Probability
Contents
기계학습을 현실에 적용할 때 우리는 절대로 완벽한 정확도를 얻을 수는 없다. 가령, 피부 병변 이미지를 분류할 때 기계학습 모델이 신이 아닌 이상 항상 완벽한 정확도를 낼 수는 없다. 따라서 기계학습은 불확실성을 다룰 수 있어야 한다. 불확실성은 다음과 같은 2가지 종류가 있다.
인식론적 불확실성(epistemic uncertainty, 시스템적 불확실성, systematic uncertainty)
현실적으로 언제나 유한한 데이터셋만을 확보할 수밖에 없기에 발생하는 불확실성을 인식론적 불확실성이라고 한다.
-
따라서 이 불확실성은 데이터셋을 더 확보할수록 줄어든다.
-
그러나 설령 무한대의 데이터셋을 확보했다고 해도 여전히 다음과 같은 불확실성이 존재한다.
우발적 불확실성(aleatoric uncertainty, 내재적 불확실성, intrinsic uncertainty, 확률적 불확실성, stochastic uncertainty, 노이즈, noise)
우리가 세상을 오직 부분적 정보만으로 탐색할 수 있기 때문에 발생하는 불확실성을 노이즈라고 한다.
-
따라서 노이즈를 줄이려면 다른 종류의 데이터들을 모아야 한다.
-
예시
함수 \(y(x_1, x_2) = \sin (2 \pi x_1) \sin (2 \pi x_2)\) 와 같이 데이터가 생성되는 존재를 관찰한다고 하자. 이 함수에 가우스 노이즈를 포함시켜서 그래프를 그리면 다음과 같다.

노이즈가 없이 3d 그래프 계산기로 그려보면 다음과 같다.

이 그래프의 \(x_2\) 를 관찰하지 못한채 \(x_1\) 과 \(y\) 만을 부분적으로 관찰하여 \(100\)개의 데이터 포인트를 확보한 것은 다음과 같다. 이 존재를 부분적으로 관찰하는데에서 나오는 노이즈로 인하여 이 존재의 본질을 제대로 이해할 수 없다.

노이즈가 없는 그래프로 관찰하면 다음과 같다.

\(x_2\) 도 관찰할 수 있게 된 효과를 재현하기 위하여 \(x_2 = \dfrac{\pi }{2}\) 를 고정하면 다음을 얻는다. 노이즈가 상당히 줄어든 것을 체감할 수 있다.

-
예시
같은 원리로 피부 병변을 판단할 때 사진만 단독으로 있는 것보다 생체 검사 샘플이 같이 주어지면 내재적 불확실성이 많이 감소되고, 그런 데이터 양 자체가 증가하면 시스템적 불확실성이 감소된다.
이 두 불확실성을 다룰 수 있는 프레임워크가 확률론이다. 따라서 확률론은 기계학습의 중심 기초가 된다.
확률은 2가지 법칙에 의하여 지배되는데 그것이 합의 법칙, 곱의 법칙이다. 이 두 법칙을 결정이론(decision theory)과 결합하면 원칙적으로는 주어져 있는 정보를 사용하여 최적의 예측을 내릴 수 있다.
확률을 정의하는 2가지 접근이 있다.
빈도주의적 확률(frequentist probability)
빈도주의적 확률은 확률을 무한한 시행에 대한 사건의 극한의 비율로 정의한다.
-
예시
다음과 같이 한쪽으로 약간 접힌 동전을 던졌을 때 앞면이 60% 확률로 나오고 뒷면이 40% 확률로 나온다.

이 확률이란 동전 던지기를 무한히 시행한 극한을 구하여 \(\dfrac{\text{ 사건이 일어난 횟수 }}{\text{ 시행 횟수 }}\) 로써 결정된다.
베이지안 확률(Bayesian probability)
베이지안 확률은 한 개인이 주어져 있는 한정적인 정보를 기반으로 어떤 사건에 대하여 가지는 불확실성의 양으로 정의된다.
-
따라서 이를 주관적 확률, 믿을 수 있는 정도라고 할 수 있다.
-
예시
위 예시에서 우리가 이 편향적인 동전이 오목한 부분으로 떨어질 확률이 \(0.6\) 인 것을 알고 있지만, 동전의 어느쪽이 앞면이고 어느쪽이 뒷면인지 관찰 할 수 없는 상황을 가정해보자. 그렇다면 동전 던지기가 시행되고 누군가 떨어진 동전이 앞면인지 뒷면인지 질문한다면, 우리는 앞면으로 떨어질 확률을 \(0.5\) 라고 가정하고 대답할 수밖에 없다.(정보이론에 의하면 불확실성이 가장 높은 상황은 균등확률로 표현된다.) 오히려 앞면이 나올 확률을 \(0.6\) 이나 \(0.4\) 라고 생각하는 것이 더 근거없는 생각이고, 더 비합리적인 결론이다.
-
이렇게 정의되는 베이지안 확률은 빈도주의적 확률보다 더 일반적이다. 왜냐하면 베이지안 확률이 빈도주의적 확률을 특수한 경우로 포함할 수 있기 때문이다.
가령, 동전을 관찰할 수 없는 상황에서 우리는 \(0.5\) 라는 베이지안 확률을 가졌다. 하지만 동전 던지기의 결과가 계속해서 주어질수록 동전의 특정면에 대한 불확실성(주관적 믿음)을 감소시킬 수 있다.
The Rules of Probability✔
이제 확률을 지배하는 2가지 법칙을 알아보자.
A medical screening example✔
인구 중 \(1\%\) 가 암을 갖고 있다고 가정하자. 이때 암이 없는 사람이 암 검진을 받았을 때 \(3\%\) 가 암 양성 반응이 나온다고 하자. 이를 거짓 양성(false positive)라고 한다. 암이 있는 사람이 암 검진을 받았을 때 \(10\%\) 가 암 음성 반응이 나온다고 하자. 이를 거짓 음성(false negative)라고 한다.
이제 다음의 질문에 대답해보자.
- 인구 전체에 암 검진을 했을 때 누군가 양성 반응이 나올 확률은 무엇인가?
- 누군가 양성 반응이 나왔을 때, 그 사람이 실제로 암을 갖고 있을 확률은 무엇인가?
합의 법칙과 곱의 법칙으로 확률에 대한 이 질문에 대답할 수 있다.
The sum and product rules✔
확률의 법칙을 도출하기 위하여 다음 그림처럼 조금 더 일반적인 예시를 가정하자.

가령, 암의 예시에서 확률변수 \(X\) 로 암의 존재유무를 표현하고, \(Y\) 로 암 검진 결과를 표현할 수 있다.
\(X\) 는 \(i=1,\dots ,L\) 에 대한 값 \(x_i\) 중 하나를 가질 수 있고, \(Y\) 는 \(j=1,\dots ,M\) 에 대한 값 \(y_j\) 중 하나를 가질 수 있다. \(X\) 와 \(Y\) 가 취할 수 있는 모든 값을 \(N\) 이라고 하고, \(X=x_i\) 와 \(Y=y_j\) 일 때의 시행의 수를 \(n _{ij}\) 라고 하자. 또한, \(X\) 가 취한 값 \(x_i\) 의 수를 \(c_i\) 라고 하고, \(Y\) 가 취한 값 \(y_j\) 의 수를 \(r_j\) 라고 하자.
\(X\) 가 \(x_i\) 를 취하고 \(Y\) 가 \(y_j\) 를 취할 결합확률 \(P(X=x_i, Y=y_j)\) 는 다음과 같다.
이때, \(N \to \infty\) 라고 가정한다. \(Y\) 에 상관없이 \(X\) 가 \(x_i\) 값을 취할 확률은 다음과 같이 전체 수 \(N\) 분의 열 \(i\) 의 수가 된다.
\(\sum_{i}^{}c_i=N\) 이므로 다음이 성립한다.
\(i\)열의 수는 \(c_i = \sum_{j}^{}n _{ij}\) 이므로 다음이 성립하며, 이를 합의 법칙(sum rule)이라고 한다.
\(X=x_i\) 일 때 \(Y=y_j\) 일 조건부 확률은 다음과 같이 정의된다.
\(\sum_{j}^{}n _{ij}=c _{i}\) 를 사용하여 양변의 \(j\) 를 합하면 다음을 얻는다. 이는 조건부 확률이 정규화될 수 있다는 것을 보여준다.
이제 \((2.1), (2.2), (2.5)\) 에 의하여 다음이 성립하며, 이를 곱의 법칙(product rule)이라고 한다.
합의 규칙(sum rule), 곱의 규칙(product rule)
확률변수 \(X, Y\) 에 대하여 확률론의 근본 규칙은 다음과 같다.
- 합의 규칙: \(\displaystyle p(X) = \sum_{Y}^{}p(X,Y)\)
- 곱의 규칙: \(p(X,Y) = p(Y|X)p(X)\)
- \(p(X)\) 는 확률 변수 \(X\) 에 대한 분포를 뜻한다.
Bayes’ theorem✔
베이즈 정리(Bayes' theorem)
확률변수 \(X,Y\) 에 대하여 다음이 성립한다.
-
베이즈 정리는 기계학습에서 중요한 역할을 한다. 베이즈 정리가 좌항의 조건부 분포 \(p(Y|X)\) 를 어떻게 우항에서 그것의 역 조건부 분포 \(p(X|Y)\) 와 연관시키는지 주목해야 한다. 합의 법칙에 의하여 베이즈 정리의 분모는 다음과 같이 분자의 항으로 표현될 수 있으며, \(Y\) 가 어떤 값을 취하는지와 상관없는 상수이다.
\[ p(X) = \sum_{Y}^{}p(X|Y)p(Y) \]따라서 베이즈 정리의 분모를 좌항의 조건부 분포의 \(Y\) 값에 대한 합이 \(1\) 이 되도록 보장하는데에 필요한 정규화 상수로 볼 수 있다.
-
증명
\(p(X,Y) = p(Y,X)\) 이므로 곱의 규칙으로부터 바로 나온다. ■
Medical screening revisited✔
암의 존재 유뮤를 나타내는 변수를 \(C\) 로 표기하고, \(C=0\) 를 음성, \(C=1\) 를 양성으로 표기하자. 전체 인구 중 \(1\%\) 가 암을 갖고 있으므로 다음이 성립한다.
이제 암 검진 결과를 확률변수 \(T\) 로 표기하고, \(T=1\) 로 양성 결과, \(T=0\) 로 음성 결과를 표기하자. 그러면 다음이 성립한다.
이제 합의 법칙과 곱의 법칙으로 첫번째 질문에 다음과 같이 답할 수 있다. 즉, 암이 있든 없든 암 검진을 받았을 때 \(3.87\%\) 의 확률로 양성 결과를 받는다.
이제 양성 결과를 받은 사람이 진짜 양성일 확률, 즉, 두번째 질문에 대한 대답을 해보자. 이를 위하여 다음과 같이 베이즈 정리를 사용하면 된다. 즉, 양성 결과가 나왔으면 \(23\%\) 의 확률로 진짜 암에 걸린 것이다.
다음과 같이 암이 있든 없든 암 검진에서 음성 결과를 받을 확률(\(96.13\%\))과 음성 결과를 받았을 때 실제로 음성일 확률(\(99.8\%\))을 구할 수도 있다.
이 결과는 암 검진 결과에서 음성이 나와도 실제로는 \(0.2\%\) 의 확률로 암일 수 있다는 것을 의미한다.
Prior and posterior probabilities✔
베이즈 정리를 사용하여 암 검진 문제를 해결해보았다. 이 결과는 베이즈 정리의 중요한 해석을 제공한다.
- 누군가 암 검진을 하기 전에 암이 있을 가능성을 묻는다면, 우리가 사용할 수 있는 정보는 확률 \(p(C)\) 이다. 이를 검진 결과를 관찰하기 전에 사용가능한 확률이라고 하여 사전 확률(prior probability)이라고 한다.
- 검사 결과를 받는다면 베이즈 정리로 \(p(C|T)\) 를 계산하면 된다. 검사 결과 \(T\) 를 관찰한 이후에 얻는 확률이라고 하여 이를 사후 확률(posterior probability)이라고 한다.
암 검진 예시에서 사전 확률은 \(1\%\) 이다. 그러나 검진 결과가 양성이라는 것을 관찰한 이후에는 사후 확률이 \(23\%\) 가 된다. 이는 많은 사람들의 직관에 위배된다. 왜냐하면 일반적으로는 정확하다고 생각되는 암 검진에서 양성 결과가 나왔다고 하더라도 \(77\%\) 의 확률로 실제로는 암이 없다는 것이기 때문이다. 하물며 전체 인구 중에서 암이 있을 확률 \(p(C)=1\%\) 는 실제 상황에서 이보다 훨씬 더 낮게 잡힌다. 따라서 가령 \(p(C) = 0.1\%\) 로 잡고 사후확률을 계산하면 \(23\%\) 보다 훨씬 더 낮은 확률을 얻게 된다.
이로써 얻게 되는 중요한 결론은 이것이다. 아무리 검진 결과가 암의 강력한 증거를 제공한다고 하더라도, 이 결과를 반드시 베이즈 정리를 사용한 사전 확률과 결합하여 올바른 사후확률을 도출해야 한다.
Probability Densities✔
지금까지 이산적인 값의 집합에 대한 확률을 논의했지만, 연속적인 값의 집합에 대한 불확실성도 측정해야 한다. 가령, 어떤 약이 환자에게 얼마나 영향을 끼치는지 예측할 때 연속적인 값에 대한 불확실성을 측정해야 한다. 그러나 연속 집합의 특정 값에 대하여 무한대로 정확도를 높이면 확률은 \(0\) 이 된다. 가령, 구간 \([0,1]\) 에 존재하는 한 가지 정답을 맞출 확률은 \(0\) 에 수렴하기 때문이다. 따라서 연속적 변수에 대하여 확률 밀도(probability density)라는 개념이 필요하다.
확률 밀도(probability density)
\(x\) 가 구간 \((x, x+\delta x)\) 에 속할 확률이 \(\delta x \to 0\) 로 갈 때 \(p(x) \delta x\) 가 되도록 연속 변수 \(x\) 에 대한 확률 밀도 \(p(x)\) 를 정의한다. \(x\) 가 구간 \((a,b)\) 에 속할 확률은 다음과 같이 주어진다.
확률 밀도는 음이 아니어야 하고, 모든 구간에 속할 확률이 \(100\%\) 여야 하므로 다음을 만족해야 한다.
-
이 \(p(x)\) 는 가령, 다음과 같은 그래프로 그려진다.

