 를 따른다고 하자. 이제 확률변수 \(Z\) 를 \(Z = \dfrac{X - \mu }{\sigma }\) 로 정의하자. 그러면 확률변수 \(Z\) 의 평균과 분산은 다음과 같다.
\[ E(Z) = E \bigg (\dfrac{X - \mu }{\sigma } \bigg ) = E \bigg (\dfrac{1}{\sigma }X - \dfrac{\mu }{\sigma } \bigg ) = \dfrac{1}{\sigma}E(X) - \dfrac{\mu }{\sigma } = \dfrac{\mu }{\sigma } - \dfrac{\mu }{\sigma } = 0 \]\[ Z(Z) = Z \bigg (\dfrac{X - \mu }{\sigma } \bigg ) = V \bigg (\dfrac{1}{\sigma }X - \dfrac{\mu }{\sigma } \bigg ) = \dfrac{1}{\sigma ^{2}}V(X) = \dfrac{\sigma ^{2}}{\sigma ^{2}} = 1 \]따라서 확률변수 \(Z\) 는 표준정규분포 \(N(0, 1)\) 를 따르게 된다.
-
확률변수 \(X\) 를 표준정규분포로 변환하였으니 \(X\) 의 확률을 구할 때 일일이 적분할 필요 없이 확률도 다음과 같이 변환하여 표준정규분포표를 사용하면 된다.
\[ \begin{align}\begin{split} P(a \leq X \leq b) &= \displaystyle P \left(\dfrac{a - \mu }{\sigma } \leq \dfrac{X- \mu }{\sigma } \leq \dfrac{b- \mu }{\sigma } \right) \\ &= P \bigg (\dfrac{a- \mu }{\sigma } \leq Z \leq \dfrac{b- \mu }{\sigma } \bigg )\\ \end{split}\end{align} \tag*{} \] -
예시
확률변수 \(X\) 가 정규분포 \(N(10, 2 ^{2})\) 를 따르고 표준정규분포표가 다음과 같을 때 \(P(12 \leq X \leq 14)\) 를 구하자.
\(z\) \(P(0 \leq Z \leq z)\) \(1.0\) \(0.3413\) \(2.0\) \(0.4772\) 정규분포를 확률변수 \(Z = \dfrac{X - \mu }{\sigma }\) 를 이용하여 표준정규분포로 표준화하면 다음을 얻는다.
\[ \begin{align}\begin{split} P(12 \leq X \leq 14) &=P \bigg ( \dfrac{12-10}{2} \leq \dfrac{X-10}{2} \leq \dfrac{14-10}{2} \bigg ) \\ &= P(1 \leq Z \leq 2) = P(0 \leq Z \leq 2) - P(0 \leq Z \leq 1) \\ &= 0.4772 - 0.3413 = 0.1359 \end{split}\end{align} \tag*{} \]확률을 약 \(13.5\%\) 로 생각할 수 있다.
-
표준화의 이점은 분포상태가 다른 변량끼리의 비교를 할 수 있게 해준다는 것이다.
-
예시
한 학교의 학생들의 영어점수와 수학점수를 확률변수 \(X_1, X_2\) 로 두고 조사했는데 두 확률변수가 각각
\[ N(70, 5 ^{2}), N(50, 2 ^{2}) \]를 따랐다. 이때 학생 \(A\) 의 영어 점수와 수학 점수가 각각 \(80, 60\) 이라고 하자. 그러나 학생들의 영어점수와 수학점수 \(X_1, X_2\) 를 표준화시켜 \(N(0, 1)\) 을 따르게 하면 학생 \(A\) 의 영어 점수와 수학 점수가 각각
\[ Z_1 = \dfrac{80 - 70}{5} = 2, Z_2 = \dfrac{60 - 50}{2} = 5 \]가 된다. 즉, 학생 \(A\) 의 수학 성적이 영어 성적보다 높다.
-
예시
한 회사에서 신입 사원 \(60\) 명을 모집하는데 \(500\) 명이 지원했다고 하자. 지원자들의 입사 시험 점수의 평균이 \(74\) 점이고 표준편차가 \(10\) 점인 정규분포 \(N(74, 10 ^{2})\) 를 따른다고 하자. 이때 회사에 입사하기 위한 최저 점수를 구해보자. 먼저 지원자의 시험 점수를 확률변수 \(X\) 로 두면 이것은 정규분포 \(N(74, 10 ^{2})\) 를 따르고 입사할 확률(비율)이 \(\dfrac{60}{500} = 0.12\) 이므로 입사 최저 점수를 \(a\) 로 두면 확률변수 \(X\) 가 \(a\) 보다 클 확률(또는 \(a\) 보다 큰 \(X\) 들의 비율) 은 다음과 같다.