누적 분포 함수(cumulative distribution function)
\(x\) 가 구간 \((-\infty,z)\) 에 속할 확률은 다음과 같이 정의되며, 이를 누적 분포 함수라고 한다.
- 이는 \(P'(x) = p(x)\) 를 만족하며, 위 그래프에서 그려진다.
다변량 확률 밀도
연속 변수들 \(x_1,\dots ,x_D\) 을 벡터 \(\mathbf{x}\) 라고 하자. 그러면 결합 확률 밀도 \(p(\mathbf{x}) = p(x_1,\dots ,x_D)\) 를 정의할 수 있다. 이 다변량 확률 밀도는 \(\mathbf{x}\) 가 극미한 부피 \(\delta \mathbf{x}\) 안에 포함될 확률이 \(p(\mathbf{x})\delta \mathbf{x}\) 로 주어진다. 다변량 확률 밀도는 다음을 만족해야 한다.
-
이때 이 적분은 \(\mathbf{x}\) 공간 전체에 대하여 취해진다.
-
더욱 일반적으로는, 이산 변수와 연속 변수의 조합에 대한 결합 확률 분포를 취할 수도 있다.
-
일반적으로 합과 곱의 규칙, 베이즈 정리는 확률 밀도에 적용될 수 있을 뿐만 아니라 이산 변수와 연속 변수의 조합에도 적용된다.
실 변수 \(\mathbf{x}\) 와 \(\mathbf{y}\) 에 대하여 합과 곱의 규칙, 베이즈 정리는 다음과 같다.
-
합의 규칙: \(\displaystyle p(\mathbf{x}) = \int p(\mathbf{x},\mathbf{y})\mathrm{d}\mathbf{y}\)
-
곱의 규칙: \(\displaystyle p(\mathbf{x}, \mathbf{y}) = p(\mathbf{y}|\mathbf{x})p(\mathbf{x})\)
-
베이즈 정리: \(\displaystyle p(\mathbf{y}|\mathbf{x}) = \dfrac{p(\mathbf{x}|\mathbf{y})p(\mathbf{y})}{p(\mathbf{x})}\)
-
이때 베이즈 정리의 분모는 다음과 같이 주어진다.
\[ p(\mathbf{x}) = \int p(\mathbf{x}|\mathbf{y})p(\mathbf{y})\mathrm{d}\mathbf{y} \]
Example distributions✔
복잡한 확률 모델의 빌딩 블록이 되는 중요한 확률 밀도들을 알아보자.
균등 분포(uniform distribution)
구간 \((c,d)\) 의 균등분포는 다음과 같이 정의된다.
- 가장 단순한 확률 밀도는 상수 함수 \(p(x)\) 이다. 그러나 물론 상수함수의 적분은 발산하며, 이렇게 정규화되지 않은 분포를 이상(improper) 분포라고 한다. 따라서 상수 함수는 유한한 구간에서 정의되어야 하며, 이를 균등 분포(uniform distribution)라고 한다.
지수 분포(exponential distribution)
지수 분포는 다음과 같이 정의된다.
라플라스 분포(Laplace distribution)
라플라스 분포는 정점의 위치를 \(\mu\) 에 의하여 바꿀 수 있게 해준다. 이는 다음과 같이 정의된다.
-
라플라스 분포는 지수 분포의 한 변형이다.
-
예시
균등 분포(빨간선), 지수 분포(파란선), 라플라스 분포(초록선)의 한 예시를 다음 그래프가 나타낸다. 지수 분포는 \(\lambda = 1\) 로 정의되고, 라플라스 분포는 \(\mu =1,\gamma =1\) 로 정의되었다.

디렉 델타 함수(Dirac delta function)
다음은 디렉 델타 함수이다.
경험 분포(empirical distribution)
유한한 관찰 집합 \(\mathcal{D}=\{x_1, \dots, x_N\}\) 에 대한 경험 분포는 다음과 같이 \(N\) 개의 디렉 델타 함수로 정의된다.
Expectations and covariances✔
기댓값(expectation, 가중치화된 평균, weighted average)
이산 확률 분포 \(p(x)\) 에 대한 함수 \(f(x)\) 의 기댓값은 다음과 같이 정의된다.
연속 변수에 대하여 함수의 기댓값은 다음과 같이 정의된다.
다변수 함수의 기댓값을 구할 때는 아랫첨자로 어떤 변수에 대한 평균을 구할지 명시해야 한다. 다음은 \(x\) 의 분포에 대한 이변수 함수의 평균을 뜻한다. 이는 \(y\) 에 대한 함수이다.
조건부 분포에 대한 조건부 기댓값은 다음과 같이 정의된다. 이는 \(y\) 에 대한 함수이다.
연속 변수에 대한 조건부 기댓값은 다음과 같이 정의된다.
-
기댓값은 확률에서 가장 중요한 연산 중 하나이다.
-
이산 분포든, 연속 분포든 확률 분포의 유한한 \(N\) 개의 점이 주어졌을 때 기댓값은 다음과 같이 근사된다. 이 근사는 \(N \to \infty\) 로 갈 때 정확해진다.
\[ \Bbb{E}[f] \simeq \frac{1}{N}\sum_{n=1}^{N}f(x_n) \tag{2.40} \]
분산(variance)
\(f(x)\) 의 분산은 다음과 같이 정의된다.
-
분산은 \(f(x)\) 가 평균 \(\Bbb{E}[f(x)]\) 로부터 얼마나 변하는지 알려준다.
-
분산에 대하여 다음이 성립한다.
\[ \operatorname{var}[f] = \Bbb{E}\left[ f(x)^{2} \right] - \Bbb{E}\left[ f(x) \right]^{2} \] -
변수 \(x\) 의 분산은 다음과 같다.
\[ \operatorname{var}[x] = \Bbb{E}[x ^{2}] - \Bbb{E}[x]^{2} \]
공분산(covariance)
두 확률 변수 \(x,y\) 의 공분산은 두 변수가 함께 변하는 정도를 측정하고, 다음과 같이 정의된다. 그래서 두 변수가 서로 독립이면 공분산은 \(0\) 이다.
두 벡터 \(\mathbf{x}\) 와 \(\mathbf{y}\) 의 공분산은 다음과 같은 행렬이다.
- 이때 \(\operatorname{cov}[\mathbf{x}]\equiv \operatorname{cov}[\mathbf{x},\mathbf{x}]\) 와 같이 표기한다.
Gaussian Distribution✔
[단변량] 가우스 분포([univariate] Gaussian distribution)
단변량 가우스 분포는 두 파라미터 \(\mu\)(평균), \(\sigma ^{2}\)(분산) 에 대하여 다음과 같이 정의된다.
-
가우스 분포가 다음과 같이 정규화된다는 것은 쉽게 증명 가능하다.
\[ \int_{- \infty}^{\infty}\mathcal{N}(x|\mu ,\sigma ^{2})\mathrm{d}x=1 \tag{2.51} \]
Mean and variance✔
가우스 분포의 기댓값, 즉, \(x\) 의 평균값은 다음과 같다.
이를 분포의 1차 모멘트(first-order moment)라고 한다.
다음과 같이 2차 모멘트를 정의한다.
\(x\) 의 분산은 다음과 같다.
Likelihood function✔
\(1\)차원 변수(스칼라) \(x\) 의 \(N\) 번의 관찰을 나타내는 행 벡터 \(\mathsf{x} = (x_1, \dots, x_N)\) 로 표현되는 데이터셋을 잡자. 이는 \(1\) 번의 관찰로 얻어지는 \(D\)-차원 벡터 변수를 나타내는 열벡터 \(\mathbf{x}=(x_1, \dots, x_D)^{\top}\) 와 구분된다. 이때 각 관찰들이 평균 \(\mu\) 와 분산 \(\sigma ^{2}\) 이 알려지지 않은 가우스 분포로부터 독립적으로 추출되었다고 가정하자. 우리는 이 파라미터들을 데이터셋으로부터 판정하길 원한다. 주어진 유한한 관찰들로 분포를 추정하는 것을 밀도 추정이라고 한다.
밀도 추정(density estimation)
주어진 유한한 관찰들로 데이터를 생성하는 분포를 추정하는 것을 밀도 추정이라고 한다.
그러나 밀도 추정은 원론적으로는 잘못된 것이다. 왜냐하면 관찰된 유한한 데이터셋을 생성할 수 있는 확률 분포는 무한히 많기 때문이다. 실제로, 데이터 포인트 \(\mathbf{x}_1,\dots ,\mathbf{x}_N\) 에서 \(0\) 이 아닌 모든 분포 \(p(\mathbf{x})\) 가 후보가 된다. 그러나 잘 정의된 해를 도출해낼 수 있도록 가우스 분포 공간으로 공간을 제한한다.(가우스 분포 공간을 선택하는 이유는 연속 변수의 최대 엔트로피 섹션에서 나온다.)
가우스 분포에 대한 우도 함수(Gaussian likelihood function)
\(1\)차원 변수(스칼라) \(x\) 의 \(N\) 번의 관찰을 나타내는 행 벡터 \(\mathsf{x} = (x_1, \dots, x_N)\) 로 표현되는 데이터셋을 잡자. 집합 \(\mathsf{x}\) 의 데이터가 i.i.d 하게 가우스 분포로부터 관찰되었다고 가정하면, 이 데이터들 전체가 관찰될 확률은 어떤 \(\mu\) 와 \(\sigma ^{2}\) 에 대하여 다음과 같다. 이는 \(\mu\) 와 \(\sigma ^{2}\) 에 대한 함수이고, 가우스 분포에 대한 우도 함수라고 부른다.
-
우도 함수를 다음 그래프(빨간선)로 나타내어질 수 있다. 회색점들이 데이터셋 \(\{x_n\}\) 을 나타내고, 파란점들이 그에 대응되는 \(p(x)\) 값을 나타낸다.

Maximum Likelihood Estimation✔
최대우도법(maximum likelihood)
관찰된 데이터 셋을 사용하여 확률 분포의 파라미터를 판정하는 보통의 접근법은 최대 우도법이다. 최대 우도법은 우도 함수를 최대화하는 파라미터를 찾는다.
-
최대우도법이 이상해보일 수도 있다. 왜냐하면 주어진 데이터에 대하여 파라미터의 확률을 최대화하는 것이 더 자연스럽지, 주어진 파라미터에 대하여 데이터의 확률을 높이는 것은 이상하기 때문이다. 사실, 이 두 접근은 서로 연관되어 있다.
-
예시
어떤 절차를 통하여 다음과 같은 데이터 포인트 \(10\)개를 관찰했다고 하자. 가령, 이 데이터 포인트들이 학생들에게 어떤 질문을 했을 때 대답하는데 걸린 초라고 하자.
이 데이터를 생성한 확률 분포를 추정해내는 것이 목표이다. 이때, 데이터를 생성할 후보가 되는 분포를 가우스 분포 공간으로 제한했으므로 이 데이터를 생성할 가능성이 가장 높은 가우스 분포를 찾는 것이 목표가 된다. 가우스 분포는 2가지 파라미터 \(\mu\) 와 \(\sigma\) 만을 갖는다. 가령, 다음과 같은 4가지 가우스 분포 중에서 이 데이터를 생성했을 가능성이 가장 높은 가우스 분포를 선택해야 한다고 하자.
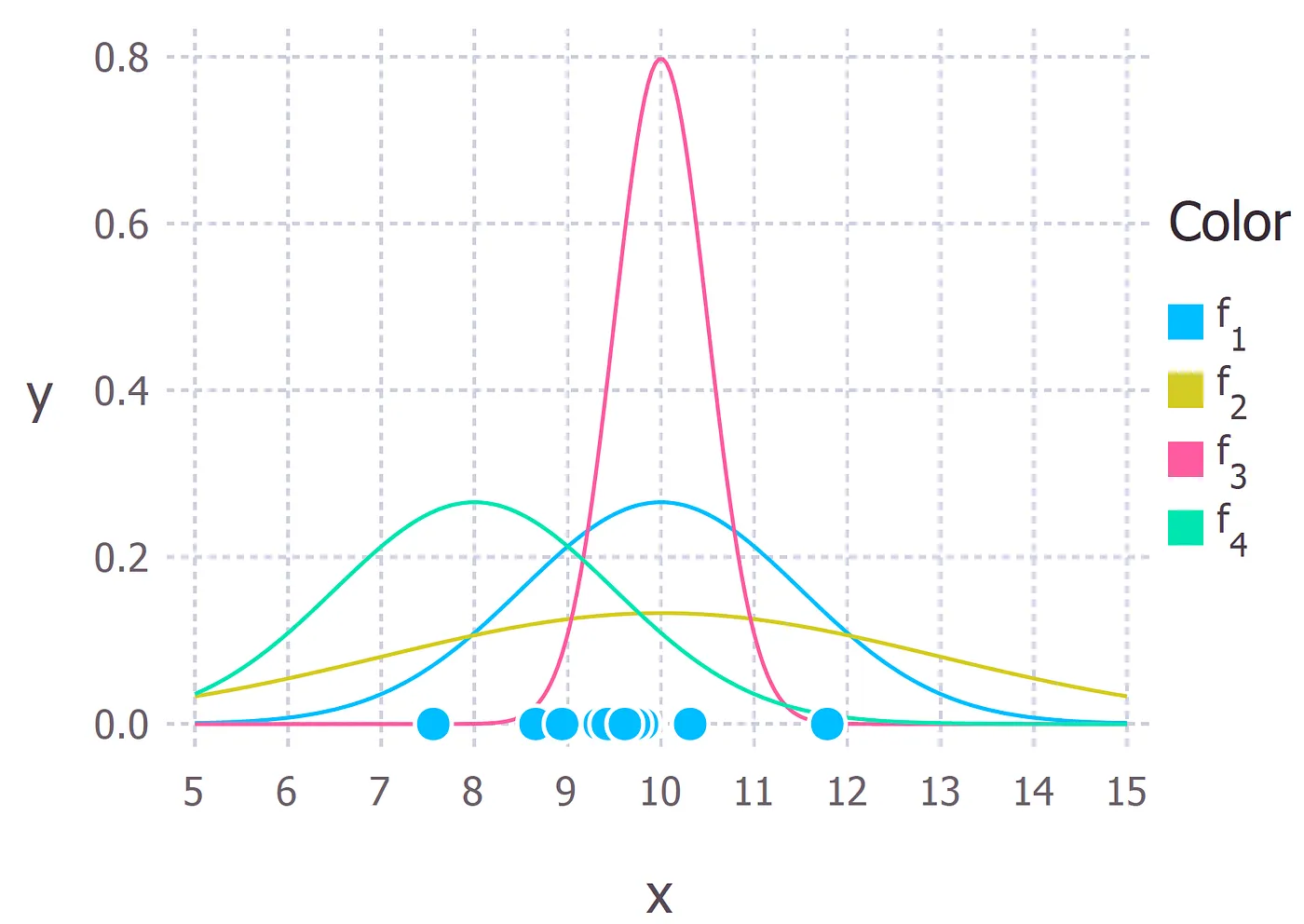
함수 \(f_1\) 은 \(\mathcal{N}(x|10, 2.25)\) 이다. 즉, \(f_1 \sim \mathcal{N}(x|10, 2.25)\) 이고, 나머지는 \(f_2 \sim \mathcal{N}(x|10, 9), f_3 \sim \mathcal{N}(x|10, 0.25), f_4 \sim \mathcal{N}(x|8, 2.25)\) 이다. 정답을 먼저 공개하자면 데이터를 생성한 진짜 분포는 \(f_1 \sim \mathcal{N}(x|10, 2.25)\) 이다.
이제, 최대 우도 추정을 통하여 어떤 가우스 분포가 데이터를 생성했을 확률이 가장 높은지 계산해야 한다. 편의상, 3가지 데이터 포인트 \(9,9.5,11\) 만을 가정하고, 이 데이터를 생성했을 가능성이 가장 높은 가우스 분포를 추정해보자.
이 3가지 데이터를 관찰할 확률은 각 데이터 포인트를 관찰했을 결합 확률 분포로 주어진다. 이를 위해서는 복잡한 조건부 확률을 계산해야 하므로 각 데이터가 i.i.d 하다고 가정하는 것이 보통이다. 그러면 3가지 데이터가 같은 분포로부터 독립적으로 추출되었고, 그것이 가우스 분포라고 가정했기 때문에 한 데이터 포인트 \(x=9\) 가 관찰될 확률은 다음과 같다.
\[ P(9|\mu ,\sigma ^{2}) = \frac{1}{\sigma \sqrt[]{2 \pi }}\exp \left( - \dfrac{(9 - \mu )^{2}}{2 \sigma ^{2}} \right) \]그러면 3가지 데이터를 관찰할 결합 분포는 이들이 독립이므로 단순히 확률을 곱함으로써 얻을 수 있다. 이것이 주어진 데이터셋의 가우스 우도 함수이다.
\[ \begin{equation}\begin{split} P(9, 9.5, 11|\mu , \sigma ^{2}) &= \frac{1}{\sigma \sqrt[]{2 \pi }}\exp \left( - \dfrac{(9 - \mu )^{2}}{2 \sigma ^{2}} \right) \\ & \quad \qquad \times \frac{1}{\sigma \sqrt[]{2 \pi }}\exp \left( - \dfrac{(9.5 - \mu )^{2}}{2 \sigma ^{2}} \right) \\ & \quad \qquad \times \frac{1}{\sigma \sqrt[]{2 \pi }}\exp \left( - \dfrac{(11 - \mu )^{2}}{2 \sigma ^{2}} \right) \\ \end{split}\end{equation} \tag*{} \]그러면 우리가 할 일은 이 확률을 가장 높여주는 \(\mu\) 와 \(\sigma\) 를 추정하는 것으로 귀결되는 것이다. 함수의 극점(최댓값)을 찾는 방법은 미분을 취하고 \(0\) 에 대한 해를 찾는 것이다. 그러나 위 형태의 함수를 곧바로 미분하는 것은 어렵고, 컴퓨터가 효율적으로 계산할 수치로 스케일링되지도 않는다. 따라서 로그를 취한 다음 미분을 계산하는 것이 좋다.
\((2.55)\) 의 우도 함수를 최대화함으로써 가우스 분포의 파라미터 \(\mu\) 와 \(\sigma ^{2}\) 를 판정해보자. 실제 상황에서는 우도 함수의 로그를 최대화하는 것이 더 편하다. 로그는 그것의 인자의 함수를 단조 증가시키기 때문에 함수의 로그를 최대화하는 것은 함수를 최대화하는 것과 같다. 로그를 취하면 후속되는 수학적 분석이 단순해질 뿐만 아니라 수치적으로도 작은 분포들의 큰 수들의 곱이 컴퓨터에서 계산하기 쉬운 정밀도로 언더플로우(underflow)된다.
로그 우도 함수(log likelihood function)
로그 우도 함수는 \((2.49)\) 와 \((2.55)\) 에 의하여 다음과 같다.
-
예시
위 예시에서 얻은 우도 함수에 로그를 취하면 다음을 얻는다.
\[ \begin{equation}\begin{split} \ln (P(x|\mu ,\sigma ^{2}))& = \ln \left( \frac{1}{\sigma \sqrt[]{2 \pi }} \right) - \frac{(9 - \mu )^{2}}{2 \sigma ^{2}} \\ & \qquad + \ln \left( \dfrac{1}{\sigma \sqrt[]{2 \pi }} \right) - \dfrac{(9.5 - \mu )^{2}}{2 \sigma ^{2}}\\ & \qquad + \ln \left( \dfrac{1}{\sigma \sqrt[]{2 \pi }} \right) - \dfrac{(11 - \mu )^{2}}{2 \sigma ^{2}}\\ & = - 3 \ln (\sigma )- \frac{3}{2}\ln (2 \pi )\\ & \qquad - \frac{1}{2 \sigma ^{2}}\left[ (9-\mu )^{2}+(9.5-\mu )^{2}+(11-\mu )^{2} \right] \\ \end{split}\end{equation} \tag*{} \]
최대 우도해(maximum likelihood solution)
로그 우도 함수를 \(\mu\) 에 대하여 최대화하면 다음과 같은 최대 우도해를 얻는다.
\((2.56)\) 을 \(\sigma ^{2}\) 에 대하여 최대화하면 다음과 같은 분산에 대한 최대 우도해를 얻는다.
-
\(\mu\) 에 대한 최대 우도해는 표본 평균(sample mean), 즉, 관찰된 값들 \(\{x_n\}\) 의 평균이다.
-
분산에 대한 최대우도해는 표본 평균 \(\mu _{\text{ML}}\) 에 대하여 측정되는 표본 분산(sample variance)이다.
-
예시
위 예시에서 얻은 로그 우도를 \(\mu\) 로 편미분하면 다음을 얻는다.
\[ \dfrac{\partial \ln (P(x|\mu ,\sigma ^{2}))}{\partial \mu } = \frac{1}{\sigma ^{2}}[9 + 9.5 + 11 - 3 \mu ] \]이 식을 \(0\) 으로 잡으면 다음을 얻는다. 이 결과는 본 정리가 말하는 로그 우도 함수의 \(\mu\) 에 대한 최대 우도해 \(\mu _{\text{ML}}\) 와 같다.
\[ \mu _{\text{ML}} = \frac{9+9.5+11}{3}=9.833 \]\(\sigma ^{2}\) 에 대한 최대 우도 해 \(\sigma ^{2}_{\text{ML}}\) 도 방금 구한 \(\mu _{\text{ML}}\) 을 사용하여 같은 방식으로 구할 수 있다.
우리는 \((2.56)\) 을 \(\mu\) 와 \(\sigma ^{2}\) 에 대하여 결합 최대화(joint maximization)하려 한다.
Limitation of maximum likelihood✔
최대우도법은 딥러닝에서 널리 사용되고, 기계학습 알고리즘의 근본을 이룬다. 그러나 한계도 존재한다.
먼저, 로그 우도 함수의 미분이 항상 해석적으로 풀리지 않는다. 따라서 기댓값-최대화 알고리즘(expectation-maximization algorithm)같은 수치적 해를 통하여 파라미터를 추정해야 한다.
또한, 다음과 같이 최대 우도의 분산에 대한 해의 기댓값이 편향되는 한계가 존재한다.
최대 우도의 편향(bias of maximum likelihood)
최대우도해 \(\mu _{\text{ML}}\) 과 \(\sigma ^{2}_{\text{ML}}\) 은 데이터 집합의 값 \(x_1, \dots, x_N\) 에 대한 함수이다. 이 값들이 \(\mu\) 와 \(\sigma ^{2}\) 에 대한 가우스 분포로부터 독립적으로 생성되었다고 하자. \(\mu _{\text{ML}}\) 과 \(\sigma ^{2}_{\text{ML}}\) 의 데이터 집합 값들에 대한 기댓값은 다음과 같다.
이로써 알 수 있는 것은 주어진 크기의 데이터셋에 대한 평균, 즉, 표본 평균의 평균은 원래 평균과 같다는 것이다. 그러나 분산의 최대우도해는 \(\dfrac{N-1}{N}\) 라는 항에 의하여 원래 분산보다 과소평가된다.
-
이렇게 시스템적으로 추정이 원래 값과 달라지는 현상을 편향(bias)라고 한다. 다음 그래프는 이 현상을 직관적으로 보여준다.