\[ P(X \geq a) = 0.12 \]정규분포를 표준화하여 새로운 확률변수 \(Z = \dfrac{X - \mu }{ \sigma } = \dfrac{X - 74}{10}\) 를 만들면 이것은 표준정규분포 \(N(0, 1)\) 를 따른다. 따라서
\[ \begin{align}\begin{split} P(X \geq a) &=P \bigg ( \dfrac{X-74}{10} \geq \dfrac{a-74}{10} \bigg ) = P \bigg ( Z \geq \dfrac{a-74}{10} \bigg ) \\ &= 0.5 - P \bigg ( 0 \leq Z \leq \dfrac{a-74}{10} \bigg ) = 0.12 \\ \end{split}\end{align} \tag*{} \]에서 다음을 얻을 수 있다.
\[ P \bigg ( 0 \leq Z \leq \dfrac{a-74}{10} \bigg ) = 0.38 \]그런데 표준정규분포표에 따라 확률값 \(0.38\) 은 \(z\) 값이 \(1.2\) 일 때 해당한다. 그러므로 \(\dfrac{a-74}{10}=1.2\) 에서 다음을 얻을 수 있다.
\[ a = 86 \]이로써 입사 최저 점수를 \(86\) 점이라고 예측할 수 있다.
이항분포와 정규분포의 관계
확률변수 \(X\) 가 이항분포 \(B(n, p)\) 를 따를 때 \(n\) 이 충분히 크면 큰 수의 법칙에 의하여 \(X\) 는 근사적으로 \(q=1-p\) 에 대한 정규분포 \(N(np, npq)\) 를 따른다.
-
이산확률변수 \(X\) 가 이항분포 \(B(n, p)\) 를 따를 때 시행 횟수 \(n\) 이 조금만 커지면 확률을 계산하는 것이 쉽지 않다. 그런데 이때 시행횟수 \(n\) 을 충분히 크게하면 큰 수의 법칙에 의하여 확률변수 \(X\) 가 근사적으로 평균과 분산과 표준편차가 각각 \(q = 1-p\) 에 대하여
\[\mu = np, V(X) = npq, \sigma (X)= \sqrt[]{npq}\]인 정규분포 \(N(np,npq)\) 를 따른다. 따라서 \(n\) 이 충분히 클 때 이항분포를 정규분포에 근사시킨 후 표준정규분포로 정규화시키면 확률을 쉽게 구할 수 있다.
-
예시
안타를 칠 확률이 \(40\%\) 인 야구선수가 \(150\) 번의 타석에서 \(75\) 개 이상의 안타를 칠 확률을 구해보자. 안타수를 확률변수 \(X\) 로 두면 안타를 칠 확률이 \(40\% = \dfrac{2}{5}\) 이므로 \(X\) 는 이항분포
\[ B \bigg (150, \dfrac{2}{5} \bigg ) \]를 따른다. \(150\) 의 시행이 충분히 크다고 한다면 이 확률분포를 정규분포
\[ N(np, npq) = N \bigg (150 \times \dfrac{2}{5}, 150 \times \dfrac{2}{5} \times \dfrac{3}{5} \bigg ) = N(60, 6 ^{2}) \]에 근사시킬 수 있다. 그러므로 이 정규분포를 표준화하여 표준정규분포로 만들면 다음을 얻는다.
\[ \begin{align}\begin{split} P(X \geq 75) &= P \bigg (\dfrac{X-60}{6} \geq \dfrac{75-60}{6} \bigg ) \\ &= P(Z \geq 2.5) = 0.5 - P(0 \leq Z \leq 2.5) \\ &= 0.5 - 0.4938 = 0.0062 \\ \end{split}\end{align} \tag*{} \]즉, 구하고자 하는 확률은 근사적으로 \(0.0062\) 이다.
Joint Probability Distribution✔
결합분포(joint probability distribution)
두 개 이상의 사건이 동시에 일어나는 사건이 갖는 확률 분포이다.
-
즉, 두 개 이상의 확률 변수 함께 고려하는 확률 분포이다.
-
이산 확률 변수 \(X, Y\) 에 대한 확률 질량 함수를 \(P(X = x, Y = y)\) 로 표기하고 다음이 성립한다.
-
\(P(X = x, Y = y) = P(Y = y|X = x)P(X = x) = P(X = x| Y = y)P(Y = y)\)
-
\(\displaystyle \sum_{x}^{}\sum_{y}^{}P(X = x, Y = y) = 1\)
연속 확률 변수 \(X, Y\) 에 대한 확률 밀도 함수를 \(f _{X,Y}(x, y)\) 로 표기하고 다음이 성립한다.
-
\(f _{X, Y}(x, y) = f _{Y|X}(y|x)f _{X}(x) = f _{X|Y}(x|y)f _{Y}(y)\)
-
\(\displaystyle \int_{x}^{}\int_{y}^{} f _{X, Y}(x, y)dy dx = 1\)
-
-
예시
두 주사위를 던져서 첫번째 주사위가 짝수인 사건을 확률 변수 \(A = 1\), 그렇지 않을 경우를 \(A = 0\) 로 정의하고 두번째 주사위가 소수일 사건을 확률 변수 \(B = 1\), 그렇지 않을 경우를 \(B = 0\) 로 정의하자. 그러면 두 확률변수는 주사위의 눈에 따라 다음과 같이 정의된다.