빨간색 그래프가 데이터를 생성하는 원래의 가우스 분포를 나타낸다. 3가지 파란색 그래프는 각각 2가지 초록점에 의하여 구성된 3가지 데이터 셋에 피팅되어서 얻어진 가우스 분포를 보여준다. 이때 3가지 데이터셋의 평균의 평균은 \(\mu\) 로 올바르게 환원되지만, 분산은 시스템적으로 과소평가된다. 왜냐하면 원래의 분산이 아닌 표본 분산에 대하여 측정되기 때문이다.
-
편향이 발생하는 이유는 데이터에 맞춰서 조정된 평균의 최대 우도 추정을 기준으로 분산이 측정되기 때문이다. 그 대신 원래의 평균 \(\mu\) 를 사용하여 다음과 같은 분산의 추정기를 사용할 수 있다.
\[ \hat{\sigma }^{2} = \frac{1}{N}\sum_{n=1}^{N}(x_n - \mu )^{2} \tag{2.61} \]그러면 다음과 같이 편향되지 않은 분산을 얻을 수 있다.
\[ \Bbb{E}[\hat{\sigma }^{2}] = \sigma ^{2} \]그러나 물론 원래의 평균에 접근할 수 없고 오직 관찰된 데이터 값에만 접근할 수 있다. 따라서 \((2.60)\) 에 의하여 다음과 같이 분산에 대한 추정을 구하면 편향되지 않은 분산을 구할 수 있다. 이 조정법을 표본 분산에서 이미 살펴보았었다.
\[ \tilde{\sigma }^{2} = \frac{N}{N-1}\sigma ^{2}_{\text{ML}} = \frac{1}{N-1}\sum_{n=1}^{N}(x_n - \mu _{\text{ML}})^{2} \tag{2.63} \]그러나 신경망 같은 복잡한 모델에서 최대 우도의 편향을 바로잡는 것은 어려운 문제이다.
-
하지만 최대우도해의 편향은 데이터 포인트의 수 \(N\) 이 증가할수록 중요하지 않게 된다. 즉, \(N \to \infty\) 로 갈 때 편향에 대한 최대우도해는 데이터를 생성하는 분포의 편향과 같아진다. 그러나 최대 우도와 연관된 편향 문제가 치명적인 많은 파라미터를 갖는 복잡한 모델들을 다뤄야 할 때도 많다. 최대우도의 편향 문제는 과적합(over-fitting)과 밀접하게 연결되어 있다.
Linear regression example✔
회귀 문제의 목적은 \(N\) 개의 입력 값 \(\mathsf{x}=(x_1, \dots, x_N)\) 와 그에 대응되는 타겟값 \(\mathsf{t}=(t_1, \dots, t_N)\) 으로 이루어진 훈련 데이터 집합을 사용하여 입력 변수 \(x\) 의 주어진 어떤 값에 대하여 타겟 변수 \(t\) 에 대한 예측을 하는 것이다.
회귀 문제의 목적
훈련 데이터를 사용하여 입력에 대한 타겟을 예측하는 것이다.
우리는 확률 분포를 사용하여 타겟 변수의 값에 대한 불확실성을 표현할 수 있다. 이를 위하여 주어진 \(x\) 의 값에 대응되는 \(t\) 의 값이 다음을 만족하는 가우스 분포와 같다고 가정한다.(알려지지 않은 분포를 가우스 분포를 가정하는 이유는 연속 변수의 엔트로피를 다룰 때 나온다.)
- \(\mathbf{w}\) 가 계수인 \((1.1)\) 의 다항식 \(y(x, \mathbf{w})\) 의 값이 평균이다.
- \(\sigma ^{2}\) 가 분산이다.
그러면 다음과 같은 가우스 분포를 얻는다.
이 가우스 분포는 아래의 파란 곡선으로 그려진다.

파란 곡선은 주어진 \(x_0\) 에 대한 \(t\) 의 가우스 조건 분포를 나타낸다. 파란 점들은 데이터 포인트들이고, 빨간 곡선은 추정되는 \(y\) 값에 의하여 그려진 그래프, 즉, 데이터를 생성했다고 추정되는 정답을 그린 것이다.
이제 훈련 데이터 \(\{\mathsf{x},\mathsf{t}\}\) 를 사용하여 알려지지 않은 파라미터 \(\mathbf{w}\) 와 \(\sigma ^{2}\) 를 최대 우도를 사용하여 판정해야 한다. 데이터들이 \((2.64)\) 로부터 독립적으로 추출되었다면 우도 함수를 다음과 같이 정의할 수 있다.
이 우도 함수도 마찬가지로 로그를 취하여 최대화시키는 것이 기술적으로 편하다. 그러면 다음을 얻는다.
먼저 다항식의 계수 \(\mathbf{w}\) 에 대하여 로그 우도 \((2.66)\) 을 최대화한 최대우도해 \(\mathbf{w}_{\text{ML}}\) 를 구하자. \((2.66)\) 의 마지막 두 항은 \(\mathbf{w}\) 에 의존하지 않으므로 제거할 수 있고, 로그 우도 함수를 상수 계수로 스케일링해도 최댓값의 위치는 바뀌지 않으므로 \(1/2 \sigma ^{2}\) 를 \(1/2\) 로 바꿔도 되며, 로그 우도를 최대화하는 대신 음의 로그 우도를 최소화해도 된다. 그러면 최종적으로 다음과 같은 오차제곱합 함수를 얻는다.
오차제곱합(SSE, sum-of-squares error, 계수 \(\mathbf{w}\) 에 대한 최대우도해)
-
따라서 이 SSE 에러 함수를 최소화하는 것은 데이터를 생성하는 분포가 가우스 노이즈 분포임을 가정했을 때 우도를 \(\mathbf{w}\) 에 대하여 최대화하는 것의 귀결이다.
그래서 기계학습에서 그냥 무식하게 출력값에서 정답 레이블의 차잇값을 제곱한 것을 합하여 \(2\) 로 나눈 것을 에러 함수로 사용하고 있다고 생각하면 오산이다. 이는 베이지안 접근법과 연결되어 있기 때문이다. 이로써 앞서서 말했던 최대우도법이 이상해 보인다는 의문점이 해결된다. 즉, 주어진 데이터에 대하여 파라미터 확률을 최대화하는 것과 주어진 파라미터에 대하여 데이터의 확률을 높이는 것은 서로 연관되어 있다.
분산에 대한 최대우도해
분산 파라미터 \(\sigma ^{2}\) 를 판정하기 위하여 최대 우도를 사용할 수 있다. \((2.66)\) 을 \(\sigma ^{2}\) 에 대하여 최대화하는 것은 다음 식을 제공해준다.
- 그러므로 먼저 평균을 결정하는 파라미터 벡터인 \(\mathbf{w}\) 에 대한 최대우도해 \(\mathbf{w}_{\text{ML}}\) 를 먼저 계산해야 하고, 그 다음에 이것을 사용하여 분산 \(\sigma ^{2}_{\text{ML}}\) 을 찾아야 한다.
\(\mathbf{w}\) 와 \(\sigma ^{2}\) 가 판정되면, 우리는 비로소 새로운 \(x\) 값이 주어졌을 때 그것의 타겟(정답 레이블)을 예측을 할 수 있다. 우리가 얻은 것은 확률 모델이므로 이들은 단순한 점 추정이 아니라 \(t\) 에 대한 확률 분포를 제공해주는 예측 분포(predictive distribution)로 표현되고, 이는 다음과 같이 \((2.64)\) 에 최대 우도 파라미터를 치환하여 얻어진다.
Transformation of Densities✔
확률 분포가 변수의 비선형 변화에 대하여 어떻게 변환되는지 살펴보자. 이 성질은 normalizing flow(NF)라는 생성형 모델의 모임에서 중요한 역할을 한다.
일변수 함수의 변수의 변화
단일 변수 \(x\) 와 변수의 변화 \(x = g(y)\) 에 대하여 함수 \(f(x)\) 는 새로운 함수 \(\tilde{f}(y)\) 가 되고, 이는 다음과 같이 정의된다.
-
예시
\(f(x) = x ^{2} + \sin x + 5\) 에서 \(x = y ^{2} + 1\) 의 변수의 변화가 이루어지면 다음과 같은 함수를 얻는다.
\[ \tilde{f}(y) = f(g(y)) = (y ^{2} + 1) ^{2} + \sin (y ^{2} + 1) + 5 \]
확률 밀도의 변수의 변화
확률 밀도 \(p_x(x)\) 에서 변수의 변화 \(x = g(y)\) 가 이루어지면 새로운 변수 \(y\) 에 대한 확률 밀도 \(p_y(y) = p_x(g(y))\) 를 얻는다.
이 변환에 의하여 작은 값 \(\delta x\) 에 대한 구간 \((x,x+\delta x)\) 에 속하는 데이터도 \(x = g(y)\) 와 \(p_x(x)\delta x \simeq p_y(y)\delta y\) 인 구간 \((y,y+\delta y)\) 안으로 변환된다. 따라서 극한 \(\delta x \to 0\) 을 취하면 다음을 얻는다.
-
절댓값을 취하는 이유는 미분 \(\mathrm{d}y/\mathrm{d}x\) 가 음수가 될 수 있는데 비해 밀도는 항상 양수인 길이의 비율에 의하여 스케일링되기 때문이다.
-
이 변환 밀도 절차는 강력하다. 임의의 밀도 \(p(y)\) 를 \(0 \leq f'(x) < \infty\) 인 단조 함수 \(f(x)\) 에 대한 비선형 변수 변화 \(y = f(x)\) 에 의하여 모든 곳에서 \(0\) 이 아닌 고정된 밀도 \(q(x)\) 로부터 얻을 수 있다.
변환 성질 \((2.71)\) 의 결과 중 하나는 확률 밀도의 최댓값의 개념이 변수의 선택에 의존한다는 것이다. \(f(x)\) 가 \(\hat{x}\) 에서 모드(최빈값, mode, 확률 밀도에서는 최댓값)를 가져서 \(f'(\hat{x}) = 0\) 라고 하자. 대응되는 모드 \(\tilde{f}(y)\) 는 \((2.70)\) 의 양변을 \(y\) 에 대하여 미분하여 얻어진다. 즉, 다음이 성립한다.
모드에서 \(g'(\hat{y}) \neq 0\) 이면, \(f'(g(\hat{y})) = 0\) 이다. 그런데 \(f'(\hat{x}) = 0\) 이므로 \(\hat{x} = g(\hat{y})\) 이다. 따라서 \(x\) 에 대한 모드를 찾는 것은 변수를 \(y\) 로 변환시키고 \(y\) 에 대한 모드를 찾아서 그것을 다시 \(x\) 로 재변환시키는 것이다. \(y\) 에 대한 모드 \(\hat{y}\) 를 찾았다면 \(x\) 에 대한 모드 \(\hat{x}(= g(\hat{y}))\) 를 바로 얻을 수 있기 때문이다.
변수의 변화 \(x=g(y)\) 가 이루어질 때 확률 밀도 \(p_x(x)\) 의 동작을 살펴본다. 새로운 변수에 대한 밀도는 \(p_y(y)\) 이고 이는 \((2.71)\) 에 의하여 주어진다. \((2.71)\) 의 절댓값을 다루기 위하여 \(s \in \{-1,1\}\) 에 대하여 \(g'(y) = s|g'(y)|\) 라고 쓰자. 그러면 \((2.71)\) 은 \(1/s=s\) 이므로 다음과 같다.
양변을 \(y\) 에 대하여 미분하면 다음을 얻는다.
이때, 우변의 2번째 항 때문에 \(\hat{x} = g(\hat{y})\) 은 더 이상 성립하지 않는다. \(p_x(x)\) 를 최대화하여 얻은 \(x\) 의 값은 \(p_y(y)\) 를 \(y\) 에 대하여 최대화하는 값을 \(x\) 로 재변환한 값이 아니다. 그러나 선형 변환에 대해서는 \((2.73)\) 의 우변의 2번째 항이 사라지므로 \(\hat{x} = g(\hat{y})\) 가 성립하는 것이다.
그러나 다음 예시처럼 비선형 변환에서는 2번째 항이 사라지지 않으므로 \(\hat{x} \neq g(\hat{y})\) 이다.
-
예시
다음 그래프에서 빨간 곡선으로 나타나는 \(x\) 에 대한 가우스 분포 \(p_x(x)\) 를 잡자.

이 분포로부터 \(N=50000\) 의 표본을 추출하고 그 값들의 히스토그램을 그렸다. 이 히스토그램은 분포 \(p_x(x)\) 와 같이 그려진다.
이제 \(x\) 를 다음과 같이 \(y\) 로 비선형 변화하자.
\[ x = g(y) = \ln (y) - \ln (1-y) + 5 \tag{2.74} \]이것의 역함수는 다음과 같다.
\[ y = g ^{-1}(x) = \frac{1}{1+\exp (-x+5)} \tag{2.75} \]이는 로지스틱 시그모이드 함수(logistic sigmoid function)로써 위 그림의 파란 곡선으로 나타난다.
\(p_x(x)\) 를 단순히 \(x\) 의 함수로써 변환하면 위 그림의 초록색 곡선으로 나타나는 \(p_x(g(y))\) 를 얻고, 밀도 \(p_x(x)\) 의 모드가 시그모이드 함수를 통하여 이 곡선의 모드로 변환된다. 그러나 \(y\) 에 대한 밀도는 \((2.71)\) 을 따라 변환되고, 이는 보라색 곡선으로 나타난다.
실제로 \(x\) 의 값 \(50000\) 개를 추출하고 \((2.75)\) 에 의하여 그에 대응되는 \(y\) 의 값을 구하면 보라색 곡선에 대응되는 히스토그램을 얻는다.
Multivariate distributions✔
다변수 밀도의 변수의 변화
\((2.71)\) 의 결과는 다변수 밀도에로 확장된다. \(D\)-차원 변수 \(\mathbf{x}=(x_1, \dots, x_D)^{\top}\) 에 대한 밀도 \(p(\mathbf{x})\) 를 잡고, 변수 \(\mathbf{x}\) 를 \(\mathbf{x}=\mathbf{g}(\mathbf{y})\) 에 대한 새로운 변수 \(\mathbf{y}= (y_1, \dots, y_D)^{\top}\) 로 변환해보자.
여기에서는 \(\mathbf{x}\) 와 \(\mathbf{y}\) 가 같은 차원을 갖는다고 한정하자. 변환된 밀도는 \((2.71)\) 의 일반화된 다음과 같은 형태를 갖는다.
-
\(\mathbf{J}\) 는 편미분 \(J _{ij} = \dfrac{\partial g_i}{\partial y_j}\) 의 성분을 갖는 다음과 같은 야코비 행렬이다.
\[ \mathbf{J}=\begin{bmatrix} \dfrac{\partial g_1}{\partial y_1} & \dots & \dfrac{\partial g_1}{\partial y_D}\\ \vdots & \ddots & \vdots \\ \dfrac{\partial g_D}{\partial y_1} & \dots & \dfrac{\partial g_D}{\partial y_D}\\ \end{bmatrix} \tag{2.77} \]직관적으로 변수의 변화를 점 \(\mathbf{x}\) 주위의 극소 영역 \(\Delta \mathbf{x}\) 를 점 \(\mathbf{y}=\mathbf{g}(\mathbf{x})\) 주위의 영역 \(\Delta \mathbf{y}\) 로 변환함으로써 공간의 어떤 영역을 확장하고 다른 영역은 축소하는 것으로 볼 수 있다. 야코비의 판정식의 행렬식(determinant)의 절댓값은 이러한 크기의 비율을 나타내고, 이는 적분에서 변화를 변화할 때 나타나는 인수와 같다.
-
예시
2차원 가우스 분포에서의 변수의 변화를 살펴보자. \(\mathbf{x}\) 의 \(\mathbf{y}\) 로의 변화가 다음과 같이 주어졌다고 하자.
\[ y_1 = x_1 + \tanh (5x_1) \tag{2.78} \]\[ y_2 = x_2 + \tanh (5x_2) + \frac{x_1 ^{3}}{3} \tag{2.79} \]이 변화를 다음 그림이 보여준다.

Information Theory✔
확률론은 정보 이론의 기초가 되어준다. 정보 이론은 데이터셋의 정보량을 측정해줘서 기계학습에서 중요한 역할을 한다.
Entropy✔
이산 확률 변수 \(x\) 를 잡자. 이 변수의 특정 값을 관찰했을 때 얻게 되는 정보량이 얼마나 큰가? 세상에는 많은 정보들이 존재하지만, 그 정보들의 양을 다음과 같은 기준으로 판정할 수 있다.
- 정보량은 자주 일어나는 사건일수록 적고, 희긔하고 극단적인 사건일수록 많으며, 반드시 일어나는 사건이면 정보량이 없다. 따라서 정보량을 "놀람의 정도" 라고 볼 수 있다. 그러므로 정보의 측정은 확률 분포 \(p(x)\) 에 의존되고, 따라서 정보를 표현하는 확률 \(p(x)\) 의 단조 함수인 정보량 \(h(x)\) 를 찾아야 한다.
- 서로 관련없는 두 사건 \(x\) 와 \(y\) 의 정보량은 서로 합해져야 한다. 즉, \(h(x,y) = h(x) + h(y)\) 가 되어야 한다. 서로 독립인 두 사건은 \(p(x, y) = p(x)p(y)\) 를 만족한다. 따라서 정보량을 측정하는 함수는 곱을 합으로 변환하는 성질을 가져야 한다.
이 조건을 만족하는 함수 \(h(x)\) 는 \(p(x)\) 의 로그가 되어야 한다.
이산 확률 변수의 정보량
이산 확률 변수 \(x\) 와 분포 \(p(x)\) 에 대한 정보량 \(h(x)\) 는 다음과 같이 정의된다.
-
로그의 밑으로 \(2\) 를 택한 것은 임의적이다. 정보 이론의 관례를 따라 밑을 \(2\) 로 잡은 것이다. 밑이 \(2\) 인 정보량 \(h(x)\) 의 단위를 비트(bit, binary digits)라고 한다.
-
정보량 함수는 사건이 일어날 확률에 따라 다음과 같이 그려진다. 일어날 확률이 \(1 = 100\%\) 인 사건의 정보량은 \(0\) 이 되고, 일어날 확률이 \(0\%\) 에 가까운 사건일수록 정보량이 무한대를 향하여 증가한다.