1 2 3 4 5 6 \(A\) 0 1 0 1 0 1 \(B\) 0 1 1 0 1 0 확률 변수 \(A, B\) 에 대한 확률 질량 함수는 다음과 같이 정의된다.
\[ P(A = 0, B = 0) = P \{1\} = \frac{1}{6} \]\[ P(A = 1, B = 0) = P \{4, 6\} = \frac{2}{6} \]\[ P(A = 0, B = 1) = P \{3, 5\} = \frac{2}{6} \]\[ P(A = 1, B = 1) = P \{2\} = \frac{1}{6} \]이들을 모두 합하면 \(\displaystyle \sum_{a}^{}\sum_{b}^{}P(A = a, B = b) = 1\) 이 된다.
Conditional Distribution✔
조건부 분포(conditional distribution)
결합분포로 조건부확률을 다음과 같이 나타낼 수 있다.
- 조건부확률을 순수하게 확률로 나타내면 분자가 \(P(A \cap B)\) 인데 비해 확률변수로 나타내면 분자가 결합확률 \(P(X, Y)\) 이 된다.
조건부 확률의 연쇄법칙(chain rule of conditional probability)
확률변수 \(X_1, X_2, \dots, X_n\) 에 대한 결합분포 \(P(X_1, X_2, \dots, X_n)\) 에 대하여 다음이 성립한다.
-
이는 결합분포의 정의 \(P(X, Y) = \dfrac{P(Y | X)}{P(X)}\) 에서 곧바로 도출된다. 가령 세 확률변수에 대하여 다음이 성립한다.
\[ \begin{align}\begin{split} P(a, b, c) &= P(a|b, c) P(b, c) \\ P(b, c) &= P(b | c)P(c) \\ \implies P(a, b, c) &= P(a |b, c)P(b |c) P(c) \end{split}\end{align} \tag*{} \]
Uniform Distribution✔
이산균등분포(discrete uniform distribution)
이산확률분포의 확률질량함수의 값이 모든 곳에서 일정한 분포이다.
-
즉, 확률변수가 \(k_1, k_2, \dots, k_n\) 의 값을 갖는 이산균등분포에 대하여 \(P(X = k_i) = \dfrac{1}{n}\) 이다. 가령 주사위는 확률변수가 \(1,2,3,4,5,6\) 의 값을 갖고 각 확률이 동등하게 \(\dfrac{1}{6}\) 인 이산균등분포를 따른다.
-
이산균등분포의 확률질량함수는 대략 다음과 같이 그려진다.

연속균등분포(continuous uniform distribution)
연속확률분포의 확률밀도함수의 값이 모든 곳에서 일정한 분포이다.
-
연속균등분포는 두 매개변수 \(a, b\) 에 대하여 구간 \([a, b]\) 에서 균등한 확률을 가지도록 정의된다. 즉, 연속균등분포의 확률밀도함수는 다음과 같이 정의된다.
\[ f(x) = \begin{cases} \dfrac{1}{b-a} & x \in [a, b]\\ 0 & x \not\in [a, b]\\ \end{cases} \]이러한 연속균등분포를 보통 \(U(a, b)\) 로 표기한다. 특히 \(U(0, 1)\) 을 표준연속균등분포(standard uniform distribution)라 한다.
-
확률변수 \(X\) 가 연속균등분포 \(U(a, b)\) 를 따른다는 것을 \(X \ssim U(a, b)\) 로 표현한다.
-
연속균등분포의 확률밀도함수는 대략 다음과 같이 그려진다.

Marginal Distribution✔
주변 분포(marginal distribution)
확률분포의 부분집합에 속한 확률 변수들의 확률분포이다.
-
예시
이산확률변수 \(X, Y\) 의 결합분포 \(P(X, Y)\) 에 대하여 합의 법칙에 의하여 다음과 같이 \(P(X)\) 를 구할 수 있다.
\[ \forall x \in X : P(X = x) = \sum_{y}^{}P(X = x, Y = y) \]연속확률변수의 결합분포에 대해서는 다음과 같이 적분을 하면 같은 연산을 수행할 수 있다.
\[ p(x) = \int p(x, y)dy \]
Exponential and Laplace Distribution✔
지수 분포(exponential distribution)
다음과 같은 확률밀도함수를 갖는 분포를 지수 분포라 한다.
-
지수함수는 딥러닝에서 다음과 같이 \(x = 0\) 에서 뾰족한 점을 가져야 하는 상황에서 필요하다.

라플라스 분포(Laplace distribution)
확률변수가 다음과 같은 확률밀도함수를 가지면 라플라스 분포 \(\operatorname{Laplace} (x; \mu , \gamma )\) 를 따른다고 한다.
-
라플라스 분포는 다음과 같이 임의의 점 \(\mu\) 에서 뾰족한 점을 가진다.