이산확률변수의 엔트로피(entropy)
확률변수의 값에 따른 평균 정보량은 다음과 같고, 이를 확률 변수 \(x\) 의 엔트로피(entropy)라고 한다.
-
예시
균등 확률로 \(8\) 가지 상태 \(\{a,b,c,d,e,f,g,h\}\) 를 가질 수 있는 이산 확률 변수 \(x\) 를 잡자. 이 정보를 전달하기 위해서는 다음과 같이 \(3\) 비트 정보량이 필요하다.
실제로 이 결과는 이 변수의 엔트로피를 통해서도 알 수 있다.
\[ \mathrm{H}[x] = -8 \cdot \frac{1}{8}\log_{2} \frac{1}{8} = 3 \text{ bits } \]그런데 확률 변수가 \(8\) 가지 상태를 균등 확률로 가지는 것이 아니라 각각 다음과 같은 확률로 상태를 취하게 된다고 해보자.
\[\left( \frac{1}{2}, \frac{1}{4}, \frac{1}{8}, \frac{1}{16}, \frac{1}{64}, \frac{1}{64},\frac{1}{64},\frac{1}{64}\right)\]그러면 엔트로피는 다음과 같다.
\[ \begin{equation}\begin{split} \mathrm{H}[x] & = - \frac{1}{2}\log_{2} \frac{1}{2} - \frac{1}{4}\log_{2} \frac{1}{4} - \frac{1}{8}\log_{2} \frac{1}{8} \\ & \qquad - \frac{1}{16}\log_{2} \frac{1}{16} - \frac{4}{64}\log_{2} \frac{1}{64} \\ & = 2 \text{ bits } \\ \end{split}\end{equation} \tag*{} \]이처럼 균등 분포에서 엔트로피, 즉, 정보의 불확실성(정보량)이 높다는 것을 알 수 있다. 이 비균등 확률변수를 전달하려면 어떻게 해야 할까? 물론 확률변수도 균등 분포의 확률변수처럼 \(3 \text{ bits}\) 로 일어난 사건을 전달할 수 있다. 그러나 정보량이 낮은 것에 대한 이득을 취하기 위하여 일어날 확률이 높은 사건에 짧은 코드를 사용하고, 일어날 확률이 낮은 사건에 긴 코드를 사용할 수 있다. 즉, 각 사건에 대하여 다음과 같은 코드를 사용하는 것이다.
이렇게 하면 코드의 평균 길이가 다음과 같이 \(2 \text{ bits}\) 가 된다.
\[ \frac{1}{2} \cdot 1 + \frac{1}{4}\cdot 2 + \frac{1}{8}\cdot 3 + \frac{1}{16}\cdot 4 + 4 \cdot \frac{1}{64}\cdot 6 = 2 \text{ bits} \]그러면 이 코드 체계보다 더 효율적인 코드 체계를 만들 수 있을까? 이 사건의 정보량이 \(2 \text{ bits}\) 이므로 이보다 더 효율적인 코드 체계는 존재하지 않는다. \(2 \text{ bits}\) 보다 낮은 정보량을 지닌 코드 체계를 만들려면 이 사건의 정보를 훼손해야 한다.
이제 정보량의 로그의 밑으로써 \(e\) 를 택한다. 그렇게 해야만 기계학습의 맥락에서 더 편하기 때문이다. 이 정보량은 네트(nats)라고 불린다.
Physics perspective✔
엔트로피의 개념은 정보량의 평균을 나타내기 이전에 이미 평형 열역학(equilibrium thermodynamics)에서 사용되던 개념이다. 물리학적인 엔트로피를 이해해보자.
중복도(multiplicity)
\(i\)번째 통에 \(n_i\) 개의 물체가 있도록 \(N\) 개의 동등한 물체를 통에 나누는 상황을 생각하자. 이때 물체를 통 속에 할당하는 경우의 수는 다음과 같다. 이를 중복도라고 한다.
-
증명
첫번째 물체를 선택하는 경우의 수는 \(N\) 이고, 두번째 물체를 선택하는 경우의 수는 \(N-1\) 이다. 결국 모든 물체를 통에 넣는 경우의 수는 \(N!\) 이다. 그러나 통 안에 있는 물체들의 순서는 고려하지 않는다. 즉, \(i\)번째 통에 있는 물체를 배열하는 경우의 수는 \(n_i!\) 이므로 \(N\) 개의 물체를 통에 할당하는 경우의 수는 다음과 같다.
\[ W = \dfrac{N!}{\prod_{i}^{}n_i !} \tag*{■}\]
중복도에 대한 엔트로피는 확률의 정의 \(p_i = \lim_{N \to \infty} (n_i/N)\) 에 대하여 다음과 같이 정의된다.
-
증명
중복도에 대한 (물리학적) 엔트로피는 기본적으로 그것의 로그에 \(1/N\) 를 곱함으로써 다음과 같이 정의된다.
\[ \mathrm{H}=\frac{1}{N}\ln W = \frac{1}{N}\ln N!-\frac{1}{N}\sum_{i}^{}\ln n_i! \]스털링의 근사(Stirling’s approximation)
\[\ln N! \simeq N \ln N - N\]와 \(\lim_{x \to 0} (x \ln x) = 0\) 과 \(\sum_{i}^{}n_i = N\) 를 사용하면 다음을 얻는다.
\[ \begin{equation}\begin{split} \mathrm{H} & \simeq \frac{1}{N}( N \ln N - N ) - \frac{1}{N}\sum_{i}^{}(n_i \ln n_i - n_i) \\ & =\frac{1}{N}( N \ln N ) - \frac{1}{N}\sum_{i}^{}(n_i \ln n_i ) \\ &= \dfrac{\sum_{i}^{}n_i}{N} \cdot \ln N - \frac{1}{N}\sum_{i}^{}(n_i \ln n_i ) \\ & = - \frac{1}{N} \sum_{i}^{}n_i(\ln n_i - \ln N) \\ & = - \sum_{i}^{}\frac{n_i}{N} \ln \left( \frac{n_i}{N} \right)\\ \end{split}\end{equation} \tag*{} \]이때 \(N \to \infty\) 로 보내면 확률의 정의 \(p_i = \lim_{N \to \infty} (n_i/N)\) 에 의하여 다음을 얻는다.
\[ H = - \sum_{i}^{}p_i \ln p_i \]
물리학적으로 물체가 어떤 통에 있는지를 뜻하는 특정 할당을 미시상태(microstate)라고 하고, \(n_i/N\) 으로 나타나는 전체적인 숫자 할당 상태를 거시상태(macrostate)라고 한다. 거시상태에 할당되는 미시상태의 수를 뜻하는 중복도 \(W\) 를 거시상태의 무게(weight)라고 한다.
이 통들을 이산확률변수 \(X\) 의 상태 \(x_i\) 로 해석할 수 있고, 통에 속할 확률을 \(p(X=x_i) = p_i\) 라고 쓸 수 있다. 그러면 확률변수 \(X\) 의 엔트로피는 다음과 같다.
이산 확률 분포의 최대 엔트로피
이산 확률 분포는 균등 분포에서 때 최대 엔트로피를 갖는다.
-
증명
\(p(x_i)\) 의 분포가 몇몇 적은 값들에서 뾰족하게 튀면 엔트로피가 낮고, 많은 값에 완만하게 퍼지면 엔트로피가 높다. 이 현상을 다음 그래프가 보여준다. 다음 그래프는 30개의 통에 대한 두 확률분포를 비교한다. 참고로, 가장 큰 엔트로피는 균등분포에서 \(H = -\ln (1/30) = 3.40\) 이 된다.

\(0 \leq p_i \leq 1\) 이므로 엔트로피는 음이 아니고, 이것의 최소값 \(0\) 은 \(p_i=1\) 이고 나머지 확률이 \(p _{j \neq i} = 0\) 일 때 발생한다. 즉, 모든 것이 확실해서 정보량(불확실성, 놀람의 정도)이 없는 상태이다. 최대 엔트로피는 라그랑주 승수를 사용하여 확률에 정규화 제한을 가하여 얻을 수 있다. 즉, 다음과 같이 \(\mathrm{H}\) 를 최대화할 수 있다.
\[ \tilde{\mathrm{H}} = - \sum_{i}^{}p(x_i)\ln p(x_i) + \lambda \left( \sum_{i}^{}p(x_i) - 1 \right) \tag{2.87} \]이로부터 모든 \(p(x_i)\) 가 같고, 모든 상태 \(x_i\) 의 수 \(M\) 에 대하여 \(p(x_i) = 1/M\) 와 같이 주어진다는 결론을 얻을 수 있다. 그에 따른 엔트로피는 \(\mathrm{H}=\ln M\) 이다.
이 정상점(stationary point)이 최댓값인지 확인하기 위하여 2차 미분이 음수인지 검증하면 된다.
검증하는 것으로도 할 수 있다. 엔트로피의 2차 미분은 항등 행렬의 성분 \(I _{ij}\) 에 대하여 다음과 같이 계산할 수 있다.
\[ \dfrac{\partial \tilde{\mathrm{H}}}{\partial p(x_i)\partial p(x_j)}= - I _{ij}\frac{1}{p_i} \tag{2.88} \]이 값이 모두 음수이므로 정상점은 최댓값이다.
Differential entropy✔
미분 엔트로피(Differential entropy, 연속 확률 변수의 엔트로피)
연속 확률 변수 \(x\) 의 엔트로피를 다음과 같이 정의한다.
여러 연속 변수에 대한 밀도를 벡터 \(\mathbf{x}\) 라고 표기했을 때 미분 엔트로피는 다음과 같다.
-
지금까지 이산확률변수 \(x\) 에 대한 엔트로피를 다뤘는데, 연속 변수 \(x\) 에 대한 분포 \(p(x)\) 대하여 엔트로피의 정의를 확장할 수 있다. 먼저 \(x\) 를 길이 \(\Delta\) 의 구간으로 나눈다. 그리고 \(p(x)\) 가 연속임을 가정하자. 그러면 MVT 는 각 구간에 대하여 다음을 만족하는 값 \(x_i\) 가 \(i \Delta \leq x_i \leq (i+1)\Delta\) 에 존재한다는 것을 보장한다.
\[ \int_{i \Delta }^{(i+1)\Delta }p(x)\mathrm{d}x = p(x_i)\Delta \tag{2.89} \]양자화(quantization)는 연속적인 양을 자연수로 셀 수 있는 양으로 재해석하는 것이다. 이제 우리는 연속 변수 \(x\) 가 \(i\)번째 구간에 속할 때 그것에 임의의 값 \(x_i\) 를 할당하여 \(x\) 를 양자화할 수 있다. \(x_i\) 값을 관찰할 확률은 \(p(x_i)\Delta\) 이다. 그러면 엔트로피는 \((2.89)\) 와 \((2.25)\) 에 의하여 \(\sum_{i}^{}p(x_i)\Delta =1\) 이므로 다음과 같은 형태가 되는 이산 분포가 된다.
\[ \begin{equation}\begin{split} \mathrm{H} _{\Delta}& = - \sum_{i}^{}p(x_i)\Delta \ln (p(x_i)\Delta ) \\ & = - \sum_{i}^{}p(x_i)\Delta \ln p(x_i)-\ln \Delta \\ \end{split}\end{equation} \tag{2.90} \]\(-\ln \Delta\) 는 \(p(x)\) 와 독립이므로 이 항을 제거할 수 있다. 그리고 극한 \(\Delta \to 0\) 을 취할 수 있다. 그러면 첫번째 항은 \(p(x) \ln p(x)\) 의 적분으로 접근하면서 결국 다음이 성립하게 된다.
\[ \lim_{\Delta \to 0} \left\{ - \sum_{i}^{}p(x_i)\Delta \ln p(x_i) \right\} = - \int p(x)\ln p(x)\mathrm{d}x \tag{2.91} \]우항을 미분 엔트로피(differential entropy)라고 한다. 이산 엔트로피와 연속 엔트로피의 형태는 극한 \(\Delta \to 0\) 에서 발산하는 \(\ln \Delta\) 라는 양에서 차이가 난다. 이는 연속 변수를 매우 정확하게 특정하려면 매우 큰 수의 비트가 필요함을 의미한다.
여러 연속 변수에 대한 밀도를 벡터 \(\mathbf{x}\) 라고 표기했을 때 미분 엔트로피는 다음과 같다.
\[ \mathrm{H}[\mathbf{x}] = - \int p(\mathbf{x})\ln p(\mathbf{x})\mathrm{d}\mathbf{x} \tag{2.92} \]
Maximum entropy✔
이산 분포에서 최대 엔트로피는 균등 분포에서 나타난다는 것을 살펴보았다. 연속 변수에서는 어떤지 살펴보자.
연속 확률 변수의 최대 엔트로피
연속 확률 변수는 가우스 분포에서 최대 엔트로피를 갖는다.
-
그래서 자연 상태의 샘플을 적절하게 취하면 항상 정규 분포가 나온다. 가장 엔트로피가 큰 연속 분포가 정규 분포이기 때문이다.
-
증명
이 최댓값은 다음과 같은 정규화 제한을 보존하면서 구해져야 한다.
\[ \int_{- \infty}^{\infty}p(x)\mathrm{d}x=1 \tag{2.93} \]\[ \int_{- \infty}^{\infty}xp(x)\mathrm{d}x=\mu \tag{2.94} \]\[ \int_{- \infty}^{\infty}(x-\mu )^{2}p(x)\mathrm{d}x=\sigma ^{2} \tag{2.95} \]이 제한된 최대화는 라그랑주 승수에 의하여 수행된다. 즉, 다음의 범함수를 \(p(x)\) 에 대하여 최대화하면 된다.
\[ \begin{equation}\begin{split} &- \int_{- \infty}^{\infty}p(x)\ln p(x)\mathrm{d}x + \lambda _1 \left( \int_{- \infty}^{\infty}p(x)\mathrm{d}x - 1 \right) \\ & \qquad + \lambda _2 \left( \int_{- \infty}^{\infty}xp(x)\mathrm{d}x - \mu \right) +\lambda _3 \left( \int_{- \infty}^{\infty}(x - \mu )^{2}p(x)\mathrm{d}x - \sigma ^{2} \right)\\ \end{split}\end{equation} \tag{2.96} \]변분법을 사용하여 이 범함수를 \(0\) 으로 잡으면 다음과 같은 해를 얻는다.
\[ p(x) = \exp \left\{ -1+\lambda _1+\lambda _2x+\lambda _3(x-\mu )^{2} \right\}\tag{2.97} \]이 결과를 재치환하면 3가지 제한에 대한 라그랑주 승수도 구할 수 있다. 그러면 다음과 같은 최종 결과를 얻는다.
\[ p(x) = \dfrac{1}{(2 \pi \sigma ^{2})^{1/2}}\exp \left\{ - \dfrac{(x-\mu )^{2}}{2 \sigma ^{2}} \right\} \tag{2.98} \]즉, 미분 엔트로피를 최대화하는 분포는 가우스 분포이다. 엔트로피를 최대화할 때 분포가 음이 아니게 되도록 제한하지 않았다. 그러나 결과 분포가 음이 아니기 때문에 그러한 제한이 필요없다는 것을 알 수 있다.
가우스 분포의 미분 엔트로피
가우스 분포의 미분 엔트로피를 구하면 다음과 같다.
- 따라서 가우스 분포가 넓어질수록, 즉, 분산 \(\sigma ^{2}\) 가 증가할수록 엔트로피가 올라간다. 이 결과는 \(\sigma ^{2} < 1 / (2 \pi e)\) 에 대하여 \((2.99)\) 에서 \(\mathrm{H}(x) < 0\) 이므로 이산 엔트로피와는 달리 미분 엔트로피가 음이 될 수 있다는 것을 의미한다.
Kullback–Leibler divergence✔
쿨백-라이블러 발산(Kullback-Leibler divergence, 상대적 엔트로피, relative entropy)
알 수 없는 분포 \(p(\mathbf{x})\) 를 모델링하기 위하여 근사 분포 \(q(\mathbf{x})\) 를 사용한다고 가정하자. \(q(\mathbf{x})\) 를 사용하여 \(\mathbf{x}\) 의 값을 전달하기 위한 코드 체계를 구성한다면, 진짜 분포 \(p(\mathbf{x})\) 대신 \(q(\mathbf{x})\) 를 사용하여 \(\mathbf{x}\) 값을 특정하는데에 요구되는 추가적인 정보량의 평균은 다음과 같다.
이를 분포 \(p(\mathbf{x})\) 와 \(q(\mathbf{x})\) 사이의 쿨백-라이블러 발산이라고 한다.
- 이는 비대칭적이라 \(\operatorname{KL}(p\|q)\neq \operatorname{KL}(q\|p)\) 이다.
볼록 함수(convex function), 오목 함수(concave function)
볼록 함수는 모든 현(chord)이 함수 위에 있는 함수이다. 이러한 함수 \(f\) 의 볼록성(convexity)을 다음과 같이 정의할 수 있다.
이때, 엄격하게 볼록(strictly convex)인 함수를 등식이 오직 \(\lambda =0\) 와 \(\lambda =1\) 에 대하여 성립하는 함수로 정의한다.
현이 함수 아래에 존재한다면 오목 함수라고 하고, 그에 따른 엄격한 오목(strictly concave)의 정의도 정의된다. 함수 \(f(x)\) 가 볼록이면 \(-f(x)\) 는 오목이다.
-
이는 함수의 2계도 미분이 항상 양수인 것과 동일하다. 실제로 다음 그림처럼 볼록 함수는 어느쪽으로 가든 증가하므로 2계도 미분이 항상 미분인 것이다.
-
예시
\(x>0\) 에 대한 함수 \(x \ln x\) 와 \(x ^{2}\) 는 볼록이다.
-
예시

젠슨의 부등식(Jensen's inequality)
볼록 함수 \(f(x)\) 가 임의의 점 집합 \(\{x_i\}\) 에 대한 \(\lambda _i \geq 0\) 와 \(\sum_{i}^{}\lambda _i=1\) 에 대하여 다음을 만족한다.
연속 변수에서 젠슨의 부등식은 다음과 같다.
-
증명
수학적 귀납법을 사용하면 \((2.101)\) 로부터 볼록 함수 \(f(x)\) 가 임의의 점 집합 \(\{x_i\}\) 에 대한 \(\lambda _i \geq 0\) 와 \(\sum_{i}^{}\lambda _i=1\) 에 대하여 다음을 만족한다는 것을 보일 수 있다.
\[ f \left( \sum_{i=1}^{M}\lambda _ix_i \right) \leq \sum_{i=1}^{M}\lambda _if(x_i) \tag*{■}\]
\(p(\mathbf{x}) = q(\mathbf{x})\) 인 것은 \(\operatorname{KL}(p\|q)=0\) 인 것과 동치이다.
-
이 정리에 의하여 쿨백-라이블러 발산을 두 분포 \(p(\mathbf{x})\) 와 \(q(\mathbf{x})\) 가 서로 얼마나 다른지의 측정으로 해석할 수 있다.
-
증명
볼록 함수 \(f\) 를 잡자. \(x=a\) 에서 \(x=b\) 의 구간 안의 모든 값 \(x\) 는 \(0 \leq \lambda \leq 1\) 에 대하여 \(\lambda a + (1-\lambda )b\) 로 쓸 수 있다. 현에 대응되는 점은 \(\lambda f(a) + (1-\lambda )f(b)\) 로 주어지며, 그에 따른 함수의 값은 \(f(\lambda a+(1-\lambda )b)\) 이다.
젠슨의 부등식
\[ f \left( \sum_{i=1}^{M}\lambda _ix_i \right) \leq \sum_{i=1}^{M}\lambda _if(x_i) \]에 대하여 \(\lambda_i\) 를 값 \(\{x_i\}\) 을 취하는 이산 변수 \(x\) 에 대한 확률 변수로 해석하면 이를 기댓값 \(\Bbb{E}[\cdot ]\) 에 대하여 다음과 같이 쓸 수 있다.
\[ f \left( \Bbb{E}[x] \right) \leq \Bbb{E}[f(x)] \tag{2.103} \]정규화 조건 \(\int q(\mathbf{x})\mathrm{d}\mathbf{x}=1\) 과 \(- \ln x\) 가 볼록 함수라는 사실을 사용하여 연속 변수의 젠슨의 부등식을 쿨백-라이블러 발산 \((2.100)\) 에 적용하면 다음을 얻는다.
\[ \operatorname{KL}(p\|q) = - \int p(\mathbf{x})\ln \left\{ \dfrac{q(\mathbf{x})}{p(\mathbf{x})} \right\}\mathrm{d}\mathbf{x}\geq - \ln \int q(\mathbf{x})\mathrm{d}\mathbf{x}=0 \tag{2.105} \]그런데 \(- \ln x\) 는 엄격한 볼록 함수이므로 등식이 성립하는 것은 모든 \(\mathbf{x}\) 에 대하여 \(q(\mathbf{x})=p(\mathbf{x})\) 과 동치이다. ■
데이터 압축과 밀도 추정은 연관되어 있다.
- 데이터 압축(가령, 텍스트 요약, 영화 내용 정리, 뉴스 기사 브리핑 등)과 밀도 추정(알려지지 않은 확률 분포의 모델링 문제)은 서로 연관되어 있다. 왜냐하면 가장 효율적인 압축이란 곧 데이터를 생성하는 참된 분포에 대한 지식으로부터 나오기 때문이다. 참된 분포를 모르기 때문에 비효율적인 코드 체계가 필요하고, 최소한 두 분포 사이의 쿨백-라이블러 발산과 같은 추가적인 평균 정보량이 전달되어야 한다.
쿨백-라이블러 발산의 최소화는 음의 우도 함수의 최대화와 동치이다.
-
이렇게 두 엔트로피의 동기화 또한 확률 분포에서의 최적화 접근법과 동치라는 것을 보인 것이다. 즉, 기계학습의 의미와 정당성을 수학의 다양한 관점으로부터 증명해보이는 것이다.
-
증명
데이터를 생성하는 알려지지 않은 분포 \(p(\mathbf{x})\) 를 모델링하는 문제를 생각하자. 그러면 조정가능한 파라미터화된 분포 \(q(\mathbf{x}|\bm{\theta})\) 를 사용하여 이 분포를 근사해야 한다. \(\bm{\theta}\) 를 판정하는 한 가지 방법은 \(p(\mathbf{x})\) 과 \(q(\mathbf{x}|\bm{\theta})\) 사이의 쿨백-라이블러 발산을 최소화하는 것이다. 하지만 \(p(\mathbf{x})\) 를 모르기 때문이 이 최소화를 직접 수행할 수 없다. 그러나 \(n=1,\dots ,N\) 에 대한 유한한 훈련 데이터 \(\mathbf{x}_n\) 를 \(p(\mathbf{x})\) 로부터 관찰했다고 가정한다면, 이 훈련 데이터의 유한한 합에 의하여 \((2.40)\) 을 사용하여 \(p(\mathbf{x})\) 에 대한 기댓값을 다음과 같이 근사할 수 있다.
\[ \operatorname{KL}(p\|q) \simeq \frac{1}{N}\sum_{n=1}^{N}\left\{ -\ln q(\mathbf{x}_n|\bm{\theta}) + \ln p(\mathbf{x}_n) \right\} \tag{2.106} \]우변의 2번째 항은 \(\bm{\theta}\) 에 독립이고, 첫번째 항은 훈련 셋에 대한 분포 \(q(\bf{x}|\bm{\theta})\) 에 대하여 계산된 \(\bm{\theta}\) 에 대한 음의 우도 함수이다. 따라서 쿨백-라이블러 발산의 최소화는 음의 우도 함수의 최대화와 동치이다. ■
Conditional entropy✔
조건부 엔트로피(conditional entropy)
변수 \(\mathbf{x}\) 와 \(\mathbf{y}\) 사이의 결합분포 \(p(\mathbf{x},\mathbf{y})\) 를 잡자. 이 결합분포로부터 \(\mathbf{x}\) 와 \(\mathbf{y}\) 의 값을 추출할 수 있다. \(\mathbf{x}\) 의 값이 주어지면 \(\mathbf{y}\) 의 값을 특정하기 위한 추가 정보 \(- \ln p(\mathbf{y}|\mathbf{x})\) 가 필요하다. 따라서 \(\mathbf{y}\) 를 특정하기 위한 추가적인 정보량의 평균은 다음과 같다.
이를 주어진 \(\mathbf{x}\) 에 대한 \(\mathbf{y}\) 의 조건부 엔트로피(conditional entropy)라고 한다.
-
곱의 규칙에 의하여 \(p(\mathbf{x},\mathbf{y})\) 의 미분 엔트로피 \(\mathbf{H}[\mathbf{x},\mathbf{y}]\) 와 주변 분포 \(p(\mathbf{x})\) 의 미분 엔트로피 \(\mathbf{H}[\mathbf{x}]\) 에 대하여 다음이 성립한다.
\[ \mathbf{H}[\mathbf{x},\mathbf{y}] = \mathbf{H}[\mathbf{y}|\mathbf{x}] + \mathbf{H}[\mathbf{x}] \tag{2.108} \]따라서 \(\mathbf{x}\) 와 \(\mathbf{y}\) 를 설명하기 위하여 필요한 정보는 \(\mathbf{x}\) 를 단독으로 설명하기 위하여 필요한 정보와 주어진 \(\mathbf{x}\) 에 대하여 \(\mathbf{y}\) 를 특정하기 위하여 필요한 정보의 합이다.
Mutual information✔
상호 정보(mutual information)
두 변수 \(\mathbf{x}\) 와 \(\mathbf{y}\) 가 독립일 때, 이들의 결합분포는 \(p(\mathbf{x},\mathbf{y}) = p(\mathbf{x})p(\mathbf{y})\) 와 같다. 그러나 독립이 아니라면, 독립에 얼마나 가까운지를 다음과 같은 결합분포와 주변분포의 곱 사이의 쿨백-라이블러 발산으로 계산할 수 있다.
이를 변수 \(\mathbf{x}\) 와 \(\mathbf{y}\) 사이의 상호 정보라고 한다.
-
쿨백-라이블러 발산의 성질에 의하여 \(\mathbf{I}[\mathbf{x},\mathbf{y}] \geq 0\) 이고, \(\mathbf{I}[\mathbf{x},\mathbf{y}]=0\) 는 \(\mathbf{x}\) 와 \(\mathbf{y}\) 가 독립인 것과 동치이다.
-
합과 곱의 규칙에 의하여 다음이 성립한다.
\[ \mathbf{I}[\mathbf{x},\mathbf{y}] = \mathbf{H}[\mathbf{x}]-\mathbf{H}[\mathbf{x}|\mathbf{y}] = \mathbf{H}[\mathbf{y}] - \mathbf{H}[\mathbf{y}|\mathbf{x}]\tag{2.110} \]따라서 상호 정보는 \(\mathbf{y}\) 의 값을 알려줌으로써 감소하는 \(\mathbf{x}\) 의 불확실성을 표현한다. 베이지안 관점에서는 \(p(\mathbf{x})\) 는 \(\mathbf{x}\) 에 대한 사전 분포이고, \(p(\mathbf{x}|\mathbf{y})\) 는 새로운 데이터 \(\mathbf{y}\) 를 관찰한 이후의 사후 분포이다. 따라서 상호 정보를 새로운 관찰 \(\mathbf{y}\) 의 결과로 감소되는 \(\mathbf{x}\) 의 불확실성이라고 할 수 있다.
Bayesian Probabilities✔
접힌 동전의 예시에서 동전이 앞면으로 접혀있는지 뒷면으로 접혀있는지 모르는 상태라면, 동전을 던졌을 때 앞면으로 떨어질 확률과 뒷면으로 떨어질 확률을 각각 \(50\%\) 라고 가정할 수밖에 없다. 이것은 일반화된 확률, 즉, 베이지안 확률이 확률을 불확실성의 양으로 정의하는 것과 같다. 그러나 동전이 던져진 몇가지 결과가 주어진다면, 가령, 뒷면이 더 자주나왔다면, 우리는 동전이 앞면으로 접혀있다고 생각할 수 있다. 그리고 점점 더 동전이 뒷면으로 떨어질 확률을 높다고 생각할 수 있다.
이런 식의 직관은 옳으며, 이런 식의 추론을 베이즈 정리로 정형화할 수 있다. 이때 베이즈 정리는 새로운 의미를 갖게 된다. 왜냐하면 베이즈 정리가 동전의 앞면이 오목할(접혀있을) 사전 확률을 동전이 던져진 결과의 데이터와 통합되어 사후 확률로 변환해주기 때문이다. 이 과정은 반복되고, 결국 사후 확률이 동전 던지기 데이터가 통합된 사전 확률이 된다.
사전 지식의 포함은 자연스럽게 발생한다. 가령, 편향되지 않아 보이는 동전을 3번 던졌을 때 모두 앞면이 나왔다면, 앞면이 나올 확률의 최대 우도 추정은 \(1\) 이 되며, 이는 미래에 던져질 모든 동전이 앞면이 될 것이라는 예측이다. 그러나 베이지안적 접근에서 합리적인 사전지식이 포함되면 이런 극단적인 결과가 나오지 않는다.
Model parameters✔
사인 곡선 회귀를 예시로 기계학습의 몇가지 통찰을 베이지안 접근을 통하여 얻어보자. 훈련 데이터 셋을 \(\mathcal{D}\) 라고 하자. 선형 회귀 문제에서 파라미터가 최대 우도법을 사용하여 선택될 수 있다는 것을 이미 알아보았다. 즉, 최대 우도법에서 우도 함수 \(p(\mathcal{D}|\mathbf{w})\) 를 최대화하는 값의 집합 \(\mathbf{w}\) 로 파라미터가 선택된다. 기계학습에서 음의 로그 우도 함수를 에러 함수라고 한다. 음의 로그는 단조 감소 함수이므로 우도의 최대화는 에러의 최소화와 같기 때문이다. 에러의 최소화를 통하여 파라미터 값을 특정할 수 있는데, 이를 \(\mathbf{w}_{\text{ML}}\) 라고 표기한다. 이 파라미터로 새로운 데이터에 대한 예측을 수행하게 된다.
훈련 데이터 셋을 다르게 선택하면 각기 다른 해 \(\mathbf{w}_{\text{ML}}\) 를 얻는다. 베이지안 접근법에서 우리는 모델 파라미터에 있는 불확실성을 확률론으로 설명할 수 있다. 먼저 데이터를 관찰하기 전에 \(\mathbf{w}\) 에 대한 가정을 사전 확률 분포 \(p(\mathbf{w})\) 로 포착할 수 있다. 관찰된 데이터 \(\mathcal{D}\) 의 효과는 우도 함수 \(p(\mathcal{D}|\mathbf{w})\) 를 통하여 표현되고, 다음과 같은 형태의 베이즈 정리가 사후확률 \(p(\mathbf{w}|\mathcal{D})\) 을 통하여 데이터 \(\mathcal{D}\) 를 관찰한 이후의 \(\mathbf{w}\) 의 불확실성을 측정해준다.
\(p(\mathcal{D}|\mathbf{w})\) 를 파라미터 벡터 \(\mathbf{w}\) 의 함수로 볼 때 이것은 우도 함수가 되고, 이것으로 관찰된 데이터 셋이 각기 다른 \(\mathbf{w}\) 의 값에 대하여 얼마나 가능성이 있는지 표현할 수 있다. 이때, 우도 함수 \(p(\mathcal{D}|\mathbf{w})\) 는 \(\mathbf{w}\) 에 대한 확률분포가 아니고, 이것의 \(\mathbf{w}\) 에 대한 적분은 \(1\) 일 필요는 없다.
우도의 정의에 대하여 베이즈 정리를 다음과 같이 말할 수 있다. 이때 다음의 3가지 양들은 모두 \(\mathbf{w}\) 에 대한 함수이다.
\((2.111)\) 의 분모는 사후 분포(좌항)가 확률 밀도로써의 조건을 만족시켜주고 적분이 \(1\) 이 되게 하는 정규화 항이다. 사실, \((2.111)\) 의 양변을 \(\mathbf{w}\) 에 대하여 적분함으로써 사전 확률과 우도 함수에 대하여 베이즈 정리의 분모를 다음과 같이 표현할 수 있다.
베이지안 주의와 빈도주의 모두에서 우도 함수 \(p(\mathcal{D}|\mathbf{w})\) 는 핵심 역할을 한다. 그러나 우도 함수가 사용되는 방식은 근본적으로 다르다. 빈도주의 세팅에서 \(\mathbf{w}\) 는 고정된 파라미터이고, 그것의 값은 추정기(estimator)의 형태에 의하여 판정되며, 이 추정에 대한 에러는 가용한 데이터 셋 \(\mathcal{D}\) 의 분포를 고려함으로써 판정된다. 반면 베이지안 관점에서 데이터셋 \(\mathcal{D}\) 는 유일하며(실제로 관찰된 한 가지 데이터셋), 파라미터의 불확실성은 \(\mathbf{w}\) 에 대한 확률분포를 통하여 표현된다.
Regularization✔
사인 곡선 회귀 예시에서 과적합을 없애기 위한 정규화 기술을 베이지안 관점에서 이해해보자. \(\mathbf{w}\) 에 대한 우도 함수를 최대화함으로써 모델 파라미터를 선택하는 대신 사후 확률 \((2.111)\) 을 최대화할 수 있다. 이를 최대 사후 추정(maximum a posteriori estimate, MAP estimate)이라고 한다. 마찬가지로, 사후 확률의 음의 로그를 최소화할 수 있다. \((2.111)\) 의 양변에 음의 로그를 취하면 다음을 얻는다.
\((2.114)\) 의 우변의 첫번째 항은 보통의 로그 우도이고, 세번째 항은 \(\mathbf{w}\) 에 종속이 아니므로 제거 가능하다. 두번째 항은 \(\mathbf{w}\) 에 대한 함수이며, 로그 함수에 더해진 것이고, 이를 정규화 항으로 이해할 수 있다.
좀 더 명확하게 하기 위하여, 사전 분포 \(p(\mathbf{w})\) 를 서로 독립인 평균이 \(0\) 인 가우스 분포의 합이 되도록 선택했다고 하자. \(\mathbf{w}\) 의 각 원소들은 같은 분산 \(s ^{2}\) 를 가지며, 다음을 만족한다.
\((2.114)\) 에 치환하면 다음을 얻는다.
\((2.66)\) 같은 로그 우도를 갖는 선형 회귀 모델의 특별한 케이스를 생각한다면, 사후 확률의 최대화는 다음 함수의 최소화와 같다.
이 형태는 \((1.4)\) 에서 이미 살펴보았던 정규화된 오차제곱합 에러 함수의 형태와 같다.
Bayesian machine learning✔
베이지안 접근을 통하여 정규화 항을 도출해낼 수 있었다. 그러나 베이즈 정리를 단독으로 사용하는 것으로는 기계학습에서 베이지안 접근을 참되게 사용할 수 없다. 왜냐하면 이것이 \(\mathbf{w}\) 에 대한 단일 해를 찾는 것이고, 따라서 \(\mathbf{w}\) 의 값의 불확실성을 다루지 않기 때문이다. 훈련 데이터 셋 \(\mathcal{D}\) 를 잡고, 주어진 새로운 입력 \(x\) 에 대한 타겟 변수 \(t\) 를 예측하는 것이 목표라고 해보자. 그러므로 우리가 관심있는 것은 주어진 \(x\) 와 \(\mathcal{D}\) 에 대한 \(t\) 의 분포이다. 합과 곱의 규칙에 의하여 다음을 얻는다.
예측은 \(\mathbf{w}\) 의 모든 가능한 값에 대한 가중치화된 평균(기댓값) \(p(t|x, \mathbf{w})\) 에 의하여 얻어진다. \(\mathbf{w}\) 에 가중치를 부여하는 함수(weighting function)는 사후 확률 분포 \(p(\mathbf{w}|\mathcal{D})\) 에 의하여 주어진다. 베이지안 방법을 구별하는 핵심 차이는 이 파라미터 공간에 대한 적분이다. 반면, 빈도주의 방법은 정규화된 오차제곱합 같은 에러 함수의 최적화에 의하여 얻어지는 파라미터에 대한 점추정을 사용한다.
이 베이지안 기계학습은은 중요한 통찰을 제공한다. 가령, 과적합 문제는 최대 우도를 사용함으로써 나타나는 병리적 예시이고, 베이지안 접근을 사용하여 파라미터를 주변화시키면 발생하지 않는다. 비슷하게, 회귀 문제에서 서로 다른 차수를 갖는 다항식들 같이 문제를 해결하는 다양한 잠재 모델을 가질 수 있다. 최대 우도 접근은 단순히 데이터의 가장 높은 확률을 제공하는 모델을 골라준다. 그러나 이 방식은 더 복잡한 모델을 선택하게 되고 과적합으로 이어진다.
완전한 베이지안 접근에는 모든 가능한 모델에 대한 평균을 내는 것도 포함된다. 이때 각 모델의 기여도는 그것의 사후 확률에 의하여 가중된다. 또한, 이 확률은 보통 중간 정도의 복잡성 모델에서 가장 높다. 낮은 차수의 다항식 같은 간단한 모델은 그들이 데이터에 잘 피팅되지 못하므로 낮은 확률을 갖고, 높은 차수의 다항식 같은 복잡한 모델도 파라미터에 대한 베이지안 적분이 복잡성에 패널티를 부여하기 때문에 낮은 확률을 갖는다. 베이지안 접근이 기계 학습에 적용되는 더 자세한 설명은 『Pattern Recognition and Machine Learning (Bishop, 2006)』 에 있다.
베이지안 프레임워크의 주된 단점은, 파라미터 공간에 대한 적분을 포함하는 \((2.118)\) 에서 드러난다. 현대 딥러닝 모델은 수백만, 수십억개의 파라미터를 갖기 때문에 그러한 적분의 간단한 근사마저도 불가능하기 때문이다. 사실, 주어진 제한된 컴퓨팅 예산과 풍부한 훈련 데이터에 대하여 큰 신경망에 하나 이상의 정규화가 적용된 최대 우도법을 적용하는 것이 작은 모델에 베이지안 접근을 적용하는 것보다 보통 더 낫다.